
Рано или поздно сервисы растут, а с большим RPS приходит Highload.
Что делать, когда ресурсов для вертикального масштабирования Redis уже нет, а данных меньше не становится? Как решить эту задачу без downtime и стоит ли её решать с помощью redis-cluster?
На воркшопе Redis Python based cluster Савва Демиденко и Илья Сильченков пробежались по теории алгоритмов консенсуса и попробовали в реальном времени показать, как можно решить проблему с данными, воспользовавшись sharding’ом, который уже входит в redis-cluster.
Воркшоп растянулся на два часа. Внутри этого поста — сокращённая расшифровка самых важных мыслей.
Немного о тех, кто провёл воркшоп, и почему вообще его решили провести.
 Савва Демиденко
Савва Демиденко
Занимаюсь разработкой в Avito, делаю программу курса «Мидл Python-разработчик» от Яндекс.Практикума. Закончил Бауманку и Технопарк. Разрабатываю на Python и Golang. Люблю решать архитектурные задачи в веб-программировании.
 Илья Сильченков
Илья Сильченков
Тимлид в «Сбермаркете» и наставник на курсе «Мидл Python-разработчик». Успел побыть фронтендером и дата-инженером, но остановился на бэкенде. Сейчас пишу на Python и Go.
В рамках нашего курса в «Яндекс.Практикуме» в течение шести месяцев мы делаем онлайн-кинотеатр из множества микросервисов. Сначала пишем маленькую ETL из Elasticsearch и Flask, потом — админку и асинхронное API, авторизацию/аутентификацию и систему уведомлений. В том числе есть маленькая продуктовая задача — пиар в социальных сетях.
Как известно, у Twitter есть смешное ограничение на количество символов. Часто пользователи сокращают ссылки. Один из сервисов нашего курса вставляет ссылку в простенький API, а тот её сокращает и отдаёт обратно.
Для решения этой задачи мы взяли простой стек с прицелом на Python-разработку: FastAPI, асинхронный фреймворк pydantic для валидации и Redis в качестве хранилища данных. Redis суперпростой, однопоточный и отдаёт данные за константное время. Кажется, чтобы сохранить ссылку и достать её, большего и не надо.
К сожалению, с большим RPS приходит highload — то состояние инфраструктуры, которое требует, чтобы ее оптимизировали и масштабировали. Сегодня мы будем решать задачу, когда наше хранилище, а именно Redis, больше не вмещается на одну серверную железку, поэтому нужно придумать, как разъезжаться.
Переезд на другое хранилище — дорогостоящая операция. Почитайте статьи, как Uber переезжал с MySQL на PostgreSQL — там всё ужасно. Речь про события 2013 года: из-за отрицательных результатов через три года в инфраструктуре Uber провели обратный переход. Смена хранилища под нашим сервисом — это последнее, к чему можно прийти.
Перед этим важно понять, как мы расходуем ресурсы, и попробовать оптимизировать хранение данных — перенести какие-то данные в холодное хранилище или удалить. Возможно, мы забывали чистить за собой память, и она засорилась. После всех оптимизаций нужно двигаться в сторону масштабирования.

В итоге хранилище превращается в несколько Redis-машин. До начала работы с практической задачей нужно разобраться с академической стороной вопроса.
Посмотрим, что такое распределённые системы с точки зрения computer science. Это важно понять, потому что от вас ожидают готовое решение, которое будет работать «из коробки». Для этого нужно не наступать на чужие грабли, а теория как раз позволяет их обойти.

Самое простое определение распределённой системы предлагает Лесли Лампорт, создатель алгоритма Паксос. Распределённая система — система, в которой отказ машины, о которой вы даже не подозревали, может превратить ваш компьютер в тыкву. При этом неважно, какая проблема с системой в этом виновата: сеть, электричество или ретроградный Меркурий.
Из этого определения следует, что любой веб-сайт — это распределённая система. В схеме его работы есть устройство клиента и хост-машина, на которую оно ходит. Если хост упадёт, то сайт работать не будет.
Неужели любая система, в которой участвует больше двух железок, распределённая? Почти.
Разберём на примере Redis Cluster. В нём появляются подвиды распределённых систем, для классификации которых потребуется теорема CAP. В ней описывается главное свойство распределённых систем — консистентность.
Википедия превращает консистентность в три отдельных понятия: «…согласованность данных друг с другом, целостность данных, а также внутренняя непротиворечивость».
Рассмотрим пример с обычной реляционной базой данных социальной сети. В ней есть таблица с пользователями и отдельно таблица с друзьями (парами ID). В этом случае целостность означает, что в таблице с парами связей не будет айдишек, которых нет в таблице с пользователями. А если пользователь удалится, то пары с ним либо тоже удалятся, либо не будут учитываться.
Связность означает, что если первый пользователь находится у второго в друзьях, то и второй находится в друзьях у первого. Пары связей согласуются друг с другом. Правило непротиворечивости требует, что если один пользователь удалит другого, то вся связь также будет удалена.

На деле консистентность бывает разной. То, что этом большом дереве с Jepsen.io выделено зелёным — это какой-то вид нормальной консистентности, а всё под ним — технические детали, которые к этому приближают.
В теореме CAP используется линеаризуемая консистентность — linearazable. Приведём пример, когда это свойство отсутствует.

Допустим, что в распределённой системе есть три ноды: leader и две follower. Судья сказал, что Германия победила в футбольном матче. Insert произошёл на leader, на что тот ответил успехом записи, но раскатал изменения не на всех follower сразу. Алиса зашла и увидела победу Германии, а Боб видит, что матч ещё продолжается — изменение дошло не до всех follower. Если бы в этой системе консистентность была линеаризуемая, то оба участника прочитали бы про победу Германии. Для linearazable-консистентности важно, чтобы лидер ноды отвечал успехом уже после раскатывания на все ноды.
Второе свойство — partition tolerance, или устойчивость к разделению сети или сетевой нестабильности. Например, есть два узла, связанные кабелем. Если его перерубить, то произойдёт то самое разделение сети. Останется два контура со множеством серверов в каждом. Каждой ноде придётся самостоятельно решать, как обеспечивать два другие свойства теоремы CAP. Устойчивость означает, что система знает, как работать в такой ситуации.
Последнее свойство — доступность, или availability. Система ответит быстро, но без гарантии, что быстро и свежими данными. Линейная консистентность не ожидается.

Теорема CAP утверждает принцип тройственной ограниченности: можно получить только два свойства из трёх. Системы делятся на CP, CA и AP. Все системы пытаются покрыть сразу два свойства, а не одно.
Рассмотрим самые простые примеры. В PostgreSQL в синхронной репликации leader и follower связаны жёстко, то есть leader закроет транзакцию только после получения ответа от follower. Если кабель между ними разорвётся, то перестанут работать оба. В теореме CAP такой схеме работы соответствует консистентность и доступность (CA).
В случае асинхронной репликации изначально предусмотрен gap, и может случиться тот самый случай с футбольным матчем. При проблемах с сетью реплики продолжат отвечать в предусмотренное окно. При этом данные будут не самыми свежими. Такая система называется AP: она устойчива к разделению сети и обеспечивает доступность, но не консистентность.
Получается, каждый раз при решении задачи нужно посмотреть в теорему CAP, чтобы выбрать нужные свойства.
PACELC пришла на смену теореме CAP и расширяет её. В ней получается четыре вида систем.

В правом верхнем углу — системы PC/EC, которые всегда выбирают консистентность. Это банки, самолёты и другие надёжные системы.
Кому это не нужно, идут в левый нижний угол — в системы PA/EL. При нарушении сетевой связности (partition) обеспечивается доступность, а в противном случае — скорость ответа (latency). Пример подобной системы — Amazon в «чёрную пятницу». Компания готова возвращать деньги покупателям, одаривать их купонами, дозаказывать товар, но главное — чтобы в этот день клиенты всё заказали. Неважно, будет ли всё в наличии, важно, чтобы можно было оформить заказ.
В левом верхнем углу — системы PA/EC. В случае разбиения сети нужна доступность, в другом случае — консистентность. По данному принципу работает MongoDB, хотя иногда она ближе к системе PC/EC. Если происходит разбиение, возможны нарушения консистентности.
Единственная известная система, которая работает по PC/EL, — поисковик Yahoo. При разбиении нод он выбирает консистентность, потому что ему важно сохранить данные и отвечать единообразно. При отсутствии проблемы он выбирает latency, чтобы быстро давать ответ. Когда всё работает хорошо, поисковики могут игнорировать небольшую неконсистентность уровня секунд и минут.
Redis нельзя рассматривать в теореме CAP. Всё же это однонодовая штука, а теорема CAP — распределённая система хранения данных. Можно рассматривать это как распределённую систему с навешенным поверх сайтом: много нод и кода ходят в один Redis. И получится система CA: если между сайтом и Redis не будет сети, всё упадёт, но при этом каждая нода всё равно будет доступна.
Многие используют Redis в качестве кэширующего слоя. Реже в этой роли выступает Memcached. Но он живёт только в памяти, а комьюнити Redis отлично развивается.
В курсе «Мидл Python-разработчик» мы используем Redis Cluster в асинхронном API. Мы уже разбираем механизмы работы с нодами и как правильно их масштабировать.
Тема непростая, но несколько докладов от Amazon разъясняют, как всё нужно делать, — их вы найдёте в конце поста. Мы далеко не первопроходцы — R&D департамент Amazon это сделал уже в 2007 году.
Итак, в теореме CAP Redis Cluster — это P. Почему только P, без ещё одной буквы?

Обычно так случается, когда кто-то не до конца разобрался с темой и решил разработать собственное решение. Ребята из Jepsen.io провели анализ и сказали, что система устойчива к разделению. При этом она пытается вести себя как кластер. И если половина нод недоступна, работать она уже не может. Это говорит, что Redis Cluster — не система AP.
Остаётся одна P. Если мы используем WAIT, который приделали позже, когда дочитали теорию, Redis Cluster станет CP.
Разработка распределённых систем и проверка консистентности — хорошая инженерная задача. Во время анализа нужна какая-то аналогия для ума человека. Задача об обедающих философах — хороший тому пример. Здесь будет аналогия в виде островов и мостов между ними.
Острова живут как одно государство с общим сводом законов. И каждый остров хочет влиять на эти законы. Но не съездом в одном замке с разносом коронавируса, а пересылкой гонцов, как курьеров с едой. И перемещаться между островами они будут по мостам.
На каждом острове мы будем хранить свой свод законов, но с блокировкой изменений ото всех. Важно понимать, что здесь нужен консенсус на чтение и консенсус на запись. Обязательно оговорим, со скольких островов нужно получить информацию, чтобы заявить, что закон работает на 100%. Нужно знать, сколько гонцов необходимо послать на другие острова, чтобы убедиться, что закон записан и теперь мы ему будем следовать.
Чтение — это сбор логов изменения законов к себе. Запись — этот лог изменения законов мы куда-то везём. Именно это — два консенсуса: на чтение и запись.
Если поменять острова на серверы, ничего не пропадёт: как рассуждали, так и останется.
Острова и мосты — это уже традиция. Создатель этого алгоритма Лесли Лэмпорт использует аналогию из алгоритма Паксос. Его конкретные реализации — это ZAB (Apache ZooKeeper) и Raft. Если брать алгоритм, который соответствует Паксосу, то на выходе получится CP.
Спецификации говорят, что Raft простой, но на деле понять его нелегко. На сайте raft.github.io размещена классная настраиваемая браузерная анимация, с которой мы рекомендуем поиграть.
А теперь представим, что нас есть стажёр, который в первый раз пришёл на работу и впервые видит этот код. Напомним, модуль взят из курса «Мидл Python-разработчик»: на вход получает ссылку, на выходе отдаёт новый хэш, при переходе по хэшу он его разворачивает и даёт редирект. Кажется, просто — погнали!
Заходим в readme. Здесь написано, что это код для вебинара, и описано, как запустить Docker Compose, который облегчает задачу взаимодействия сервисов между собой.

Автор сервиса оставил нам документацию — большое спасибо. Это заслуга FastAPI: документация генерируется автоматически.
У нас есть сервис и файлы конфигурации. Разберём их.

В Dockerfile всё по классике: Python через pip и pipenv, последний уже ставит всё остальное, запускается API на порт 8080.

В файле docker-compose всё просто: Redis и наше приложение на Python. Го его реализовывать.

Мы попали в начало приложения. Здесь какие-то хуки на начало и конец, startup, shutdown. И вот самое интересное: в этом router подвязаны основные ручки.
Чуть не пропустили FastAPI. Кстати, что такое FastAPI?
FastAPI — это классный современный асинхронный фреймворк на Python. Внутри него — pydantic, генерация спецификаций OpenAPI (даже третья версия, а не Swagger!). Просто берёшь и пользуешься: описываешь входные и выходные данные pydantic для валидации, даёшь готовую документацию для других юнитов.
И при этом он асинхронный, что даёт дешёвую работу по сети. Сейчас речь идёт про код, который ждёт других операций: обращения к большому файлу на диске или сетевому ресурсу.
Итак, если у нас не монолитная структура, а микросервисная, то по процессорам и серверам будет значительно дешевле брать асинхронный фреймворк, потому что у него внутри есть event loop, который будет экономить время. Не будем сильно ударяться в event loop, потому что его мы подробно разбираем на курсе — там это основа основ. Мы затрагиваем и корутины, которые идут мостиком к Golang и каналам.

Вернёмся к коду. Нам нужны функции «создать», «проверить» и «редиректнуть». Вот эти три функции.

Разберём, на мой взгляд, самую простую — создание URL. Проговорим логику:
Посмотрим, как это реализовано. Внутри метода url_repository.create_url ничего умного нет.

Присутствует околослужебная информация, что мы заинициализировались. А ещё мы отслеживаем коллизии. Вопрос с коллизиями мы решаем добавлением букв. Мы не городим список и не хэшим на ключ, а просто меняем ключ.
Во второй части поста расскажем, зачем нужен Dynamo, и что делать, когда Redis несколько.
Что делать, когда ресурсов для вертикального масштабирования Redis уже нет, а данных меньше не становится? Как решить эту задачу без downtime и стоит ли её решать с помощью redis-cluster?
На воркшопе Redis Python based cluster Савва Демиденко и Илья Сильченков пробежались по теории алгоритмов консенсуса и попробовали в реальном времени показать, как можно решить проблему с данными, воспользовавшись sharding’ом, который уже входит в redis-cluster.
Воркшоп растянулся на два часа. Внутри этого поста — сокращённая расшифровка самых важных мыслей.
Введение
Немного о тех, кто провёл воркшоп, и почему вообще его решили провести.
 Савва Демиденко
Савва ДемиденкоЗанимаюсь разработкой в Avito, делаю программу курса «Мидл Python-разработчик» от Яндекс.Практикума. Закончил Бауманку и Технопарк. Разрабатываю на Python и Golang. Люблю решать архитектурные задачи в веб-программировании.
 Илья Сильченков
Илья СильченковТимлид в «Сбермаркете» и наставник на курсе «Мидл Python-разработчик». Успел побыть фронтендером и дата-инженером, но остановился на бэкенде. Сейчас пишу на Python и Go.
В рамках нашего курса в «Яндекс.Практикуме» в течение шести месяцев мы делаем онлайн-кинотеатр из множества микросервисов. Сначала пишем маленькую ETL из Elasticsearch и Flask, потом — админку и асинхронное API, авторизацию/аутентификацию и систему уведомлений. В том числе есть маленькая продуктовая задача — пиар в социальных сетях.
Как известно, у Twitter есть смешное ограничение на количество символов. Часто пользователи сокращают ссылки. Один из сервисов нашего курса вставляет ссылку в простенький API, а тот её сокращает и отдаёт обратно.
Для решения этой задачи мы взяли простой стек с прицелом на Python-разработку: FastAPI, асинхронный фреймворк pydantic для валидации и Redis в качестве хранилища данных. Redis суперпростой, однопоточный и отдаёт данные за константное время. Кажется, чтобы сохранить ссылку и достать её, большего и не надо.
К сожалению, с большим RPS приходит highload — то состояние инфраструктуры, которое требует, чтобы ее оптимизировали и масштабировали. Сегодня мы будем решать задачу, когда наше хранилище, а именно Redis, больше не вмещается на одну серверную железку, поэтому нужно придумать, как разъезжаться.
Переезд на другое хранилище — дорогостоящая операция. Почитайте статьи, как Uber переезжал с MySQL на PostgreSQL — там всё ужасно. Речь про события 2013 года: из-за отрицательных результатов через три года в инфраструктуре Uber провели обратный переход. Смена хранилища под нашим сервисом — это последнее, к чему можно прийти.
Перед этим важно понять, как мы расходуем ресурсы, и попробовать оптимизировать хранение данных — перенести какие-то данные в холодное хранилище или удалить. Возможно, мы забывали чистить за собой память, и она засорилась. После всех оптимизаций нужно двигаться в сторону масштабирования.

В итоге хранилище превращается в несколько Redis-машин. До начала работы с практической задачей нужно разобраться с академической стороной вопроса.
Теория
Распределённые системы
Посмотрим, что такое распределённые системы с точки зрения computer science. Это важно понять, потому что от вас ожидают готовое решение, которое будет работать «из коробки». Для этого нужно не наступать на чужие грабли, а теория как раз позволяет их обойти.

Самое простое определение распределённой системы предлагает Лесли Лампорт, создатель алгоритма Паксос. Распределённая система — система, в которой отказ машины, о которой вы даже не подозревали, может превратить ваш компьютер в тыкву. При этом неважно, какая проблема с системой в этом виновата: сеть, электричество или ретроградный Меркурий.
Из этого определения следует, что любой веб-сайт — это распределённая система. В схеме его работы есть устройство клиента и хост-машина, на которую оно ходит. Если хост упадёт, то сайт работать не будет.
Неужели любая система, в которой участвует больше двух железок, распределённая? Почти.
Разберём на примере Redis Cluster. В нём появляются подвиды распределённых систем, для классификации которых потребуется теорема CAP. В ней описывается главное свойство распределённых систем — консистентность.
Википедия превращает консистентность в три отдельных понятия: «…согласованность данных друг с другом, целостность данных, а также внутренняя непротиворечивость».
Рассмотрим пример с обычной реляционной базой данных социальной сети. В ней есть таблица с пользователями и отдельно таблица с друзьями (парами ID). В этом случае целостность означает, что в таблице с парами связей не будет айдишек, которых нет в таблице с пользователями. А если пользователь удалится, то пары с ним либо тоже удалятся, либо не будут учитываться.
Связность означает, что если первый пользователь находится у второго в друзьях, то и второй находится в друзьях у первого. Пары связей согласуются друг с другом. Правило непротиворечивости требует, что если один пользователь удалит другого, то вся связь также будет удалена.

На деле консистентность бывает разной. То, что этом большом дереве с Jepsen.io выделено зелёным — это какой-то вид нормальной консистентности, а всё под ним — технические детали, которые к этому приближают.
Теорема САР
В теореме CAP используется линеаризуемая консистентность — linearazable. Приведём пример, когда это свойство отсутствует.

Допустим, что в распределённой системе есть три ноды: leader и две follower. Судья сказал, что Германия победила в футбольном матче. Insert произошёл на leader, на что тот ответил успехом записи, но раскатал изменения не на всех follower сразу. Алиса зашла и увидела победу Германии, а Боб видит, что матч ещё продолжается — изменение дошло не до всех follower. Если бы в этой системе консистентность была линеаризуемая, то оба участника прочитали бы про победу Германии. Для linearazable-консистентности важно, чтобы лидер ноды отвечал успехом уже после раскатывания на все ноды.
Второе свойство — partition tolerance, или устойчивость к разделению сети или сетевой нестабильности. Например, есть два узла, связанные кабелем. Если его перерубить, то произойдёт то самое разделение сети. Останется два контура со множеством серверов в каждом. Каждой ноде придётся самостоятельно решать, как обеспечивать два другие свойства теоремы CAP. Устойчивость означает, что система знает, как работать в такой ситуации.
Последнее свойство — доступность, или availability. Система ответит быстро, но без гарантии, что быстро и свежими данными. Линейная консистентность не ожидается.
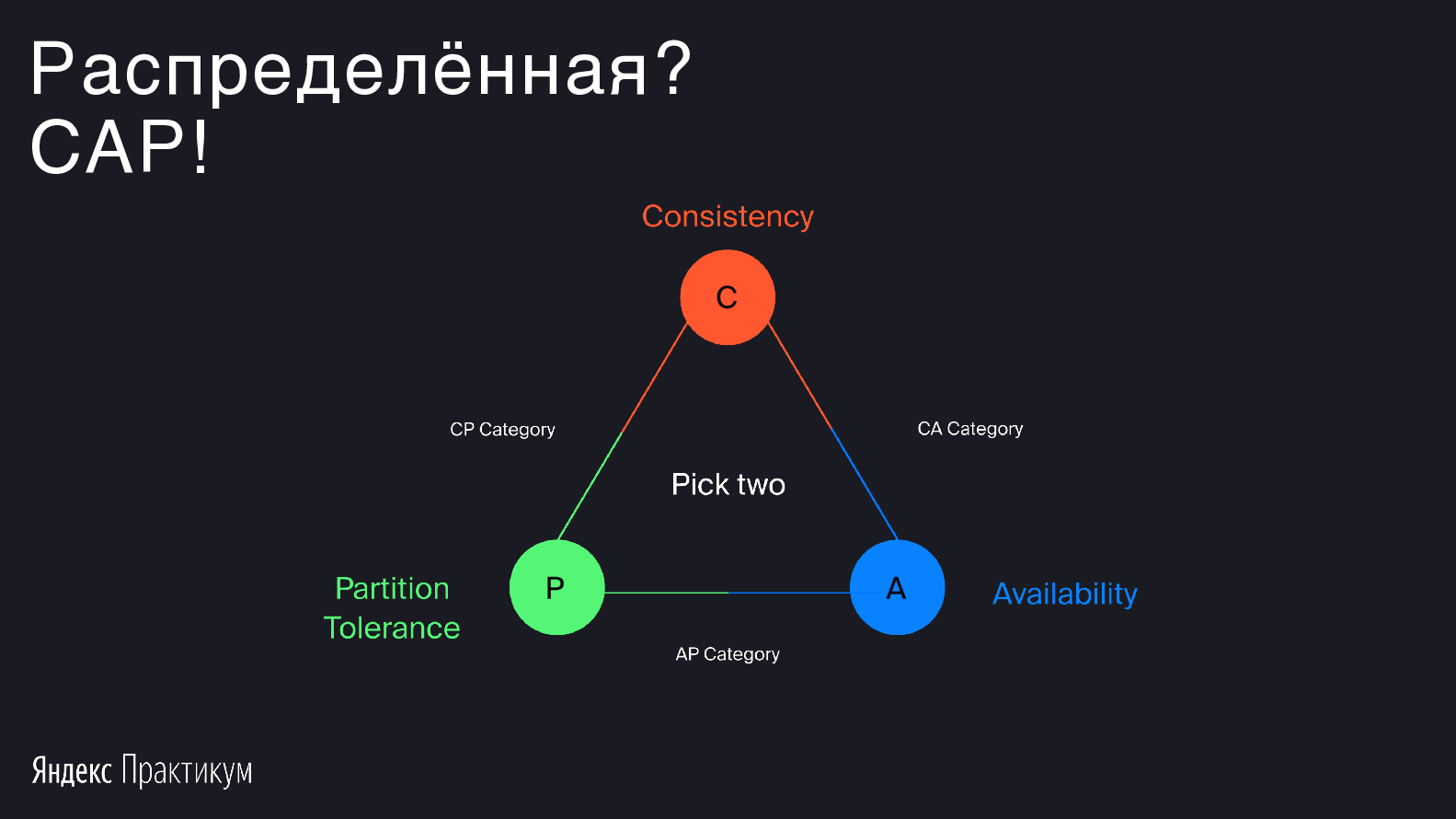
Теорема CAP утверждает принцип тройственной ограниченности: можно получить только два свойства из трёх. Системы делятся на CP, CA и AP. Все системы пытаются покрыть сразу два свойства, а не одно.
Рассмотрим самые простые примеры. В PostgreSQL в синхронной репликации leader и follower связаны жёстко, то есть leader закроет транзакцию только после получения ответа от follower. Если кабель между ними разорвётся, то перестанут работать оба. В теореме CAP такой схеме работы соответствует консистентность и доступность (CA).
В случае асинхронной репликации изначально предусмотрен gap, и может случиться тот самый случай с футбольным матчем. При проблемах с сетью реплики продолжат отвечать в предусмотренное окно. При этом данные будут не самыми свежими. Такая система называется AP: она устойчива к разделению сети и обеспечивает доступность, но не консистентность.
Получается, каждый раз при решении задачи нужно посмотреть в теорему CAP, чтобы выбрать нужные свойства.
Теорема PACELC
PACELC пришла на смену теореме CAP и расширяет её. В ней получается четыре вида систем.

В правом верхнем углу — системы PC/EC, которые всегда выбирают консистентность. Это банки, самолёты и другие надёжные системы.
Кому это не нужно, идут в левый нижний угол — в системы PA/EL. При нарушении сетевой связности (partition) обеспечивается доступность, а в противном случае — скорость ответа (latency). Пример подобной системы — Amazon в «чёрную пятницу». Компания готова возвращать деньги покупателям, одаривать их купонами, дозаказывать товар, но главное — чтобы в этот день клиенты всё заказали. Неважно, будет ли всё в наличии, важно, чтобы можно было оформить заказ.
В левом верхнем углу — системы PA/EC. В случае разбиения сети нужна доступность, в другом случае — консистентность. По данному принципу работает MongoDB, хотя иногда она ближе к системе PC/EC. Если происходит разбиение, возможны нарушения консистентности.
Единственная известная система, которая работает по PC/EL, — поисковик Yahoo. При разбиении нод он выбирает консистентность, потому что ему важно сохранить данные и отвечать единообразно. При отсутствии проблемы он выбирает latency, чтобы быстро давать ответ. Когда всё работает хорошо, поисковики могут игнорировать небольшую неконсистентность уровня секунд и минут.
При чём тут Redis
Redis нельзя рассматривать в теореме CAP. Всё же это однонодовая штука, а теорема CAP — распределённая система хранения данных. Можно рассматривать это как распределённую систему с навешенным поверх сайтом: много нод и кода ходят в один Redis. И получится система CA: если между сайтом и Redis не будет сети, всё упадёт, но при этом каждая нода всё равно будет доступна.
Многие используют Redis в качестве кэширующего слоя. Реже в этой роли выступает Memcached. Но он живёт только в памяти, а комьюнити Redis отлично развивается.
В курсе «Мидл Python-разработчик» мы используем Redis Cluster в асинхронном API. Мы уже разбираем механизмы работы с нодами и как правильно их масштабировать.
Тема непростая, но несколько докладов от Amazon разъясняют, как всё нужно делать, — их вы найдёте в конце поста. Мы далеко не первопроходцы — R&D департамент Amazon это сделал уже в 2007 году.
Итак, в теореме CAP Redis Cluster — это P. Почему только P, без ещё одной буквы?

Обычно так случается, когда кто-то не до конца разобрался с темой и решил разработать собственное решение. Ребята из Jepsen.io провели анализ и сказали, что система устойчива к разделению. При этом она пытается вести себя как кластер. И если половина нод недоступна, работать она уже не может. Это говорит, что Redis Cluster — не система AP.
Остаётся одна P. Если мы используем WAIT, который приделали позже, когда дочитали теорию, Redis Cluster станет CP.
Острова и мосты
Разработка распределённых систем и проверка консистентности — хорошая инженерная задача. Во время анализа нужна какая-то аналогия для ума человека. Задача об обедающих философах — хороший тому пример. Здесь будет аналогия в виде островов и мостов между ними.
Острова живут как одно государство с общим сводом законов. И каждый остров хочет влиять на эти законы. Но не съездом в одном замке с разносом коронавируса, а пересылкой гонцов, как курьеров с едой. И перемещаться между островами они будут по мостам.
На каждом острове мы будем хранить свой свод законов, но с блокировкой изменений ото всех. Важно понимать, что здесь нужен консенсус на чтение и консенсус на запись. Обязательно оговорим, со скольких островов нужно получить информацию, чтобы заявить, что закон работает на 100%. Нужно знать, сколько гонцов необходимо послать на другие острова, чтобы убедиться, что закон записан и теперь мы ему будем следовать.
Чтение — это сбор логов изменения законов к себе. Запись — этот лог изменения законов мы куда-то везём. Именно это — два консенсуса: на чтение и запись.
Если поменять острова на серверы, ничего не пропадёт: как рассуждали, так и останется.
Острова и мосты — это уже традиция. Создатель этого алгоритма Лесли Лэмпорт использует аналогию из алгоритма Паксос. Его конкретные реализации — это ZAB (Apache ZooKeeper) и Raft. Если брать алгоритм, который соответствует Паксосу, то на выходе получится CP.
Спецификации говорят, что Raft простой, но на деле понять его нелегко. На сайте raft.github.io размещена классная настраиваемая браузерная анимация, с которой мы рекомендуем поиграть.
Практика
А теперь представим, что нас есть стажёр, который в первый раз пришёл на работу и впервые видит этот код. Напомним, модуль взят из курса «Мидл Python-разработчик»: на вход получает ссылку, на выходе отдаёт новый хэш, при переходе по хэшу он его разворачивает и даёт редирект. Кажется, просто — погнали!
Заходим в readme. Здесь написано, что это код для вебинара, и описано, как запустить Docker Compose, который облегчает задачу взаимодействия сервисов между собой.

Автор сервиса оставил нам документацию — большое спасибо. Это заслуга FastAPI: документация генерируется автоматически.
У нас есть сервис и файлы конфигурации. Разберём их.

В Dockerfile всё по классике: Python через pip и pipenv, последний уже ставит всё остальное, запускается API на порт 8080.

В файле docker-compose всё просто: Redis и наше приложение на Python. Го его реализовывать.

Мы попали в начало приложения. Здесь какие-то хуки на начало и конец, startup, shutdown. И вот самое интересное: в этом router подвязаны основные ручки.
Чуть не пропустили FastAPI. Кстати, что такое FastAPI?
FastAPI — это классный современный асинхронный фреймворк на Python. Внутри него — pydantic, генерация спецификаций OpenAPI (даже третья версия, а не Swagger!). Просто берёшь и пользуешься: описываешь входные и выходные данные pydantic для валидации, даёшь готовую документацию для других юнитов.
И при этом он асинхронный, что даёт дешёвую работу по сети. Сейчас речь идёт про код, который ждёт других операций: обращения к большому файлу на диске или сетевому ресурсу.
Итак, если у нас не монолитная структура, а микросервисная, то по процессорам и серверам будет значительно дешевле брать асинхронный фреймворк, потому что у него внутри есть event loop, который будет экономить время. Не будем сильно ударяться в event loop, потому что его мы подробно разбираем на курсе — там это основа основ. Мы затрагиваем и корутины, которые идут мостиком к Golang и каналам.

Вернёмся к коду. Нам нужны функции «создать», «проверить» и «редиректнуть». Вот эти три функции.

Разберём, на мой взгляд, самую простую — создание URL. Проговорим логику:
- приходит запрос и валидируется на URL;
- если данные подходят — то есть они, например, непустые — мы сжимаем URL до хэша и записываем в Redis;
- потом отдаём полный путь, хэш и URL, по которому можно перейти и получить редирект.
Посмотрим, как это реализовано. Внутри метода url_repository.create_url ничего умного нет.

Присутствует околослужебная информация, что мы заинициализировались. А ещё мы отслеживаем коллизии. Вопрос с коллизиями мы решаем добавлением букв. Мы не городим список и не хэшим на ключ, а просто меняем ключ.
Во второй части поста расскажем, зачем нужен Dynamo, и что делать, когда Redis несколько.
