

Full Force by Jetfreak-7
В облаке может умереть гипервизор и потеряться состояние памяти. И когда дело дойдет до восстановления данных, в памяти, скорее всего, ничего не останется. Поэтому самое главное в виртуальной машине — это диски и наличие консистентных резервных копий. А вот чтобы эти копии создавались быстро, приходится поплясать с бубном.
Привет, я Артемий Капитула, ведущий программист в команде разработки Compute и Storage VK Cloud Solutions. Сегодня я расскажу вам, как мы модернизировали архитектуру бэкапов на базе OpenStack в публичном облаке и ускорили их создание в 10 раз.
13 и 14 мая в Москве на площадке в Крокус-Экспо пройдет конференция Highload++ Foundation 2022. Описание докладов и расписание уже готовы. Билеты можно купить на сайте.
В программе будут и актуальные на сегодня темы: от импортозамещения, новой инфраструктурной парадигмы до построения карты рисков, перестройки офисной инфраструктуры и безопасности с резким ростом нагрузки в условиях рисков по железу.
Как вообще выглядит нагрузка на ресурсы при создании бэкапов
Почему вообще речь зашла о бэкапах, если в контексте облака принято говорить скорее о резервировании? Дело в том, что резервирование, репликация и дублирование данных направлены на защиту от отказа одного узла. Но когда случается ошибка — именно «когда», а не «если», — данные повреждаются синхронно на всех репликах. И вам ничего не остается, кроме как идти за бэкапом. Поэтому необходимость делать резервные копии совершенно ортогональна необходимости реплицировать сервисы.
Задача резервного копирования кажется простой, но в реальности она очень ресурсоемкая. Каждый раз, когда вы делаете резервную копию, вы поднимаете огромный объем данных и нагружаете диски и сеть. Затем вы эти данные обрабатываете: рассчитываете контрольные суммы, находите различия, сжимаете, упаковываете и так далее. Это очень серьезно нагружает память и процессор. На третьей стадии вы перекладываете созданный бэкап на «холодное» хранение. Это снова нагружает сеть и диски.
У нас есть клиенты, которых это не особенно затрагивает, — те, кто перешел на стек Cloud Native. У них, как правило, вычислительные узлы Stateless, а весь необходимый State лежит во внешних сервисах: объектном хранилище, базах данных как сервисах и т. д. В их случае для бэкапа используют инструмент, на котором построен соответствующий сервис. Например, если очередь сообщений сделана на Kafka, то и бэкапим средствами Kafka. Если база данных PostgreSQL aaS — то средствами PostgreSQL. А балансировщики даже не надо бэкапить, их можно просто реинстанцировать.
Но есть и вторая группа клиентов — те, кто используют Legacy-стек. Они сами конфигурируют всю инфраструктуру, балансировщики, сервисы очередей, базы. Вся инфраструктура у них построена внутри виртуальных машин, поэтому ресурсы нуждаются в резервном копировании. Эта группа клиентов потребляет примерно столько же ресурсов, сколько первая.
Теперь немного цифр. Резервное копирование в VK Cloud Solutions на практике — это примерно 500 ТБ в сутки, около 15 ПБ в месяц. Система хранения за сутки фактически считывает 300–350 ТБ в сутки, все остальное — тонкие вольюмы. Нагрузка каждый год вырастает примерно вдвое, при этом все хотят инкрементальные бэкапы и их сжатие, хотя не везде инкрементальное сжатие может быть эффективно, особенно когда речь идет о мультимедийных данных.
Существенный объем этих данных необходимо бэкапить очень быстро, потому что из-за нагрузки на инфраструктуру проседает общая производительность. И если клиент работает по верхней кромке выделенных ему ресурсов, то просадка может приводить к сбоям в обслуживании. Поэтому резервное копирование мы делаем ночью, с 11 вечера до 6 утра. В это время у нас стонут диски и сеть, звенят алерты о пике потребления ресурсов, но это нормально.
Какие еще есть ограничения и сложности
Одно из самых слабых мест всей инфраструктуры резервного копирования — это, конечно, диски. Есть две категории дисков, на которые мы бэкапим:
- Преаллоцированные диски High-IOPS — быстрые, с отказоустойчивостью на уровне диска (доступность сохраняется при отказе диска, но не сервера). Их используют под базы данных и систему.
- Тонкие диски (Ceph) более медленные и несколько более дешевые. На них клиенты хранят данные, но задержка отзыва может выходить за рамки 10 миллисекунд (например, для Ceph HDD, используемого многими для хранения «холодных» данных).
Если преаллоцированные диски просто подключаешь к гипервизору и они работают и видны именно как диски (iSCSI), то Ceph-диски операционная система зачастую не подключает, поэтому бэкапить их приходится через User-Space-компоненты и клиентские библиотеки Ceph, а это медленно.
По задержке во времени обслуживания у нас есть диски разных классов. Одни — установленные непосредственно в гипервизоры — имеют задержку от 100 микросекунд,. Другие имеют задержку в 0,3–0,5 миллисекунды. Наконец, самые медленные (но и самые дешевые) диски, которые хорошо подходят для хранения массива данных, — SSD и HDD под управлением Ceph. Для них задержка может составлять десяток миллисекунд, это ограничение платформы.
Состояние диска — подключен он к ВМ или нет, включена ВМ или нет — также влияет на процессы резервного копирования.
Самый простой случай — это офлайн-диск (не подключенный к ВМ). Мы берем его и копируем поблочно в резервную копию. При этом можно выполнять какие-то дополнительные операции, например сжимать или считать дельту.
Второй вариант — диск, который подключен к виртуальной машине. Ведь если забэкапить диск, на который идет запись, то после его восстановления данные абсолютно непригодны для использования. В таких случаях мы делаем снэпшот диска и читаем данные уже из него.
Третий сценарий, самый сложный — когда в виртуальной машине несколько дисков и надо сделать консистентный снэпшот. Здесь начинаются проблемы. Допустим, есть база данных, которая лежит на двух дисках. Снимки каждого диска будут сделаны в разное время, и файлы данных на разных дисках будут различаться. Такая копия окажется непригодна к использованию.
Для решения проблемы можно использовать агенты в гостевой операционной системе. В качестве гипервизоров мы применяем Linux с QEMU. Соответственно, внутри виртуалок у нас гостевой агент QEMU, который может сделать Freeze, то есть остановить ввод/вывод на диске на время создания снэпшота. После этого дисковые операции размораживаются, работа восстанавливается. Все это средствами операционной системы: Shadow Copy Provider в Windows, fsfreeze в Linux.
Еще одна очень жесткая задача — это уложиться во временное окно. Выше я уже упомянул, что у нас относительно небольшое окно на создание резервных копий, всего 6–8 часов. Однако диски у клиентов могут быть существенного объема. Если бэкапить диск объемом 4 ТБ на скорости 30 МБ/с, на это уходит почти два дня, что неприемлемо. Мы посчитали, что получим достаточный запас, если ускорим бэкапы примерно в 10 раз — с 15–50 МБ/с до 370 МБ/с.
Первый подход к снаряду: параллельные потоки в драйвере
В первую очередь мы попробовали решить вопрос с помощью уже используемых технологий. Для этого пришлось разобрать схему создания резервных копий с самого начала.
В природе существуют три основные схемы бэкапа:
- Поблочное копирование на offline-диск. Данные заливают в резервную копию с помощью простой операции. При этом можно выполнять дополнительные операции: сжатие, расчет контрольной суммы, различные преобразования.
- Копирование через снимок диска. Нельзя остановить диск, на котором работает виртуальная машина, чтобы сделать резервную копию. Поэтому делают снэпшот диска и данные переносят уже из него.
- Через агенты в гостевой ОС. Если у вас есть база данных на нескольких дисках, последовательно сделанные снимки дадут вам неконсистентную резервную копию, поскольку файлы на них будут «заморожены» в разное время. В VK Cloud Solutions мы используем гипервизор QEMU для Linux, гостевые клиенты которого могут остановить ввод-вывод на дисках до момента, пока создание снимков не завершится успешно. В Windows используем Shadow Copy Provider, в Linux — системный вызов fsfreeze.
Мы использовали комбинацию из первых двух способов в зависимости от ситуации: менеджер резервных копий Karbor и подсистему бэкапов Cinder.
Общая схема работы Karbor выглядит так:
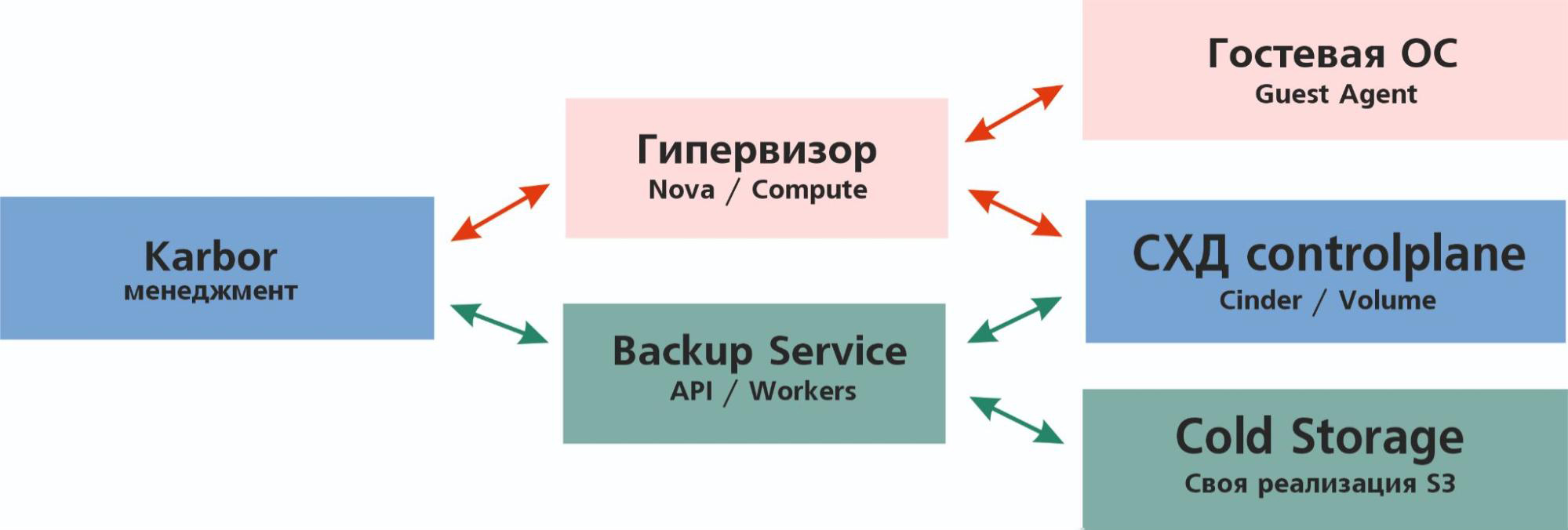
Karbor отправляет на гипервизор задание подготовить снимок виртуальной машины. Гипервизор запрашивает у гостевого агента остановку дисковых операций, после чего заходит на Controlplane системы хранения и командует сделать снимок дисков VM.
Система хранения данных (СХД) делает снимки и сообщает об их готовности. Гипервизор командует гостевой ОС разморозить дисковые операции и радостно докладывает Karbor, что появился снимок виртуальной машины с набором снимков дисков и можно двигаться дальше. Затем Karbor отправляет в Backup API инструкцию: «Сделать бэкапы этих дисков, используя эти снимки».
Backup API отправляет инструкцию исполнителям (воркерам), те подключают к себе снимки из системы хранения, считывают данные, преобразуют их и загружают в холодное хранилище (Cold Storage).
В этой цепочке проблемы чаще всего возникают на этапе между гипервизором и гостевой ОС, когда гостевой агент QEMU по каким-то причинам отказывается или не может заморозить ввод-вывод. Но мы с такими проблемами, как правило, не сталкивались, поэтому принялись оптимизировать другой участок — между Backup API и холодным хранилищем, то есть Cinder. Работает он следующим образом: запрос на бэкап приходит в API, подготовительные процессы перед бэкапом обрабатывают в Manager, Driver вычитывает данные с диска и записывает их на холодное хранение.
Штатно в OpenStack есть набор драйверов резервного копирования в различные системы долговременного хранения: Tivoli, Ceph, NFS/Posix FS, Gluster, Google Cloud. Однако мы использовали драйвер собственной разработки. Он выполнял резервное копирование в S3-хранилище VK Cloud Solutions, но в нем не работали дифференциальные бэкапы. Сначала пришлось поработать с кодом драйвера, чтобы решить проблемы со скоростью бэкапов и инкрементальными бэкапами.
Для начала мы посмотрели, как выглядит вызов драйвера внутри фреймворка. Вот он:
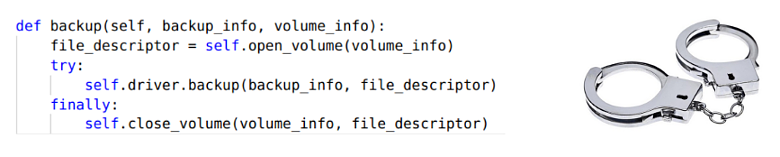
Здесь в менеджер передается информация о томе и бэкапе, который мы хотим сделать, после чего вызывается процедура открытия этого тома. На выход передается сущность, из которой можно читать, но она не является полноценным файловым дескриптором. Этот «дескриптор открытого тома» является потоком с указателем текущей позиции, то есть он поддерживает операции
seek, write и read.Так как эта сущность не является файловым дескриптором в полном смысле слова, к нему невозможно применить системные вызовы
io_submit, selectи
epoll. А значит, резервное копирование невозможно выполнять быстрее, чем чтение в один поток.Поэтому для начала мы реализовали в драйвере параллельное чтение одного потока в двух потоках выполнения: один считывал данные, второй их сжимал, преобразовывал и записывал на холодное хранение. Так удалось ускорить создание резервных копий в 1,5–2 раза: с 15–50 МБ/с до 30–70 МБ/с. Однако нашей целью была скорость 370 МБ/с.
Профилирование
Когда знаешь узкие места системы, становится понятно, что нужно исправить. Поэтому на ранней стадии переписывания драйвера мы написали синтетическое приложение для его тестирования и отпрофилировали его выполнение. Это помогло нам понять, на что тратится время и почему теряется скорость.

Мы увидели, что диск не загружен (крайний правый столбец — 30% нагрузки диска) и есть возможность для роста. Этот «эмулятор драйвера» использует библиотеку сжатия ZLIB и читает блоком по 512 КБ, но запросы на чтение — 128 КБ. Получается, что они «режутся» на уровне ОС.
Чтобы выделить источник проблемы, мы просто убрали сжатие из кода этого теста, оставили только чтения и увидели, что без сжатия скорость доходит до 290 МБ/с, нагрузка почти 100%.
То есть один из источников проблемы — алгоритм сжатия.

Мы заменили компрессию ZLIB на LZ4 и ускорились до 290 МБ/с. Хорошо, но не идеально. До цели в 370 МБ/с мы все еще не добрались.
А что с преаллоцированными дисками?
Следующая задача — разобраться, почему диск не читает большим блоком в 512 КБ. Мы поменяли код тестового приложения еще раз, чтобы читать данные не по 512 КБ, а по 4 МБ. Однако при изучении вывода iostat выяснилось, что диск по-прежнему читает блоком в 128 КБ. Это означало, что ограничение работает на уровне операционной системы.
Фактически при чтении с диска запросы обрабатываются драйвером частями размером
read_ahead килобайт. Значение этой переменной прописано в sysfs в /sys/block/имя_диска/queue/read_ahead_kb. Чтобы избежать ограничения, наложенного блочным стеком, мы рассмотрели два варианта.
Сначала подумали про глобальное увеличение
read_ahead_kb, но быстро отказались от такой идеи: это бы существенно повлияло на случайный ввод-вывод (random I/O). Второй вариант — использование Direct I/O, что мы и сделали.
Пример ниже демонстрирует описанное поведение: размер логического запроса не влияет на размер фактического, если не используется Direct I/O.

Мы сделали
dd из диска в /dev/null Direct I/O блоком 4 МБ и получили average request size размером 512 КБ и скорость чтения 570 МБ/с. Стоп, почему 512 КБ, а не 4 МБ? Дело в том, что диск подключен по iSCSI с максимальным размером запросов 512 КБ. Так что фактически мы достигли ожидаемого результата.
Привет, я Ceph. Помнишь меня?
Проблема с дисками Ceph тем временем никуда не делась: они не видны как диски в хостовой системе и для них нельзя сделать доступ через механизмы Direct I/O. Поэтому мы решили проверить, не надо ли сменить алгоритм.
Для этого провели серию тестов и составили таблицу продолжительности каждого этапа резервного копирования для обоих алгоритмов сжатия (ZLIB и LZ4) и разных типов дисков. В таблице зафиксировано типовое время выполнения соответствующей операции для 1 ГБ данных.
Это позволяет определить минимальную продолжительность резервного копирования, просто сложив соответствующие значения и умножив на размер диска.
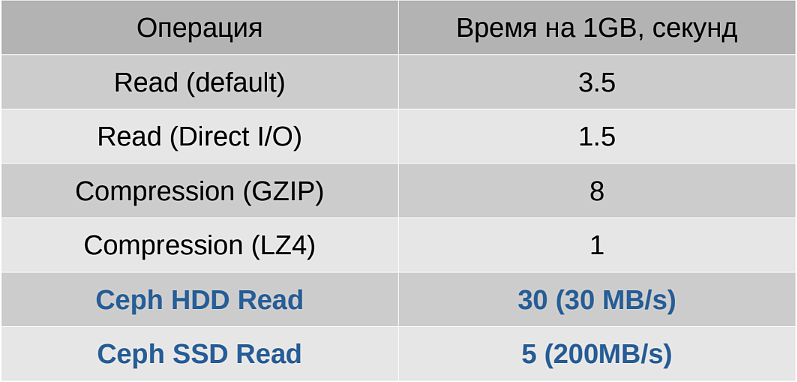
По итогам мы выяснили, что бэкап 1 ГБ данных занимает не меньше 30 секунд для Ceph HDD и не меньше 5 секунд для Ceph SSD вне зависимости от выбранного алгоритма сжатия.
Дальнейшая оптимизация невозможна, поскольку файловый объект приходит уже открытым, из него нельзя читать даже в параллельном режиме. Что это значит? Самое время все сломать!
Новая архитектура
Поскольку мы решили полностью переработать архитектуру, изменения затронули практически все аспекты работы резервного копирования.
Изменения во фреймворке
Если раньше Volume открывал OpenStack и открытый Volume передавался драйверу, то теперь после модификации интерфейса драйвера добавилась версия:

При новой версии драйвера фреймворк больше не пытается открыть вольюм и вернуть нам «поток для чтения», а просто передает сам вольюм, чтобы драйвер бэкапа сам с ним работал. Для старой версии по-прежнему отдается уже открытый Volume. Мы оставили совместимость на случай, если не захочется терять Legacy-драйверы и бэкапы. Внесенные во фреймворк изменения при этом можно легко откатить.
Переход на многопроцессную архитектуру
Драйвер бэкапа написан на Python, поскольку это основной язык разработки платформы OpenStack. В коде платформы активно используется библиотека eventlet, что создает серьезные проблемы при многопоточной обработке. Чтобы обойти создаваемые этим ограничения мы решили использовать многопроцессную архитектуру. Вот как это выглядит.
Мы разбили цикл резервного копирования на множество шагов, каждый из которых обрабатывается своим агентом, на вход принимает команду, а на выход передает набор команд для следующих шагов.
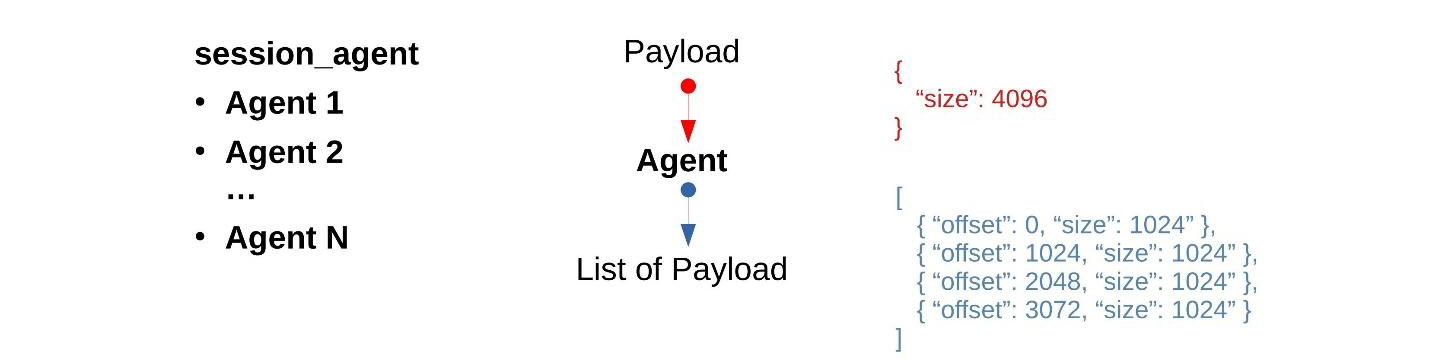
Каждый агент — отдельный процесс. При таком подходе чтение 10 ГБ данных можно раскидать на 10 итераций по 1 ГБ, читая данные параллельно, поскольку каждый агент сам открывает Volume или Snapshot и работает с ним независимо от других агентов. Потоки входящих и исходящих сообщений при этом будут асинхронными: сообщения агенту будут поступать одно за другим, не дожидаясь окончания предыдущих, а ответы будут забираться по мере их создания.
Мы разделили цикл Backup на семь агентов:
- Master бэкапа планирует резервную копию: определяет, как копировать, какими блоками читать, какого размера и во сколько потоков.
- Reader открывает Volume столько раз, сколько нужно (может в четыре потока, а может и в восемь), затем получает команду от Master на чтение данных, читает их, складывает в Shared Memory и отдает следующему агенту.
- Checksum рассчитывает контрольные суммы. Он многопоточный и загружает, как правило, 8–16 ядер. После расчета контрольных сумм эстафета переходит следующему агенту. Данные никуда не копируются и продолжают лежать в Shared Memory.
- DiffHandler поднимает из предыдущего бэкапа (если он был) список Checksum-блоков, сравнивает контрольные суммы и оставляет только те данные, которые изменились. Сохраненные данные уходят на сжатие, все остальное из потока удаляется. Таким образом поддерживаются инкрементальные копии.
- Compressor сжимает каждый блок многопоточно независимо от других и отправляет их следующему агенту.
- DataWriter агрегирует маленькие блоки в большие сегменты и с помощью Multipart перекладывает данные в S3.
- MetadataWriter финиширует бэкап, записывает в S3 итоговый набор контрольных сумм и метаданные бэкапа.
Межпроцессное взаимодействие строится через Unix Domain Socket. На всех этапах кроме двух — DiffHandler и Compressor — данные, по возможности, не копируются (zero-copy).
Цикл восстановления (Restore) намного проще:
- Master читает метаданные о бэкапе, восстанавливает и составляет план действий.
- BackupReader считывает данные из S3 в параллельном режиме и отдает их в декомпрессор.
- Decompressor — также в параллельном режиме — разжимает полученные блоки и отдает на следующий этап.
- Writer пишет полученные данные на диски.
Цикл удаления (Delete) чисто формальный: S3Worker читает метаданные бэкапа и удаляет те объекты из S3, которые принадлежат этому бэкапу.
Zero-copy между агентами
Выше я упомянул, что мы стараемся лишний раз не копировать данные. Давайте рассмотрим на простом примере использование POSIX IPC Shared-Memory-агентами. Backup master отдает команду: «Прочитать 4 KБ».
{ "offset": 0, "size": 4096 }DataReader читает 4 KБ в сегмент Shared Memory, затем имя этого сегмента записывается в следующее сообщение:
{ "offset": 0, "size": 4096,
"shm_id": "reader_12345_1" }Этот сегмент передается в блок расчета контрольных сумм.
Checksum считает контрольную сумму, приписывает ее к сообщению, и оно пересылается дальше:
{ "offset": 0, "size": 4096,
"shm_id": "reader_12345_1",
"hash": "abc1234567890def" }Compressor считывает блок, который сгенерировал Reader, освобождает его, создает собственный блок с новым идентификатором, записывает в него сжатые данные и отправляет с измененной командой дальше:
{ "offset": 0, "size": 4096,
"shm_id": "cmpt_12345_1",
"hash": "abc1234567890def" }Получился стройный поток команд, когда каждый шаг может что-то изменить в команде и отправить дальше.
Асинхронная обработка событий
Даже если команды попадают в агент в определенном порядке, выполняются они с разной скоростью. Допустим, первое сообщение было отработано быстро, а второе отрабатывалось долго. За это время успели обработаться третье, четвертое и пятое сообщение, и только после этого пришел ответ на второе сообщение.

Эта асинхронная цепочка тоже поддерживается реализацией всех агентов. Если бэкап застрял на чтении какого-то блока из Ceph (например, если в кластере идут процедуры обслуживания: ребаланс, Scrub, еще что-то), то данные продолжают собираться на бэкап.
Асинхронность подразумевает, что данные могут идти не в том порядке, в котором писались, но соответствующие сегменты можно переупорядочить. Надо только не забыть сохранить метаданные о том, что и куда было записано.
Сборка мусора
Еще одна задача, которую решают агенты, — сборка мусора. Фреймворк обработки сообщений читает пришедшее агенту сообщение, вызывает точку входа, передает ей это сообщение, получает множество ответных сообщений и сравнивает, какие сегменты Shared Memory поступили и какие были возвращены. Пропавшие сегменты (были в начальном сообщении, но не упоминаются в ответных сообщениях) фреймворк автоматически освобождает.
Например, на вход пришел сегмент с префиксом
reader, а на выход — два сегмента от компрессора. Следовательно, надо освободить сегмент с префиксом reader, что менеджер ресурсов и делает.
Если на вход пришел сегмент
reader_12345_1, а на выход — reader_12345_1 и compressor_12345_1, то менеджер ресурсов понимает, что освобождать нечего, поскольку сегмент использован повторно, и продолжает с ним работать без лишних копирований и преобразований.Снижение количества зависимостей
При реализации новой архитектуры команда VK Cloud Solutions постаралась избежать лишних зависимостей за счет использования стандартных решений:
- POSIX IPC Shared Memory;
- UNIX Domain Socket;
- JSON в качестве формата данных.
Это позволяет не использовать тяжеловесные библиотеки OpenStack и ограничиться стандартной инсталляцией Python с небольшими дополнениями. Сложные зависимости, которые работают с Ceph, вынесены в отдельные агенты.
В результате можно бэкапить не только OpenStack volumes, но и BareMetal (физические диски серверов). Эта возможность, например, периодически используется для тестирования корректности настроек серверов бэкапа. Для теста сервиса передается небольшой файл, который считается диском, и предлагается его забэкапить. Если при настройке одного из элементов инфраструктуры допущена ошибка или возникла проблема (запрещен доступ, не прописан маршрут и т. д.), бэкап падает.
Дополнительные доработки
Использование снэпшотов Ceph
Резервное копирование дисков Ceph в облаке делалось через создание временного диска, из-за чего он попадал в биллинг, что по понятным причинам не нравилось пользователям. Чтобы не выполнять эту цепочку действий на биллинге, команда включила поддержку снапшотов в Os-brick в Ceph.
Backup locality
На платформе VK Cloud Solutions есть две площадки и пять зон доступности (четыре на одной площадке и одна на второй). Чтобы бэкапы не размазывались по зонам доступности и не ходили по сети в другой дата-центр, мы изменили механизм планировщика. Теперь он учитывает схему с зонами доступности: бэкап делается всегда рядом с СХД, в которой расположен диск, что кратно снижает трафик во время окна бэкапа.
В OpenStack бэкап по умолчанию восстанавливается на том же хосте, на котором создавался. Поэтому, если хост «умирал» надо было вносить соответствующие правки в базу. Эту настройку также убрали из планировщика, чтобы выбор сервера для восстановления бэкапа также происходил на уровне зон доступности.
Уменьшение времени простоя
Теперь сбои бэкапов в облаке могут происходить только по одной из трех причин:
- гостевой агент не заморозил ввод/вывод;
- у клиента закончилась квота на бэкапы или снэпшоты;
- случилась проблема в инфраструктуре (например, стала недоступна сеть, что-то случилось с сервисом, хранилищем, аутентификацией или биллингом).
Агенты разработанного драйвера сами открывают переданный диск столько раз, сколько нужно. Данные обрабатываются во много потоков и много процессов, чтобы не упираться в узкие места (GIL, eventlet и прочие). А чтобы избежать излишнего копирования, промежуточные данные хранятся в Shared Memory.
Кроме того, чтобы не допускать простоя на время записи в S3 используется новый формат, позволяющий сохранять данные диска в случайном порядке (Out-of-order). Это привело к тому, что сам бэкап больше не является простым потоком, распаковав который можно получить образ диска. Теперь это сложная структура, обработка которой параллелится на этапе восстановления и записи.
Финальная оптимизация и результаты
После смены архитектуры скорость бэкапа в VK Cloud Solutions выросла до 1,5 ГБ/с на один диск с поддержкой L1-сжатия. Суммарная производительность системы выросла до 40 ГБ/с виртуального пространства на тонких дисках, где не нужно читать, и до ~18 ГБ/с производительности кластерной фермы с фактическими данными.
За это приходится платить большим расходом памяти:
- 1 ГБ памяти на 1 ТБ данных при расчете контрольных сумм;
- 2 ГБ памяти на 1 ТБ данных под метаданные;
- 2 ГБ памяти на 1 ТБ данных для сериализации.
Для снижения расхода памяти мы оптимизировали работу со строками Python. Убрали лишнее и сделали одну большую строку, в которой лежат все контрольные суммы вместо массива строк. Это позволило снизить расход памяти в 2–3 раза в зависимости от этапа.
Вот статистика с нескольких серверов кластерной фермы VK Cloud Solutions (в гигабитах в момент пика):
C10 = 18 in / 5,6 out
C19 = 25 in / 4,8 out
C24 = 30 in / 4,8 out
C25 = 25 in / 5,3 out
C26 = 20 in / 7,9 out
C27 = 25 in / 5,8 out
Команда VK Cloud Solutions развивает собственный сервис бэкапов для автоматизированного управления резервными копиями ВМ и БД. Будет здорово, если вы протестируете наши решения и дадите обратную связь. Для тестирования пользователям при регистрации начисляем 3000 бонусных рублей.
Что еще почитать:
