Как сохранить устаревший язык программирования
1 мин
Сегодня наше внимание привлекла удивительная история человека, который поддерживает язык программирования SPITBOL. Его история насчитывает несколько десятилетий.



 Книга продолжает занимать первые места в рейтинге Амазона, но в сентябре 2015 года авторы выпустили еще одну книгу, которая тоже сразу стала бестселлером.
Книга продолжает занимать первые места в рейтинге Амазона, но в сентябре 2015 года авторы выпустили еще одну книгу, которая тоже сразу стала бестселлером. 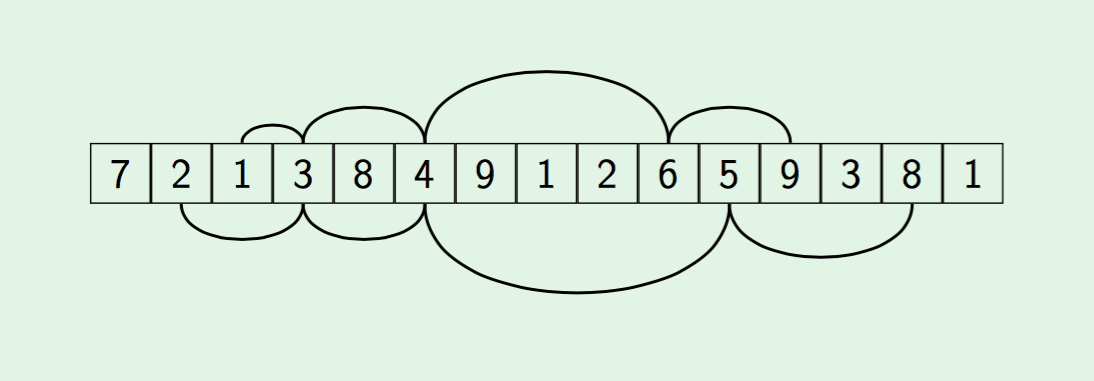
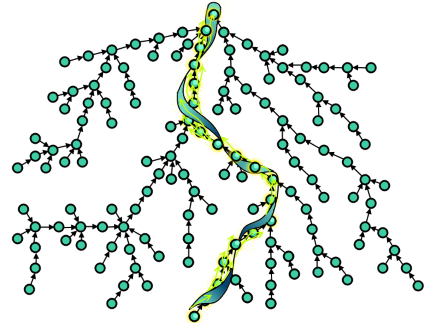 Речь пойдёт о простой структуре данных — системе непересекающихся множеств. Вкратце: даны непересекающиеся множества (например, компоненты связности графа) и по двум элементам x и y можно: 1) узнать, находятся ли x и y в одном множестве; 2) объединить множества, содержащие x и y. Сама структура очень проста в реализации и описывалась много раз в различных местах (например, есть хорошая статья на хабре и ещё кое-где). Но это один из тех удивительных алгоритмов, написать который ничего не стоит, а вот разобраться, почему он работает эффективно совсем нелегко. Я постараюсь изложить относительно простое доказательство точной оценки на время работы этой структуры данных, придуманное Зейделем и Шариром в 2005 (оно отличается от того ужаса, который многие могли видеть в других местах). Конечно, сама структура тоже будет описана, а попутно разберёмся причём здесь обратная функция Аккермана, о которой многие знают только, что она оооочень медленно растёт.
Речь пойдёт о простой структуре данных — системе непересекающихся множеств. Вкратце: даны непересекающиеся множества (например, компоненты связности графа) и по двум элементам x и y можно: 1) узнать, находятся ли x и y в одном множестве; 2) объединить множества, содержащие x и y. Сама структура очень проста в реализации и описывалась много раз в различных местах (например, есть хорошая статья на хабре и ещё кое-где). Но это один из тех удивительных алгоритмов, написать который ничего не стоит, а вот разобраться, почему он работает эффективно совсем нелегко. Я постараюсь изложить относительно простое доказательство точной оценки на время работы этой структуры данных, придуманное Зейделем и Шариром в 2005 (оно отличается от того ужаса, который многие могли видеть в других местах). Конечно, сама структура тоже будет описана, а попутно разберёмся причём здесь обратная функция Аккермана, о которой многие знают только, что она оооочень медленно растёт. 

Александр Иванович Корейко, один из ничтожнейших служащих ГЕРКУЛЕС’а, был человек в последнем приступе молодости, ему было 38 лет. На красном сургучном лице сидели желтые пшеничные брови и белые глаза. Английские усики цветом даже походили на созревший злак. Лицо его казалось бы совсем молодым, если бы не грубые ефрейторские складки, пересекавшие щеки и шею. На службе Александр Иванович вел себя как сверхсрочный солдат: не рассуждал, был исполнителен, трудолюбив, искателен и туповат.
— Робкий он какой-то, — говорил о нем начальник финсчета, — какой-то уж слишком приниженный, преданный какой-то чересчур. Только объявят подписку на заем, как он уже лезет со своим месячным окладом. Первым подписывается. А весь оклад-то 46 рублей. Хотел бы я знать, как он существует на эти деньги.
Была у Александра Ивановича удивительная особенность. Он мгновенно умножал и делил в уме большие трехзначные и четырехзначные числа. Но это не освободило Александра Ивановича от репутации туповатого парня.
— Слушай, Александр Иванович, — спрашивал сосед, — сколько будет 836 на 423?
(«Золотой теленок», Илья Ильф, Евгений Петров )

 Тестирование с помощью SpecFlow прочно вошло в мою жизнь, в список необходимых технологий для «хорошего проекта». Более того, несмотря на ориентированность SpecFlow на behaviour тесты, я пришел к мысли, что и integration и даже unit тесты могут получить преимущества этого подхода. Конечно, в написании таких тестов уже не будут участвовать люди из BA и QA, а только сами разработчики. Разумеется, что для небольших тестов это привносит немалый оверхэд. Но насколько же приятнее читать человеческое описание теста, нежели голый код.
Тестирование с помощью SpecFlow прочно вошло в мою жизнь, в список необходимых технологий для «хорошего проекта». Более того, несмотря на ориентированность SpecFlow на behaviour тесты, я пришел к мысли, что и integration и даже unit тесты могут получить преимущества этого подхода. Конечно, в написании таких тестов уже не будут участвовать люди из BA и QA, а только сами разработчики. Разумеется, что для небольших тестов это привносит немалый оверхэд. Но насколько же приятнее читать человеческое описание теста, нежели голый код.
void ext_sort(const std::string filename, const size_t memory)