
Об одном забавном подходе к фильтрации унимодальных сигналов
6 мин
В этой статье наши инженеры хотели бы поделиться с Хабром достаточно интересным инструментом, который можно эффективно применять для фильтрации зашумленных сигналов, пользуясь априорным знанием об унимодальности сигнала.
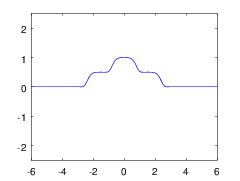
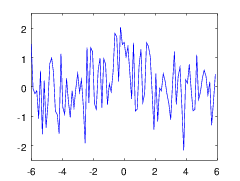
Задача оффлайновой фильтрации сигналов в случае, когда ожидаемая форма сигнала известна с точностью до нескольких неизвестных параметров, сводится к задаче аппроксимации. Например, если известно, что сигнал линейно растет на рассматриваемом промежутке, задача сведётся к линейной регрессии, а если можно предположить, что шум — нормален, то правильным методом будет МНК. Но однажды мы столкнулись с задачей оценки формы профиля рентгеновского микрозонда (пучка), про которую априори было достоверно известно только одно: профиль унимодален, а именно имеет ровно один максимум. Оказывается, и в этом случае можно наилучшим (в смысле, например, L2 метрики) образом приблизить экспериментальный сигнал функцией, принадлежащей известному множеству (множеству унимодальных функций). Причём — с приемлемой ассимптотикой вычислительной сложности.
 ===>
===>  ===>
===> 
Задача оффлайновой фильтрации сигналов в случае, когда ожидаемая форма сигнала известна с точностью до нескольких неизвестных параметров, сводится к задаче аппроксимации. Например, если известно, что сигнал линейно растет на рассматриваемом промежутке, задача сведётся к линейной регрессии, а если можно предположить, что шум — нормален, то правильным методом будет МНК. Но однажды мы столкнулись с задачей оценки формы профиля рентгеновского микрозонда (пучка), про которую априори было достоверно известно только одно: профиль унимодален, а именно имеет ровно один максимум. Оказывается, и в этом случае можно наилучшим (в смысле, например, L2 метрики) образом приблизить экспериментальный сигнал функцией, принадлежащей известному множеству (множеству унимодальных функций). Причём — с приемлемой ассимптотикой вычислительной сложности.
===> ===> 



 Впервые на русском языке выходит одна из самых авторитетных книг по разработке и использованию алгоритмов. Алгоритмы — это основа программирования, определяющая, каким образом программное обеспечение будет использовать структуры данных.
Впервые на русском языке выходит одна из самых авторитетных книг по разработке и использованию алгоритмов. Алгоритмы — это основа программирования, определяющая, каким образом программное обеспечение будет использовать структуры данных.



