
Всем привет, меня зовут Алексей Остриков, я руковожу разработкой в Яндекс.Маркете. Когда-то я много-много писал код, затем полтора года руководил группой бэкенда одного из сервисов Маркета, а сейчас отвечаю за разработку курьерской платформы Маркета.
Сегодня я расскажу, почему доставка на аутсорсе — это не всегда хорошо, для чего нужна прозрачность процессов и как мы за полтора года написали платформу, которая помогает нашим курьерам доставлять заказы. А ещё поделюсь тремя историями из мира разработки.

На фото — команда курьерской платформы десять месяцев назад. В те времена она помещалась в одной комнате. Сейчас нас стало в 5 раз больше.
Разрабатывая курьерскую платформу, мы хотели прокачать три главные вещи.
Первое — качество. Когда мы работаем с внешними службами доставки, качеством управлять невозможно. Компания-подрядчик обещает, что будет такая-то доставляемость, но энное количество заказов могут не довезти. А нам хотелось процент опозданий понизить до минимума, чтобы практически любой заказ был доставлен вовремя.
Второе — прозрачность. Когда что-то идёт не так (происходят переносы, срывы сроков), то мы не знаем, почему они произошли. Мы не можем пойти и подсказать: «Ребят, давайте делать вот так». Мы и сами не видим, и клиенту не можем показать какие-то дополнительные вещи. Например, что заказ приедет не к восьми, а в интервале 15 минут. А всё потому, что в процессе нет такого уровня прозрачности.
Третье — деньги. Когда мы работаем с подрядчиком, есть договор, в котором прописаны суммы. И мы можем менять эти циферки в рамках договора. А когда мы отвечаем за весь процесс от а до я, то можно видеть, какие части системы спроектированы экономически невыгодно. И можно, например, поменять провайдера SMS или формат документооборота. Или можно заметить, что у курьеров слишком большие пробеги. И если строить маршруты кучнее, то в итоге получится развозить больше заказов. Благодаря этому можно ещё и сэкономить деньги — доставка станет более эффективной.
Это и были те три цели, которые мы ставили во главу всего.
Давайте посмотрим, что у нас получилось.

На изображении показана схема процесса. У нас есть большие склады, на которых хранятся сотни тысяч заказов. С каждого склада вечером уезжают фуры, доверху набитые заказами. Там может быть 5–6 тысяч заказов. Эти фуры едут в здания поменьше, которые называются «сортировочные центры». В них за несколько часов большая куча заказов превращается в маленькие кучки для курьеров. И когда с утра приезжают курьеры на машинах, то каждый курьер знает, что ему нужно забрать кучку вот с этим QR-кодом, загрузить себе в машину и поехать развозить.
И бэкенд, о котором я хочу рассказать в этой статье, — про самую последнюю часть процесса, когда заказы везут клиентам. Всё, что до этого, пока оставим в стороне.

Как это видит курьер
У курьеров есть приложение для Android, написанное на React Native. И в этом приложении они видят весь свой день. Они чётко понимают последовательность: на какой адрес ехать сначала, на какой потом. Когда позвонить клиенту, когда отвезти возвраты в сортировочный центр, как начать день, как закончить. Они всё видят в приложении и практически не задаются лишними вопросами. Мы им очень помогаем. По сути, они просто выполняют задания.

Помимо этого, на платформе есть элементы управления. Это многофункциональная админка, которую мы переиспользовали из другого сервиса Яндекса. В этой админке можно конфигурировать состояние системы. Мы загружаем туда данные о новых курьерах, изменяем интервалы работы. Можем корректировать процесс создания заданий на завтра. Регулируется практически всё, что нужно.
Кстати, про бэкенд. Мы в Маркете очень любим Java, в основном версию 11. И все бэкенд-сервисы, про которые пойдёт речь, написаны на Java.

В архитектуре нашей платформы есть три главных узла. Первый отвечает за коммуникацию с внешним миром. Курьерское приложение «стучится» на балансер, который выведен вовне, общаясь с ним по стандартному JSON HTTP API. По сути, этот узел отвечает за всю логику текущего дня, когда курьеры что-то переносят, отменяют, выдают заказы, получают новые задания.
Второй узел — это сервис, который коммуницирует с внутренними сервисами Яндекса. Все сервисы — это классические RESTful-сервисы со стандартной коммуникацией. Когда вы сделаете заказ на Маркете, через какое-то время к вам прилетит документ в JSON-формате, где будет всё написано: когда доставляем, кому доставляем, в какой интервал. И у нас это состояние сохранится в базу данных. Всё просто.
Помимо этого, второй узел также коммуницирует с другими внутренними сервисами, уже не Маркета, а Яндекса. Например, за уточнением геокоординат мы уходим в геосервис. Чтобы отправить push-уведомление, идём в сервис, который рассылает push и SMS. Для авторизации используем другой сервис. Для расчёта маршрутизации на завтра — ещё один сервис. Таким образом осуществляется вся коммуникация с внутренними службами.
Этот узел также является входной точкой, у него есть API, в которую «стучится» наша админка. У неё есть свой endpoint, который называется, скажем, /partner. И наша админка, всё состояние системы, конфигурируется через коммуникацию с этим сервисом.
Третий узел — это база фоновых задач. Здесь используется Quartz 2, там есть задачи, которые запускаются по крону с разными условиями для разных точек, для разных сортировочных центров. Там есть задачи актуализации дня, задачи процессов закрытия дня, старта нового дня.
И в центре всего находится база данных, в которой, собственно, и хранится всё состояние. Все сервисы входят в одну базу данных.

У Яндекса есть несколько дата-центров, и наш сервис регионально распределен по трём дата-центрам. Как это выглядит.
База данных — это три хоста, каждый в своём дата-центре. Один хост — мастер, две другие — реплики. В мастер мы пишем, с реплик читаем. Все другие Java-сервисы — это также Java-процессы, которые крутятся в нескольких дата-центрах.
Один из узлов — это наш API. Он крутится во всех трёх дата-центрах, потому что поток сообщений больше, чем из внутренних сервисов. Более того, такая схема позволяет вам довольно легко горизонтально масштабироваться.
Допустим, если у вас входящий трафик увеличится в девять раз, вы можете провести оптимизацию, но также вы можете «залить» это дело железом, открыв больше узлов, которые будут обрабатывать входящий трафик.
Балансеру придётся просто делить трафик на большее количество точек, которые выполняют запросы. И у нас сейчас, например, не один узел, а по два узла в каждом дата-центре.
Наша архитектура позволяет справляться даже с такими случаями, как отключение одного из дата-центров. Например, мы решили провести учения и отключили дата-центр во Владимире, — и наш сервис остаётся на плаву, ничего не меняется. У нас исчезают хосты базы данных, которые лежат там, а сервис остаётся в работе.
Балансер понимает через какое-то время: ага, у меня не осталось ни одного живого хоста в этом дата-центре, и — больше не перенаправляет туда трафик.
Все сервисы в Яндексе устроены схожим образом, мы все умеем переживать отказ одного из дата-центров. Как это реализовано, что такое graceful degradation и как сервисы в Яндексе переносят отключение одного из дата-центров, мы уже рассказывали.
Итак, это была архитектура. А теперь начинаются истории.
Недавно у нас была Yet another Conference, там Роверу уделили много внимания. Я продолжу тему.
Как-то раз к нам пришли ребята из команды Яндекс.Ровера и предложили проверить гипотезу, что люди захотят получать заказы таким экстраординарным способом.
Яндекс.Ровер — это маленький робот размером со среднюю собачку. Туда можно положить еду, пару коробок заказов, — он поедет по городу и привезёт заказы без помощи человека. Там есть лидар, робот понимает своё положение в пространстве. Он умеет доставлять малогабаритные заказы.
И мы подумали: а почему бы и нет? Уточнили детали эксперимента: на тот момент нужно было проверить гипотезу, что людям это понравится. И мы решили довезти 50 заказов за полторы недели в очень лайтовом режиме.

Мы придумали максимально простой флоу, когда человеку приходит SMS с предложением нестандартного способа доставки — не курьер привезёт, а Ровер. Весь эксперимент проходил во внутреннем дворе Яндекса. Человек выбирал подъезд, к которому Ровер подъедет. Когда робот приезжал — открывалась крышка, клиент брал заказ, закрывал крышку, и Ровер уезжал за новым заказом. Всё просто.
Затем мы пришли к команде Ровера, чтобы договориться про API.
В API Ровера есть простые методы: открыть крышку, закрыть крышку, поехать в такую-то точку, получить состояние. Классика. Тоже JSON. Очень просто.
Что ещё очень важно: и такие маленькие истории, и любые большие истории лучше делать через feature flags. Фактически у вас есть рубильник, по которому вы можете в production включить эту историю. Когда она вам больше не нужна, эксперимент завершен успешно или не успешно, либо заметили какие-то баги, вы просто вырубаете её. И вам не нужно делать ещё один деплой новой версии кода на прод. Эта штука здорово облегчает жизнь.
Казалось бы, всё просто и всё должно работать. Там даже две недели нечего разрабатывать, можно за несколько дней сделать. Но посмотрите, где собака зарыта.
Все процессы в основном синхронны. Человек нажимает кнопку, крышка открывается. Человек нажимает кнопку, крышка закрывается. Но один из этих процессов — асинхронный. В момент, когда Ровер к вам поедет, нужно, чтобы был какой-то фоновый процесс, который будет отслеживать, что робот вернулся на точку.
И в этот момент мы отправим SMS человеку, например, что Ровер ждёт на месте. Это невозможно сделать синхронно, и нужно как-то решить эту проблему.
Есть много разных подходов. Мы сделали максимально простой вариант.
Мы решили, что можно запустить самый обычный фоновый Java-тред либо задачу в Executer. Этот фоновый тред тут же запускается отслеживать процесс. И как только процесс выполнен, мы отправляем уведомление.

Выглядит это, например, так. Это практически копия кода с production, за исключением вырезанных комментариев. Но есть подвох. Нельзя делать таким образом серьёзные системы. Допустим, мы выкатываем новую версию на бэкенд. Хост перезагружается, состояние теряется, и всё, Ровер уезжает в бесконечность, его больше никто не видит.
Но почему? Если мы знаем, что наша цель — доставить 50 заказов за полторы недели, мы сами выбираем время, когда следим за бэкендом. Если что-то пойдёт не так, можно вручную что-то изменить. Для такой задачи это решение более чем достаточное. И в этом кроется мораль первой истории.
Существуют ситуации, для которых нужно делать минимальную версию функционала. Не нужно огород городить и овер-инжинирить. Лучше делать максимально отчуждаемо. Так, чтобы не очень сильно изменять логику внутренних объектов. И избыточная сложность, ненужный технический долг не накапливались.
Но сначала несколько слов о том, как устроены основные сущности. Есть сервис Яндекс.Маршрутизация, который в конце дня строит маршруты курьерам.
Каждый маршрут состоит из точек на карте. И на каждой точке у курьеров есть задание. Это может быть задание выдать заказ, или позвонить клиенту, или с утра загрузиться на сортировочном центре, забрать все заказы.
Помимо этого, клиенты с утра получают ссылку с трекингом. Они могут открыть карту и увидеть, как к ним едет курьер. Клиент также может выбрать доставку Ровером, про который я говорил ранее.
Теперь давайте посмотрим, как эти сущности можно показать в базе данных. Это делается, например, вот так.

Это очень аккуратная модель данных. Мы не придумали ни одной новой сущности, и сильно не схлопывали уже существующие.
На схеме видно, что стрелочка снизу вверх показывает маршрут курьера, знает того курьера, чей это маршрут. В табличке «маршрут курьера» есть ссылка «курьер ID». А верхняя табличка этого не знает. У нас максимально простая связанность, нет большого пересечения сущностей. Когда все знают про всех, это сложнее контролировать, и, скорее всего, будет избыточность. Поэтому у нас максимально простая схема.
Единственное «излишество», которое мы сделали в самом начале создания платформы, такое. У нас был один вид заданий на доставку. Но мы поняли, что в будущем появятся другие задания. И мы заложили небольшую архитектурную гибкость: у нас есть задания, и одно из видов заданий — доставка заказа.
Затем добавили трекинг и Ровер. Всего лишь по две таблички. В трекинге — курьер отправляет свои координаты, мы их фиксируем в отдельной табличке. И есть трекинг заказа со своей моделью состояний, есть дополнительные штуки, типа «SMS ушла / не ушла». Не стоит это добавлять прямо в задание. Лучше вынести в отдельную табличку, ведь этот трекинг нужен не для всех типов заданий.

В Ровере — его координаты и доставка. У нас доставка Ровером — это трекинг как бы для Ровера. Можно его добавить в трекинг заказа, но зачем? Ведь когда мы избавимся от этого эксперимента, когда он будет выключен, эти опции навсегда останутся в сущности трекинга. Там будут null-поля.
Может возникнуть вопрос: а зачем делать табличку с координатами? Один Ровер доставляет пять заказов в день. Не нужно хранить координаты в базе данных, — можно просто ходить в API Ровера и получать их на runtime.
Суть в том, что так и было сделано изначально. Этой таблички не было, мы сразу ходили на сервис и всё это брали. Но во время тестов мы увидели, что много людей открывают карту с катящимся Ровером, и нагрузка на этот сервис кратно возрастает. Допустим, семь человек открыли. А там на страничке каждые две секунды Java Script запрашивает координаты. И коллеги нам писали в чат: «Откуда такая нагрузка? У вас же там один человек должен кататься».
И после этого мы добавили табличку. Начали складывать туда координаты, время, в которое они были получены. И теперь, если к нам слишком часто приходят за координатами и не прошло ещё две секунды с последнего получения, мы берём их из таблички. Получается такой кэш на уровне баз данных.
Эту историю можно было сделать с помощью 20 таблиц. Можно было использовать две таблицы: курьер и заказ. Но в первом случае это был бы over-engineering, а во втором случае это было бы слишком сложно поддерживать. Сложная логика, сложно тестировать.
И ещё. Структура баз данных, которую мы сделали полтора года назад, ядро этих сущностей осталось до сих пор неизменным. И нам очень сильно повезло, что мы смогли выбрать такие сущности, на которых основу не пришлось переделывать. Не пришлось значительно перекраивать базы данных, делать сложные миграции, затем катить этот релиз, очень долго его тестировать и потом менять именно корневую структуру.
Суть истории в том, что есть аспекты, которым лучше уделять дополнительное внимание. Первое — особое внимание уделяйте структуре API и БД. Старайтесь замечать, какие у вас сущности есть в реальной жизни. Пытайтесь переложить эту структуру примерно таким же образом в цифровом виде. Старайтесь не сильно её сокращать, не сильно расширять.
Второе — есть ошибки, исправление которых стоит дорого. Ошибки на уровне API исправлять сложнее, чем ошибки на уровне баз данных, потому что обычно API пользуется много клиентов. И когда вы сильно меняете API, вам придётся:
Это очень затратно.
Ошибки в коде по сравнению с этим — вообще ерунда. Код вы просто переписали, прогнали тесты. Тесты зелёные — вы запушили в мастер. А вот API базы данных уделяйте особое внимание.
И как бы вы хорошо ни старались следить за базой данных, через какое-то время она превратится во что-то неуправляемое. На скрине вы видите одну десятую часть нашей базы данных, которая сейчас существует.

Есть один совет. Когда вы очень быстро разрабатываете что-то, в базе данных возникают неточности, иногда не хватает внешнего ключа или появляется дубль поля. Поэтому иногда, раз в два-три месяца, просто смотрите только на базу. Та же Intellij IDEA умеет генерировать классные схемы. И там это всё видно.
Ваша база данных должна быть адекватной. Очень легко за час сделать список из шести тикетов: здесь добавить внешний ключ, там индекс. Как бы вы ни старались, какой-то мусор неизбежно будет накапливаться.
Есть вещи, которые лучше с самого начала делать хорошо. Важно действовать по принципу «нормально делай — нормально будет».
Например, у нас есть один процесс, который крайне важен для платформы. Весь день мы набираем заказы на завтрашний день, но вечером срабатывает пометка, что после 22:00 мы не набираем заказы, а до 01:00 готовимся к завтрашнему дню. Потом начинается распределение заказов по сортировочным центрам. Мы идём в Яндекс.Маршрутизацию, она строит маршруты.
И если эта подготовительная работа сорвётся, весь завтрашний день под вопросом. Завтра курьерам некуда будет ехать. У них не создано состояние. Вот это в нашей платформе самый критичный процесс. И такие важные процессы нельзя делать по остаточному принципу, с минимальными ресурсами.
Я помню, у нас было время, когда этот процесс сбоил, и несколько недель чуть ли не половина команды в чате решала эти проблемы, все спасали положение, что-то переделывали, перезапускали.
Мы понимали, что если процесс не завершится с десяти вечера до часу ночи, то сортировочные центры даже не будут знать, как им сортировать заказы, на какие кучки. Там будет всё простаивать. Курьеры выйдут позже, и у нас будут провалы по качеству.
Такие процессы лучше сразу делать максимально хорошо, продумывая каждый шаг, где может что-то пойти не так. И подкладывать везде максимальное количество соломки.
Расскажу про один из вариантов, как можно настроить такой процесс.
Процесс этот многосоставный. Расчёт маршрутов и их публикацию можно разбить на части и, например, создать очереди. Тогда у нас есть несколько очередей, которые отвечают за законченные участки работы. И есть consumer на этих очередях, которые сидят и ждут сообщения.

Например, день закончился, мы хотим рассчитать маршруты на завтра. Мы отправляем запрос в первую очередь: сформируй задание и запусти расчёт. Consumer забирает первое сообщение, идёт в сервис маршрутизации. Это асинхронный API. Consumer получает ответ, что задача взята в работу.
Он кладёт этот ID в базу, а в очередь с заданиями в обработке кладет новое задание. И всё. Из первой очереди сообщение исчезает, «просыпается» второй consumer. Он берёт второе задание на обработку, и его задача — регулярно ходить в маршрутизацию и проверять, не выполнилась ли еще эта задачка на расчёт.
Задача уровня «создай маршруты для 200 курьеров, которые развезут несколько тысяч заказов в Москве» занимает от получаса до часа. Это действительно очень сложная задача. И ребята из этого сервиса очень крутые, они решают сложнейшую алгоритмическую задачу, которая требует большого количества времени.
В итоге consumer второй очереди будет просто проверять, проверять, проверять. Через какое-то время задача выполнится. Когда задача выполняется, мы получаем ответ в форме нужной структуры завтрашних маршрутов и смен для курьеров.
Мы кладём то, что рассчиталось, в третью очередь. Сообщение исчезает из второй очереди. И «просыпается» третий consumer, берёт этот контекст с сервиса Яндекс.Маршрутизация и на его основе создаёт state завтрашнего дня. Он создаёт задания курьеров, он создаёт заказы, создаёт смены. Это тоже немалая работа. Он тратит на это какое-то время. И когда всё создано, эта транзакция завершается и задание из очереди удаляется.
Если на любом участке этого процесса что-то идёт не так, сервер перезагружается. При последующем восстановлении мы просто увидим тот момент, на котором мы закончили. Допустим, прошла первая фаза и вторая. И перейдём к третьей.
С такой архитектурой последние месяцы у нас всё идёт довольно гладко, проблем нет. Но раньше был сплошной try-catch. Непонятно, где процесс сбоился, какие статусы поменяли в базе данных и так далее.
Есть вещи, на которых лучше не экономить. Есть вещи, с которыми вы сэкономите себе кучу нервных клеток, если сразу сделаете всё хорошо.
Я описал бо́льшую часть того, что происходит на нашей платформе. Но кое-что осталось за кадром.
Мы узнали про софт, который помогает курьерам развезти заказы в рамках дня. Но кто-то должен эти кучки для курьеров сделать. В сортировочном центре люди должны рассортировать большую машину заказов по маленьким кучкам. Как это делается?
Это вторая часть платформы. Мы сами написали весь софт. У нас теперь есть терминалы, с помощью которых кладовщики считывают код с коробочек и кладут их в соответствующие ячейки. Там довольно сложная логика. Этот бэкенд не сильно проще, чем тот, про который я уже рассказывал.
Эта вторая часть пазла была необходима, чтобы вместе с первой дать возможность распространять процесс на другие города. Иначе нам пришлось бы в каждом новом городе искать подрядчика, который смог бы наладить обмен какими-нибудь экселями по почте, либо интегрироваться с нашим API. И это было бы очень долго.
Когда у нас есть первая и вторая часть пазла, мы просто можем арендовать какое-то здание, нанять курьеров на машинах. Сказать им, как нажимать, что нажимать, как пикать, какую коробку куда класть, — и всё. Благодаря этому мы уже запустились в семи городах, у нас больше десяти сортировочных центров.
И открытие нашей платформы в новом городе по времени занимает совсем немного. Более того, мы научились не только развозить заказы по конкретным людям. Мы умеем с помощью курьеров привозить заказы в пункты выдачи. Мы также написали софт для них. И на этих точках тоже выдаём заказы людям.
В начале я говорил, зачем мы начинали создавать собственную курьерскую платформу. Теперь расскажу, чего мы достигли. Это невероятно, но при использовании нашей платформы мы смогли приблизиться почти к 100% попадания в интервал. Например, за последнюю неделю качество доставляемости в Москве было порядка 95–98%. Это значит, что в 95–98% случаев мы не опаздываем. Мы укладываемся в интервал, который выбрал клиент. И мы даже не могли мечтать о такой точности, когда полагались исключительно на внешние службы доставки. Поэтому сейчас мы постепенно распространяем нашу платформу на все регионы. И будем улучшать доставляемость.
Мы получили нереальную прозрачность. Эта прозрачность нужна и нам. У нас всё логируется: все действия, весь процесс выдачи заказа. У нас есть возможность вернуться в историю на пять месяцев и сравнить какую-то метрику с текущей.
Но также мы дали эту прозрачность клиентам. Они видят, как к ним едет курьер. Они могут взаимодействовать с ним. Им не нужно звонить в службу поддержки, говорить: «Где мой курьер?»
Вдобавок получилось оптимизировать издержки, потому что у нас есть доступ ко всем элементам цепочки. В итоге сейчас довезти один заказ стоит на четверть дешевле, чем это было раньше, когда мы работали с внешними службами. Да, траты на доставку заказа уменьшились на 25%.
И если обобщать все идеи, о которых шла речь, можно выделить следующее.
Вы должны чётко понимать, на каком этапе развития находится ваш текущий сервис, ваш текущий проект. И если это состоявшийся бизнес, которым пользуются миллионы людей, которым пользуются, возможно, в нескольких странах, вы не можете всё делать на таком уровне, как с Ровером.
Но если у вас эксперимент… Эксперимент отличается тем, что в любой момент, если мы не показываем обещанных результатов, нас могут закрыть. Не взлетело. И это нормально.
И в таком режиме мы находились около десяти месяцев. У нас были отчётные интервалы, каждые два месяца мы должны были показывать результат. И у нас всё получилось.
В таком режиме, мне кажется, вы не имеете права делать что-то, инвестируя в long-term и не получая ничего на короткой дистанции. Столь сильно закладываться на будущее в таком формате работы нельзя, потому что будущее может просто не наступить.
И любой грамотный разработчик, технический руководитель должен постоянно выбирать между тем, чтобы сделать на костылях или сразу строить космолёт.
Если говорить коротко, постарайтесь делать максимально просто, но оставляя возможности для расширения.
Есть первый уровень, когда нужно делать совсем просто. А есть первый уровень со звёздочкой, когда ты делаешь просто, но оставляешь хотя бы немного пространства для манёвра, чтобы это можно было расширить. При таком мышлении, мне кажется, результаты будут гораздо лучше.
И последнее. Я рассказывал про Ровер, что хорошо подобные процессы делать с помощью feature flags (фиче-флагов). Советую послушать доклад Марии Кузнецовой с митапа по Java. Она рассказывала, как устроены фиче-флаги в нашей системе и мониторинге.
Сегодня я расскажу, почему доставка на аутсорсе — это не всегда хорошо, для чего нужна прозрачность процессов и как мы за полтора года написали платформу, которая помогает нашим курьерам доставлять заказы. А ещё поделюсь тремя историями из мира разработки.

На фото — команда курьерской платформы десять месяцев назад. В те времена она помещалась в одной комнате. Сейчас нас стало в 5 раз больше.
Зачем мы всё это делали
Разрабатывая курьерскую платформу, мы хотели прокачать три главные вещи.
Первое — качество. Когда мы работаем с внешними службами доставки, качеством управлять невозможно. Компания-подрядчик обещает, что будет такая-то доставляемость, но энное количество заказов могут не довезти. А нам хотелось процент опозданий понизить до минимума, чтобы практически любой заказ был доставлен вовремя.
Второе — прозрачность. Когда что-то идёт не так (происходят переносы, срывы сроков), то мы не знаем, почему они произошли. Мы не можем пойти и подсказать: «Ребят, давайте делать вот так». Мы и сами не видим, и клиенту не можем показать какие-то дополнительные вещи. Например, что заказ приедет не к восьми, а в интервале 15 минут. А всё потому, что в процессе нет такого уровня прозрачности.
Третье — деньги. Когда мы работаем с подрядчиком, есть договор, в котором прописаны суммы. И мы можем менять эти циферки в рамках договора. А когда мы отвечаем за весь процесс от а до я, то можно видеть, какие части системы спроектированы экономически невыгодно. И можно, например, поменять провайдера SMS или формат документооборота. Или можно заметить, что у курьеров слишком большие пробеги. И если строить маршруты кучнее, то в итоге получится развозить больше заказов. Благодаря этому можно ещё и сэкономить деньги — доставка станет более эффективной.
Это и были те три цели, которые мы ставили во главу всего.
Как выглядит платформа
Давайте посмотрим, что у нас получилось.
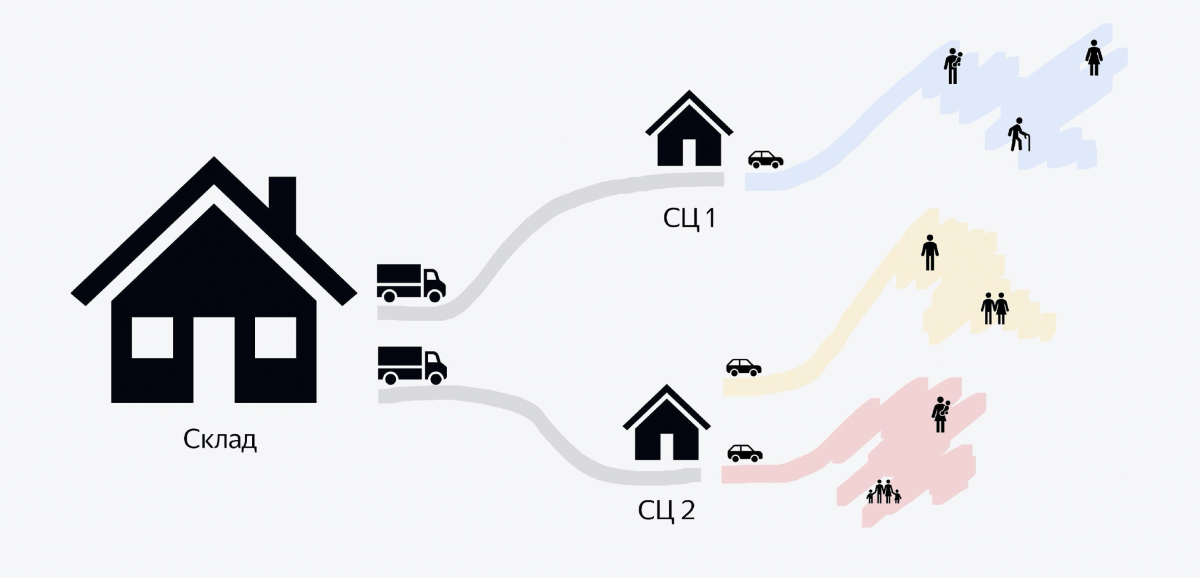
На изображении показана схема процесса. У нас есть большие склады, на которых хранятся сотни тысяч заказов. С каждого склада вечером уезжают фуры, доверху набитые заказами. Там может быть 5–6 тысяч заказов. Эти фуры едут в здания поменьше, которые называются «сортировочные центры». В них за несколько часов большая куча заказов превращается в маленькие кучки для курьеров. И когда с утра приезжают курьеры на машинах, то каждый курьер знает, что ему нужно забрать кучку вот с этим QR-кодом, загрузить себе в машину и поехать развозить.
И бэкенд, о котором я хочу рассказать в этой статье, — про самую последнюю часть процесса, когда заказы везут клиентам. Всё, что до этого, пока оставим в стороне.
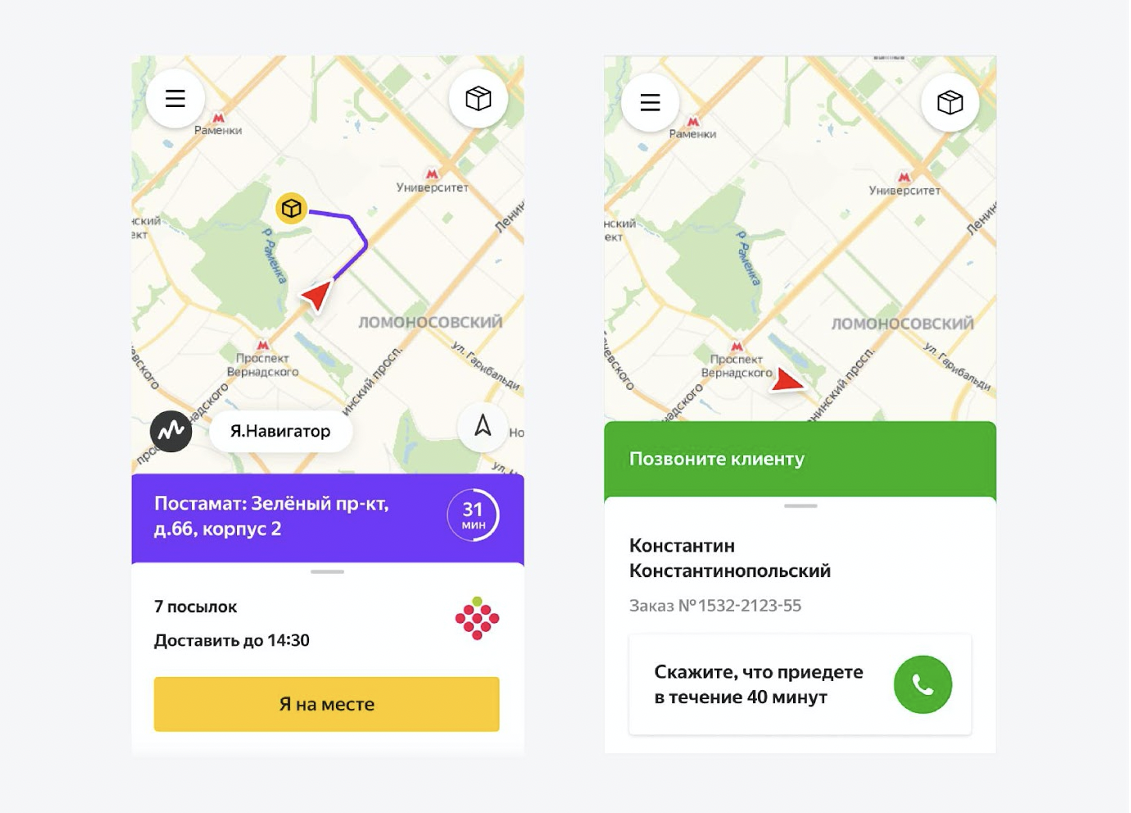
Как это видит курьер
У курьеров есть приложение для Android, написанное на React Native. И в этом приложении они видят весь свой день. Они чётко понимают последовательность: на какой адрес ехать сначала, на какой потом. Когда позвонить клиенту, когда отвезти возвраты в сортировочный центр, как начать день, как закончить. Они всё видят в приложении и практически не задаются лишними вопросами. Мы им очень помогаем. По сути, они просто выполняют задания.
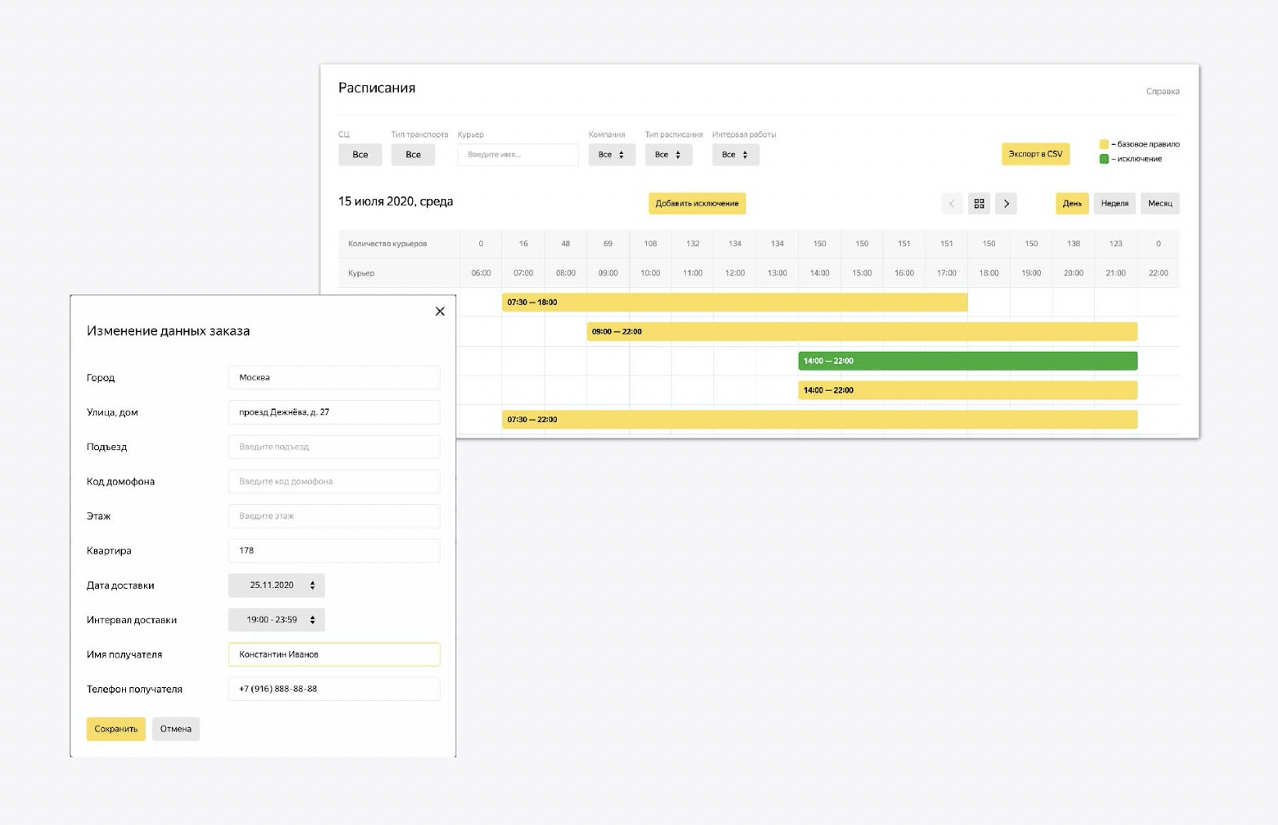
Помимо этого, на платформе есть элементы управления. Это многофункциональная админка, которую мы переиспользовали из другого сервиса Яндекса. В этой админке можно конфигурировать состояние системы. Мы загружаем туда данные о новых курьерах, изменяем интервалы работы. Можем корректировать процесс создания заданий на завтра. Регулируется практически всё, что нужно.
Кстати, про бэкенд. Мы в Маркете очень любим Java, в основном версию 11. И все бэкенд-сервисы, про которые пойдёт речь, написаны на Java.
Архитектура
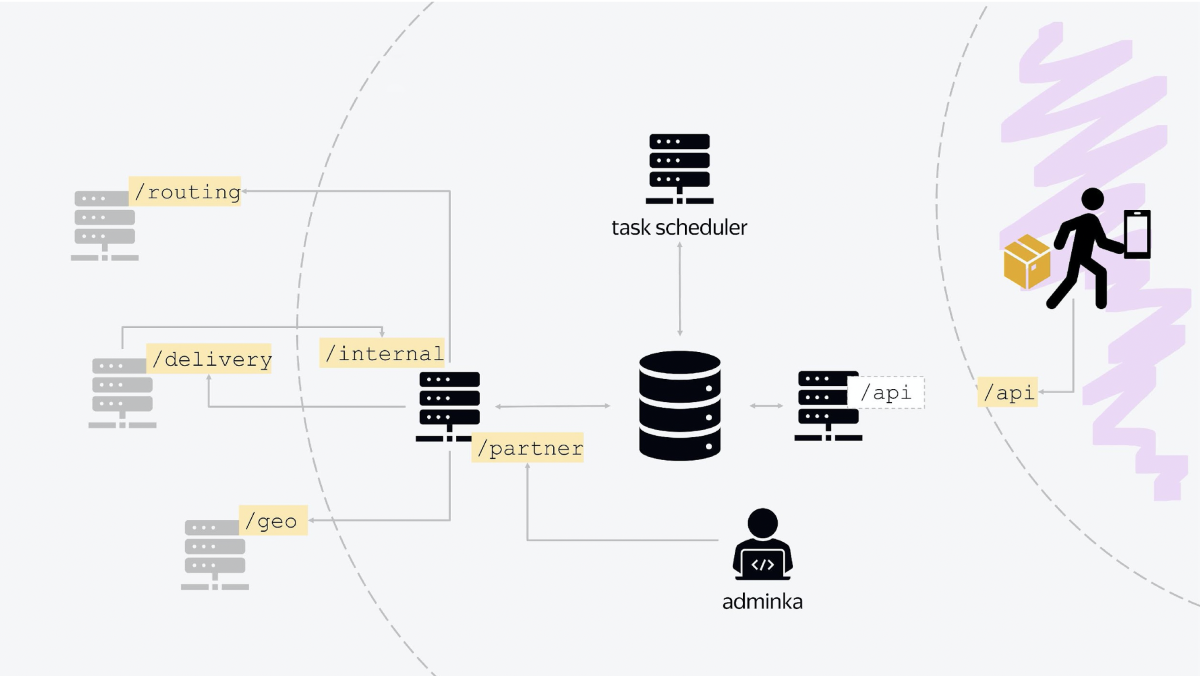
В архитектуре нашей платформы есть три главных узла. Первый отвечает за коммуникацию с внешним миром. Курьерское приложение «стучится» на балансер, который выведен вовне, общаясь с ним по стандартному JSON HTTP API. По сути, этот узел отвечает за всю логику текущего дня, когда курьеры что-то переносят, отменяют, выдают заказы, получают новые задания.
Второй узел — это сервис, который коммуницирует с внутренними сервисами Яндекса. Все сервисы — это классические RESTful-сервисы со стандартной коммуникацией. Когда вы сделаете заказ на Маркете, через какое-то время к вам прилетит документ в JSON-формате, где будет всё написано: когда доставляем, кому доставляем, в какой интервал. И у нас это состояние сохранится в базу данных. Всё просто.
Помимо этого, второй узел также коммуницирует с другими внутренними сервисами, уже не Маркета, а Яндекса. Например, за уточнением геокоординат мы уходим в геосервис. Чтобы отправить push-уведомление, идём в сервис, который рассылает push и SMS. Для авторизации используем другой сервис. Для расчёта маршрутизации на завтра — ещё один сервис. Таким образом осуществляется вся коммуникация с внутренними службами.
Этот узел также является входной точкой, у него есть API, в которую «стучится» наша админка. У неё есть свой endpoint, который называется, скажем, /partner. И наша админка, всё состояние системы, конфигурируется через коммуникацию с этим сервисом.
Третий узел — это база фоновых задач. Здесь используется Quartz 2, там есть задачи, которые запускаются по крону с разными условиями для разных точек, для разных сортировочных центров. Там есть задачи актуализации дня, задачи процессов закрытия дня, старта нового дня.
И в центре всего находится база данных, в которой, собственно, и хранится всё состояние. Все сервисы входят в одну базу данных.
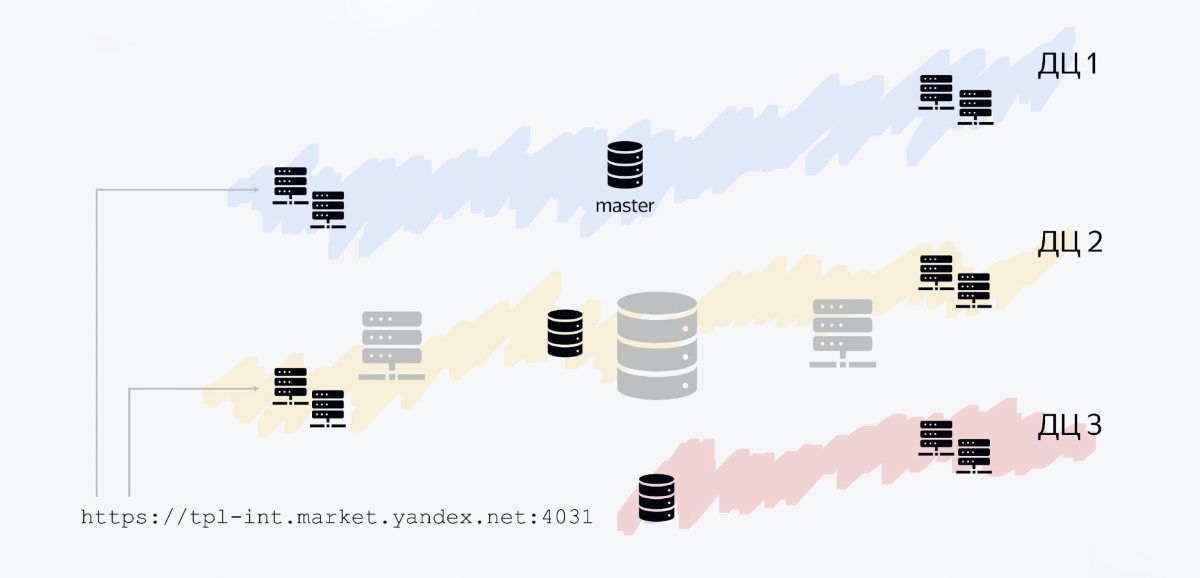
Отказоустойчивость
У Яндекса есть несколько дата-центров, и наш сервис регионально распределен по трём дата-центрам. Как это выглядит.
База данных — это три хоста, каждый в своём дата-центре. Один хост — мастер, две другие — реплики. В мастер мы пишем, с реплик читаем. Все другие Java-сервисы — это также Java-процессы, которые крутятся в нескольких дата-центрах.
Один из узлов — это наш API. Он крутится во всех трёх дата-центрах, потому что поток сообщений больше, чем из внутренних сервисов. Более того, такая схема позволяет вам довольно легко горизонтально масштабироваться.
Допустим, если у вас входящий трафик увеличится в девять раз, вы можете провести оптимизацию, но также вы можете «залить» это дело железом, открыв больше узлов, которые будут обрабатывать входящий трафик.
Балансеру придётся просто делить трафик на большее количество точек, которые выполняют запросы. И у нас сейчас, например, не один узел, а по два узла в каждом дата-центре.
Наша архитектура позволяет справляться даже с такими случаями, как отключение одного из дата-центров. Например, мы решили провести учения и отключили дата-центр во Владимире, — и наш сервис остаётся на плаву, ничего не меняется. У нас исчезают хосты базы данных, которые лежат там, а сервис остаётся в работе.
Балансер понимает через какое-то время: ага, у меня не осталось ни одного живого хоста в этом дата-центре, и — больше не перенаправляет туда трафик.
Все сервисы в Яндексе устроены схожим образом, мы все умеем переживать отказ одного из дата-центров. Как это реализовано, что такое graceful degradation и как сервисы в Яндексе переносят отключение одного из дата-центров, мы уже рассказывали.
Итак, это была архитектура. А теперь начинаются истории.
История первая — про Яндекс.Ровер
Недавно у нас была Yet another Conference, там Роверу уделили много внимания. Я продолжу тему.
Как-то раз к нам пришли ребята из команды Яндекс.Ровера и предложили проверить гипотезу, что люди захотят получать заказы таким экстраординарным способом.
Яндекс.Ровер — это маленький робот размером со среднюю собачку. Туда можно положить еду, пару коробок заказов, — он поедет по городу и привезёт заказы без помощи человека. Там есть лидар, робот понимает своё положение в пространстве. Он умеет доставлять малогабаритные заказы.
И мы подумали: а почему бы и нет? Уточнили детали эксперимента: на тот момент нужно было проверить гипотезу, что людям это понравится. И мы решили довезти 50 заказов за полторы недели в очень лайтовом режиме.
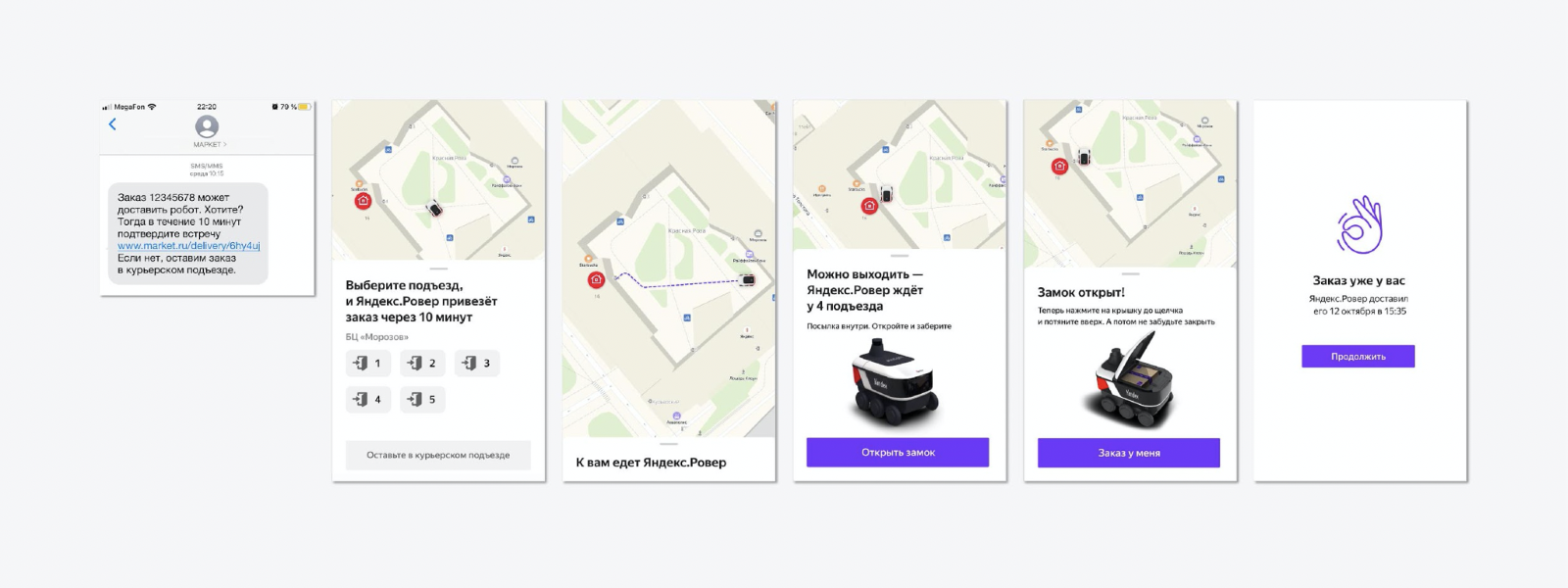
Мы придумали максимально простой флоу, когда человеку приходит SMS с предложением нестандартного способа доставки — не курьер привезёт, а Ровер. Весь эксперимент проходил во внутреннем дворе Яндекса. Человек выбирал подъезд, к которому Ровер подъедет. Когда робот приезжал — открывалась крышка, клиент брал заказ, закрывал крышку, и Ровер уезжал за новым заказом. Всё просто.
Затем мы пришли к команде Ровера, чтобы договориться про API.
В API Ровера есть простые методы: открыть крышку, закрыть крышку, поехать в такую-то точку, получить состояние. Классика. Тоже JSON. Очень просто.
Что ещё очень важно: и такие маленькие истории, и любые большие истории лучше делать через feature flags. Фактически у вас есть рубильник, по которому вы можете в production включить эту историю. Когда она вам больше не нужна, эксперимент завершен успешно или не успешно, либо заметили какие-то баги, вы просто вырубаете её. И вам не нужно делать ещё один деплой новой версии кода на прод. Эта штука здорово облегчает жизнь.
Казалось бы, всё просто и всё должно работать. Там даже две недели нечего разрабатывать, можно за несколько дней сделать. Но посмотрите, где собака зарыта.
Все процессы в основном синхронны. Человек нажимает кнопку, крышка открывается. Человек нажимает кнопку, крышка закрывается. Но один из этих процессов — асинхронный. В момент, когда Ровер к вам поедет, нужно, чтобы был какой-то фоновый процесс, который будет отслеживать, что робот вернулся на точку.
И в этот момент мы отправим SMS человеку, например, что Ровер ждёт на месте. Это невозможно сделать синхронно, и нужно как-то решить эту проблему.
Есть много разных подходов. Мы сделали максимально простой вариант.
Мы решили, что можно запустить самый обычный фоновый Java-тред либо задачу в Executer. Этот фоновый тред тут же запускается отслеживать процесс. И как только процесс выполнен, мы отправляем уведомление.
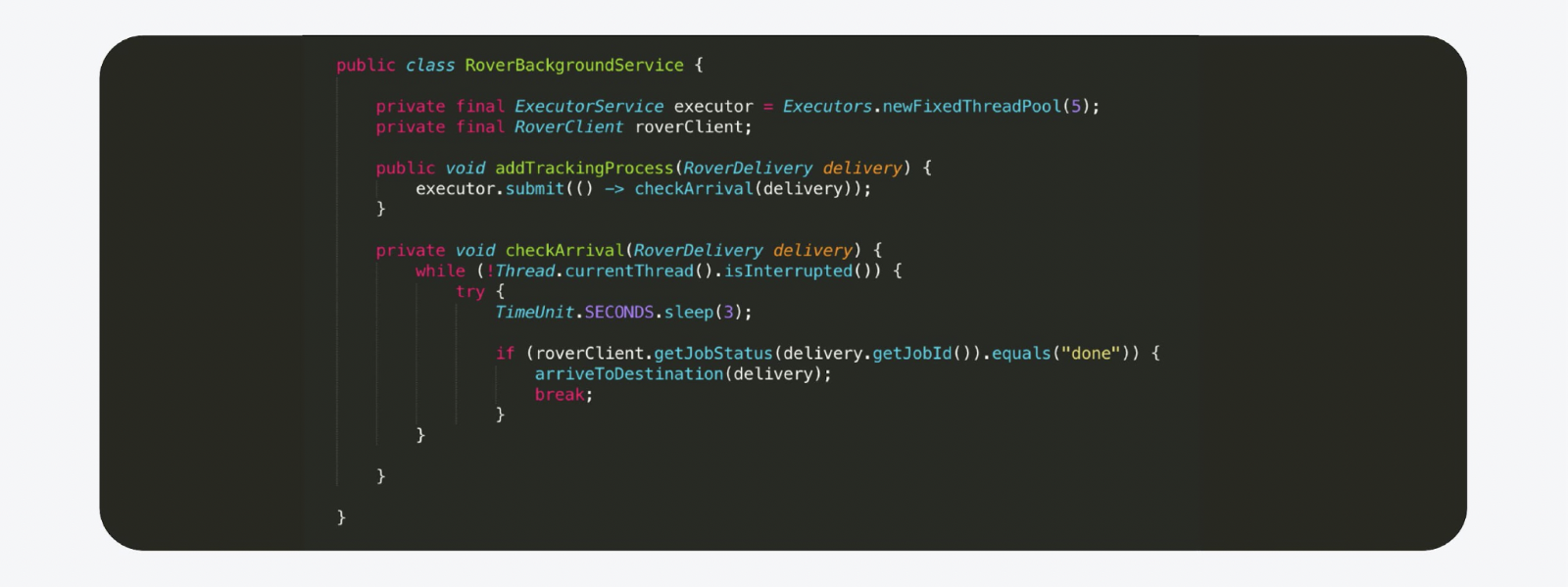
Выглядит это, например, так. Это практически копия кода с production, за исключением вырезанных комментариев. Но есть подвох. Нельзя делать таким образом серьёзные системы. Допустим, мы выкатываем новую версию на бэкенд. Хост перезагружается, состояние теряется, и всё, Ровер уезжает в бесконечность, его больше никто не видит.
Но почему? Если мы знаем, что наша цель — доставить 50 заказов за полторы недели, мы сами выбираем время, когда следим за бэкендом. Если что-то пойдёт не так, можно вручную что-то изменить. Для такой задачи это решение более чем достаточное. И в этом кроется мораль первой истории.
Существуют ситуации, для которых нужно делать минимальную версию функционала. Не нужно огород городить и овер-инжинирить. Лучше делать максимально отчуждаемо. Так, чтобы не очень сильно изменять логику внутренних объектов. И избыточная сложность, ненужный технический долг не накапливались.
История вторая — про базы данных
Но сначала несколько слов о том, как устроены основные сущности. Есть сервис Яндекс.Маршрутизация, который в конце дня строит маршруты курьерам.
Каждый маршрут состоит из точек на карте. И на каждой точке у курьеров есть задание. Это может быть задание выдать заказ, или позвонить клиенту, или с утра загрузиться на сортировочном центре, забрать все заказы.
Помимо этого, клиенты с утра получают ссылку с трекингом. Они могут открыть карту и увидеть, как к ним едет курьер. Клиент также может выбрать доставку Ровером, про который я говорил ранее.
Теперь давайте посмотрим, как эти сущности можно показать в базе данных. Это делается, например, вот так.
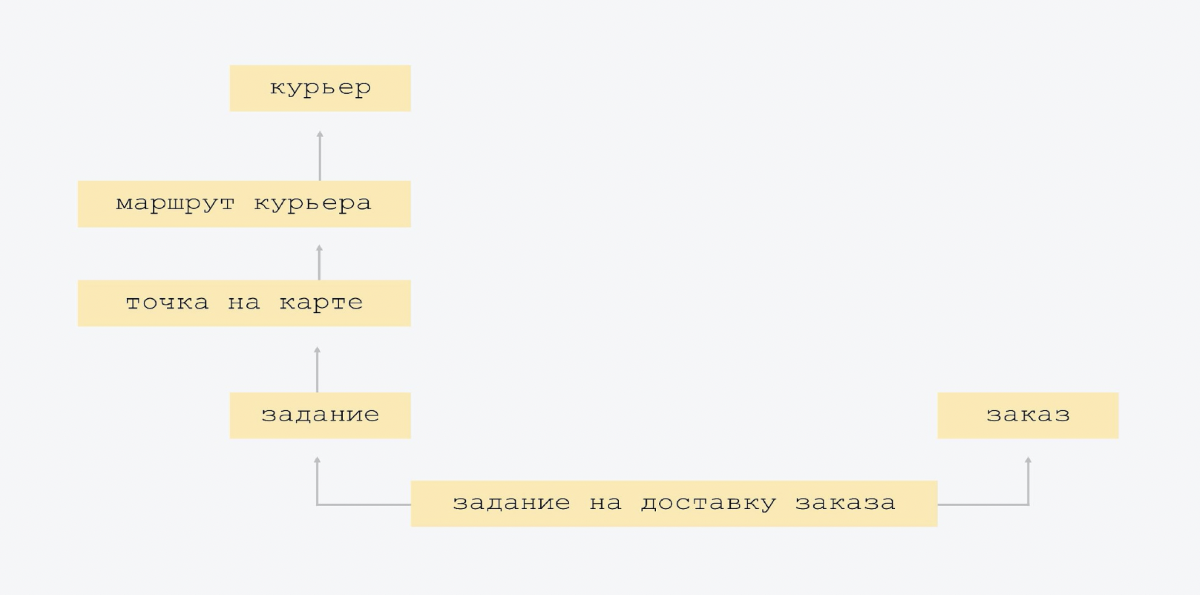
Это очень аккуратная модель данных. Мы не придумали ни одной новой сущности, и сильно не схлопывали уже существующие.
На схеме видно, что стрелочка снизу вверх показывает маршрут курьера, знает того курьера, чей это маршрут. В табличке «маршрут курьера» есть ссылка «курьер ID». А верхняя табличка этого не знает. У нас максимально простая связанность, нет большого пересечения сущностей. Когда все знают про всех, это сложнее контролировать, и, скорее всего, будет избыточность. Поэтому у нас максимально простая схема.
Единственное «излишество», которое мы сделали в самом начале создания платформы, такое. У нас был один вид заданий на доставку. Но мы поняли, что в будущем появятся другие задания. И мы заложили небольшую архитектурную гибкость: у нас есть задания, и одно из видов заданий — доставка заказа.
Затем добавили трекинг и Ровер. Всего лишь по две таблички. В трекинге — курьер отправляет свои координаты, мы их фиксируем в отдельной табличке. И есть трекинг заказа со своей моделью состояний, есть дополнительные штуки, типа «SMS ушла / не ушла». Не стоит это добавлять прямо в задание. Лучше вынести в отдельную табличку, ведь этот трекинг нужен не для всех типов заданий.
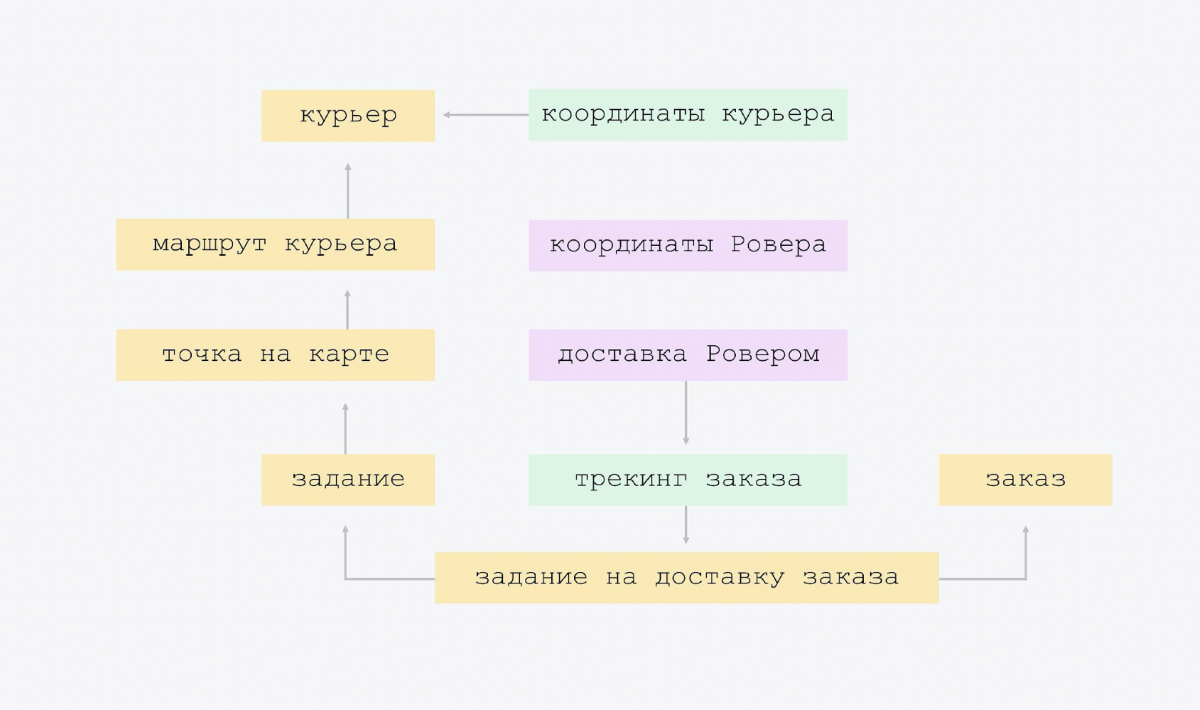
В Ровере — его координаты и доставка. У нас доставка Ровером — это трекинг как бы для Ровера. Можно его добавить в трекинг заказа, но зачем? Ведь когда мы избавимся от этого эксперимента, когда он будет выключен, эти опции навсегда останутся в сущности трекинга. Там будут null-поля.
Может возникнуть вопрос: а зачем делать табличку с координатами? Один Ровер доставляет пять заказов в день. Не нужно хранить координаты в базе данных, — можно просто ходить в API Ровера и получать их на runtime.
Суть в том, что так и было сделано изначально. Этой таблички не было, мы сразу ходили на сервис и всё это брали. Но во время тестов мы увидели, что много людей открывают карту с катящимся Ровером, и нагрузка на этот сервис кратно возрастает. Допустим, семь человек открыли. А там на страничке каждые две секунды Java Script запрашивает координаты. И коллеги нам писали в чат: «Откуда такая нагрузка? У вас же там один человек должен кататься».
И после этого мы добавили табличку. Начали складывать туда координаты, время, в которое они были получены. И теперь, если к нам слишком часто приходят за координатами и не прошло ещё две секунды с последнего получения, мы берём их из таблички. Получается такой кэш на уровне баз данных.
Эту историю можно было сделать с помощью 20 таблиц. Можно было использовать две таблицы: курьер и заказ. Но в первом случае это был бы over-engineering, а во втором случае это было бы слишком сложно поддерживать. Сложная логика, сложно тестировать.
И ещё. Структура баз данных, которую мы сделали полтора года назад, ядро этих сущностей осталось до сих пор неизменным. И нам очень сильно повезло, что мы смогли выбрать такие сущности, на которых основу не пришлось переделывать. Не пришлось значительно перекраивать базы данных, делать сложные миграции, затем катить этот релиз, очень долго его тестировать и потом менять именно корневую структуру.
Суть истории в том, что есть аспекты, которым лучше уделять дополнительное внимание. Первое — особое внимание уделяйте структуре API и БД. Старайтесь замечать, какие у вас сущности есть в реальной жизни. Пытайтесь переложить эту структуру примерно таким же образом в цифровом виде. Старайтесь не сильно её сокращать, не сильно расширять.
Второе — есть ошибки, исправление которых стоит дорого. Ошибки на уровне API исправлять сложнее, чем ошибки на уровне баз данных, потому что обычно API пользуется много клиентов. И когда вы сильно меняете API, вам придётся:
- дойти до всех клиентов, обеспечить обратную совместимость;
- выкатить новый API, всех клиентов переключить на новый API;
- выпилить старый код о клиентах, выпилить старый код на бэкенде.
Это очень затратно.
Ошибки в коде по сравнению с этим — вообще ерунда. Код вы просто переписали, прогнали тесты. Тесты зелёные — вы запушили в мастер. А вот API базы данных уделяйте особое внимание.
И как бы вы хорошо ни старались следить за базой данных, через какое-то время она превратится во что-то неуправляемое. На скрине вы видите одну десятую часть нашей базы данных, которая сейчас существует.
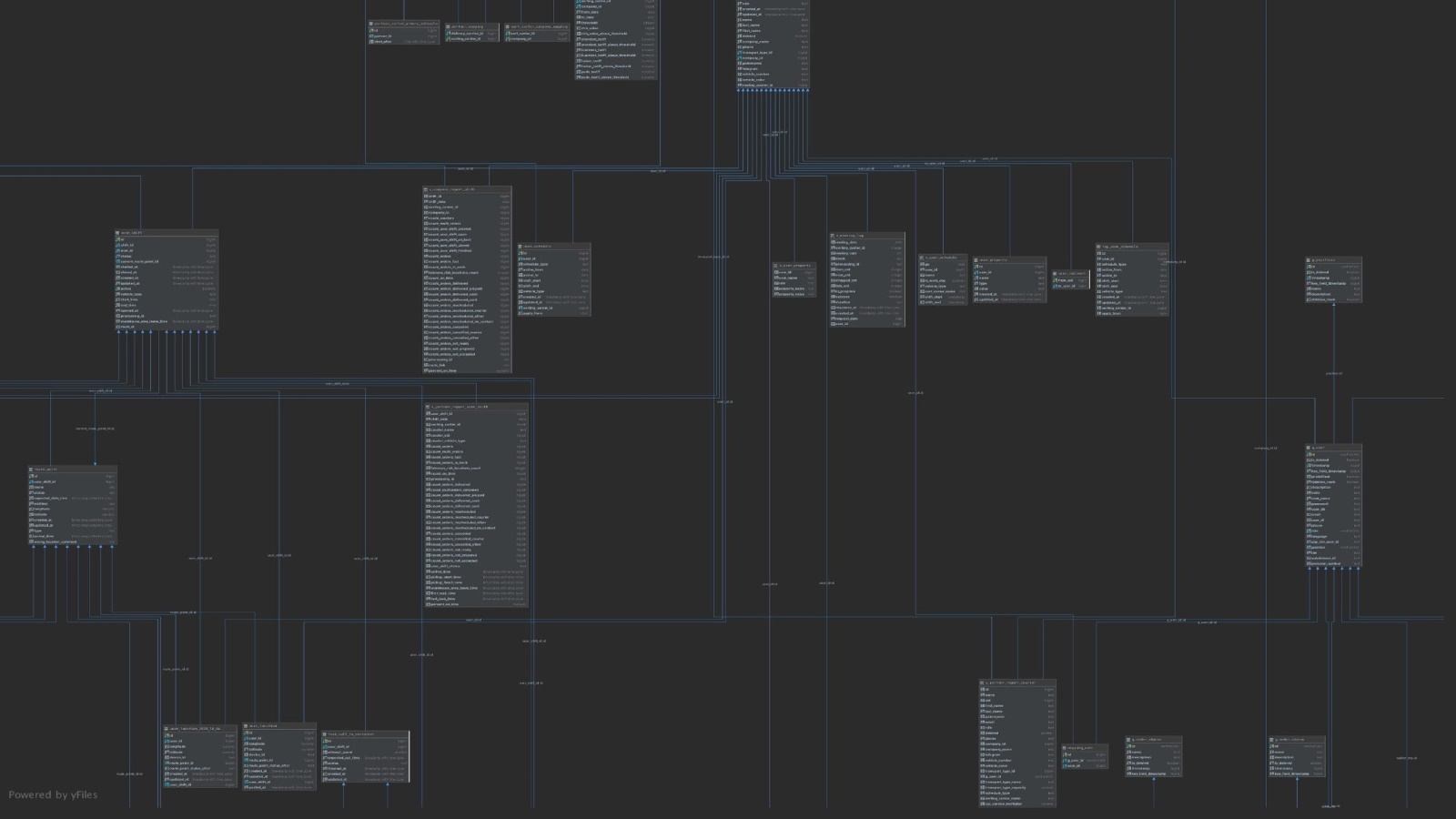
Есть один совет. Когда вы очень быстро разрабатываете что-то, в базе данных возникают неточности, иногда не хватает внешнего ключа или появляется дубль поля. Поэтому иногда, раз в два-три месяца, просто смотрите только на базу. Та же Intellij IDEA умеет генерировать классные схемы. И там это всё видно.
Ваша база данных должна быть адекватной. Очень легко за час сделать список из шести тикетов: здесь добавить внешний ключ, там индекс. Как бы вы ни старались, какой-то мусор неизбежно будет накапливаться.
История третья — про качество
Есть вещи, которые лучше с самого начала делать хорошо. Важно действовать по принципу «нормально делай — нормально будет».
Например, у нас есть один процесс, который крайне важен для платформы. Весь день мы набираем заказы на завтрашний день, но вечером срабатывает пометка, что после 22:00 мы не набираем заказы, а до 01:00 готовимся к завтрашнему дню. Потом начинается распределение заказов по сортировочным центрам. Мы идём в Яндекс.Маршрутизацию, она строит маршруты.
И если эта подготовительная работа сорвётся, весь завтрашний день под вопросом. Завтра курьерам некуда будет ехать. У них не создано состояние. Вот это в нашей платформе самый критичный процесс. И такие важные процессы нельзя делать по остаточному принципу, с минимальными ресурсами.
Я помню, у нас было время, когда этот процесс сбоил, и несколько недель чуть ли не половина команды в чате решала эти проблемы, все спасали положение, что-то переделывали, перезапускали.
Мы понимали, что если процесс не завершится с десяти вечера до часу ночи, то сортировочные центры даже не будут знать, как им сортировать заказы, на какие кучки. Там будет всё простаивать. Курьеры выйдут позже, и у нас будут провалы по качеству.
Такие процессы лучше сразу делать максимально хорошо, продумывая каждый шаг, где может что-то пойти не так. И подкладывать везде максимальное количество соломки.
Расскажу про один из вариантов, как можно настроить такой процесс.
Процесс этот многосоставный. Расчёт маршрутов и их публикацию можно разбить на части и, например, создать очереди. Тогда у нас есть несколько очередей, которые отвечают за законченные участки работы. И есть consumer на этих очередях, которые сидят и ждут сообщения.
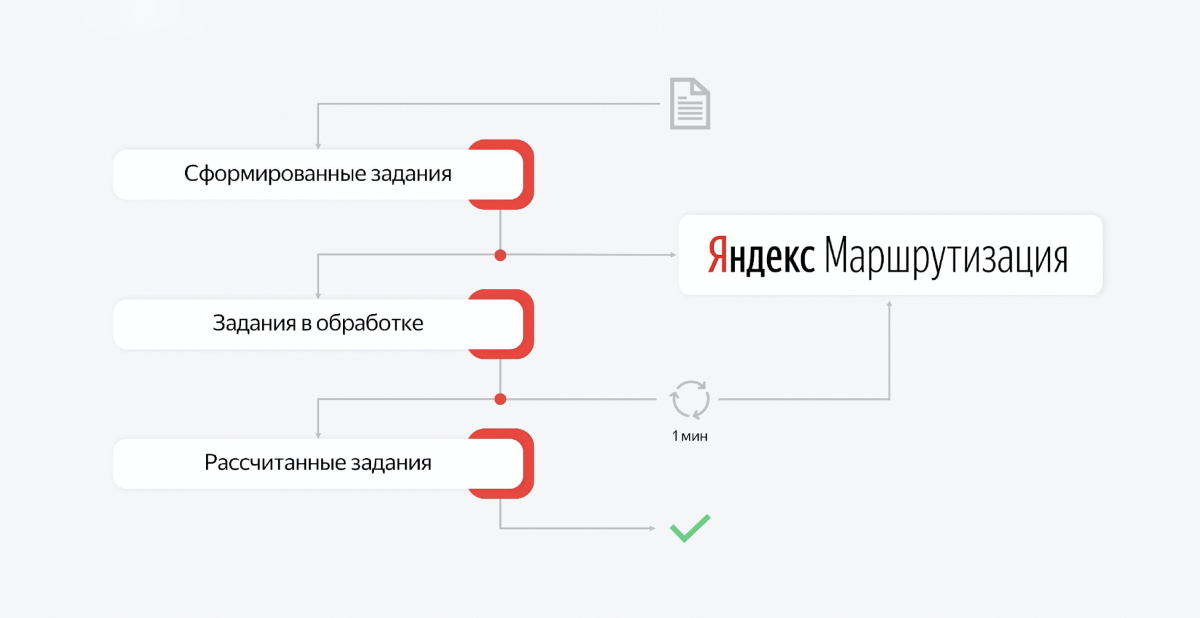
Например, день закончился, мы хотим рассчитать маршруты на завтра. Мы отправляем запрос в первую очередь: сформируй задание и запусти расчёт. Consumer забирает первое сообщение, идёт в сервис маршрутизации. Это асинхронный API. Consumer получает ответ, что задача взята в работу.
Он кладёт этот ID в базу, а в очередь с заданиями в обработке кладет новое задание. И всё. Из первой очереди сообщение исчезает, «просыпается» второй consumer. Он берёт второе задание на обработку, и его задача — регулярно ходить в маршрутизацию и проверять, не выполнилась ли еще эта задачка на расчёт.
Задача уровня «создай маршруты для 200 курьеров, которые развезут несколько тысяч заказов в Москве» занимает от получаса до часа. Это действительно очень сложная задача. И ребята из этого сервиса очень крутые, они решают сложнейшую алгоритмическую задачу, которая требует большого количества времени.
В итоге consumer второй очереди будет просто проверять, проверять, проверять. Через какое-то время задача выполнится. Когда задача выполняется, мы получаем ответ в форме нужной структуры завтрашних маршрутов и смен для курьеров.
Мы кладём то, что рассчиталось, в третью очередь. Сообщение исчезает из второй очереди. И «просыпается» третий consumer, берёт этот контекст с сервиса Яндекс.Маршрутизация и на его основе создаёт state завтрашнего дня. Он создаёт задания курьеров, он создаёт заказы, создаёт смены. Это тоже немалая работа. Он тратит на это какое-то время. И когда всё создано, эта транзакция завершается и задание из очереди удаляется.
Если на любом участке этого процесса что-то идёт не так, сервер перезагружается. При последующем восстановлении мы просто увидим тот момент, на котором мы закончили. Допустим, прошла первая фаза и вторая. И перейдём к третьей.
С такой архитектурой последние месяцы у нас всё идёт довольно гладко, проблем нет. Но раньше был сплошной try-catch. Непонятно, где процесс сбоился, какие статусы поменяли в базе данных и так далее.
Есть вещи, на которых лучше не экономить. Есть вещи, с которыми вы сэкономите себе кучу нервных клеток, если сразу сделаете всё хорошо.
Что мы сделали в офлайне
Я описал бо́льшую часть того, что происходит на нашей платформе. Но кое-что осталось за кадром.
Мы узнали про софт, который помогает курьерам развезти заказы в рамках дня. Но кто-то должен эти кучки для курьеров сделать. В сортировочном центре люди должны рассортировать большую машину заказов по маленьким кучкам. Как это делается?
Это вторая часть платформы. Мы сами написали весь софт. У нас теперь есть терминалы, с помощью которых кладовщики считывают код с коробочек и кладут их в соответствующие ячейки. Там довольно сложная логика. Этот бэкенд не сильно проще, чем тот, про который я уже рассказывал.
Эта вторая часть пазла была необходима, чтобы вместе с первой дать возможность распространять процесс на другие города. Иначе нам пришлось бы в каждом новом городе искать подрядчика, который смог бы наладить обмен какими-нибудь экселями по почте, либо интегрироваться с нашим API. И это было бы очень долго.
Когда у нас есть первая и вторая часть пазла, мы просто можем арендовать какое-то здание, нанять курьеров на машинах. Сказать им, как нажимать, что нажимать, как пикать, какую коробку куда класть, — и всё. Благодаря этому мы уже запустились в семи городах, у нас больше десяти сортировочных центров.
И открытие нашей платформы в новом городе по времени занимает совсем немного. Более того, мы научились не только развозить заказы по конкретным людям. Мы умеем с помощью курьеров привозить заказы в пункты выдачи. Мы также написали софт для них. И на этих точках тоже выдаём заказы людям.
Итоги
В начале я говорил, зачем мы начинали создавать собственную курьерскую платформу. Теперь расскажу, чего мы достигли. Это невероятно, но при использовании нашей платформы мы смогли приблизиться почти к 100% попадания в интервал. Например, за последнюю неделю качество доставляемости в Москве было порядка 95–98%. Это значит, что в 95–98% случаев мы не опаздываем. Мы укладываемся в интервал, который выбрал клиент. И мы даже не могли мечтать о такой точности, когда полагались исключительно на внешние службы доставки. Поэтому сейчас мы постепенно распространяем нашу платформу на все регионы. И будем улучшать доставляемость.
Мы получили нереальную прозрачность. Эта прозрачность нужна и нам. У нас всё логируется: все действия, весь процесс выдачи заказа. У нас есть возможность вернуться в историю на пять месяцев и сравнить какую-то метрику с текущей.
Но также мы дали эту прозрачность клиентам. Они видят, как к ним едет курьер. Они могут взаимодействовать с ним. Им не нужно звонить в службу поддержки, говорить: «Где мой курьер?»
Вдобавок получилось оптимизировать издержки, потому что у нас есть доступ ко всем элементам цепочки. В итоге сейчас довезти один заказ стоит на четверть дешевле, чем это было раньше, когда мы работали с внешними службами. Да, траты на доставку заказа уменьшились на 25%.
И если обобщать все идеи, о которых шла речь, можно выделить следующее.
Вы должны чётко понимать, на каком этапе развития находится ваш текущий сервис, ваш текущий проект. И если это состоявшийся бизнес, которым пользуются миллионы людей, которым пользуются, возможно, в нескольких странах, вы не можете всё делать на таком уровне, как с Ровером.
Но если у вас эксперимент… Эксперимент отличается тем, что в любой момент, если мы не показываем обещанных результатов, нас могут закрыть. Не взлетело. И это нормально.
И в таком режиме мы находились около десяти месяцев. У нас были отчётные интервалы, каждые два месяца мы должны были показывать результат. И у нас всё получилось.
В таком режиме, мне кажется, вы не имеете права делать что-то, инвестируя в long-term и не получая ничего на короткой дистанции. Столь сильно закладываться на будущее в таком формате работы нельзя, потому что будущее может просто не наступить.
И любой грамотный разработчик, технический руководитель должен постоянно выбирать между тем, чтобы сделать на костылях или сразу строить космолёт.
Если говорить коротко, постарайтесь делать максимально просто, но оставляя возможности для расширения.
Есть первый уровень, когда нужно делать совсем просто. А есть первый уровень со звёздочкой, когда ты делаешь просто, но оставляешь хотя бы немного пространства для манёвра, чтобы это можно было расширить. При таком мышлении, мне кажется, результаты будут гораздо лучше.
И последнее. Я рассказывал про Ровер, что хорошо подобные процессы делать с помощью feature flags (фиче-флагов). Советую послушать доклад Марии Кузнецовой с митапа по Java. Она рассказывала, как устроены фиче-флаги в нашей системе и мониторинге.
