Здесь я расскажу, как сделать канбан-доску для проекта в Jira, пользуясь только QML и JavaScript. С небольшими доработками вместо Jira вы можете использовать любой другой трекер, имеющий REST API.
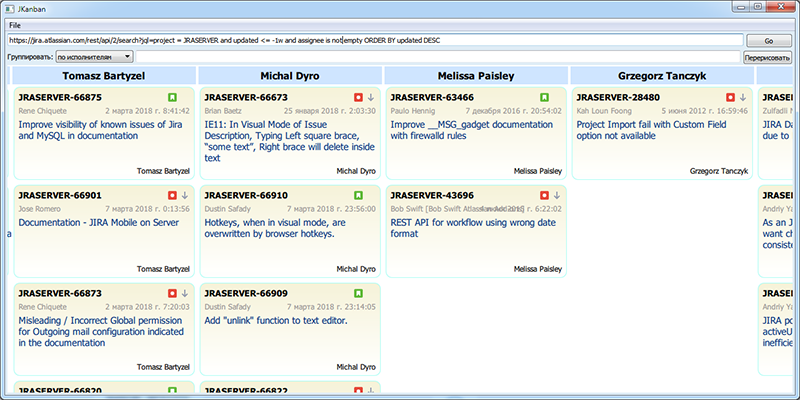
Некоторое время назад, теперь уже практически в другой жизни, в мою бытность руководителем проекта, я понял, что теряю представление о занятости участников нашего проекта. Кто-то занимается Большим и Важным делом, кто-то исправляет срочные баги, а может быть кто-то, извините, балду пинает, а я об этом не в курсе и задачи ему не ставлю. И мне захотелось иметь наглядную картинку текущих дел.
Содержание
Предыстория
Альтернативы для умных и богатых
Необходимые оговорки
Начало работы с Jira REST API
Создаем проект в Qt Creator
Рисуем дизайн карточки запроса
Описываем колонку карточек
Окно для доски
Пишем код для вызова REST API
LocalStorage для сохранения и восстановления параметров
Добавляем варианты группировки
Что дальше?
Альтернативы для умных и богатых
Необходимые оговорки
Начало работы с Jira REST API
Создаем проект в Qt Creator
Рисуем дизайн карточки запроса
Описываем колонку карточек
Окно для доски
Пишем код для вызова REST API
LocalStorage для сохранения и восстановления параметров
Добавляем варианты группировки
Что дальше?
Предыстория
Некоторое время назад, теперь уже практически в другой жизни, в мою бытность руководителем проекта, я понял, что теряю представление о занятости участников нашего проекта. Кто-то занимается Большим и Важным делом, кто-то исправляет срочные баги, а может быть кто-то, извините, балду пинает, а я об этом не в курсе и задачи ему не ставлю. И мне захотелось иметь наглядную картинку текущих дел.