
Python 3.5; async/await
5 мин
Тихо и незаметно (с), вышел Python версии 3.5! И, безусловно, одно из самых интересных нововведений релиза является новый синтаксис определения сопрограмм с помощью ключевых слов async/await, далее в статье об этом.
Поверхностный просмотр «PEP 0492 — Coroutines with async and await syntax» поначалу оставил у меня вопрос «Зачем это надо». Сопрограммы удовлетворительно реализуются на расширенных генераторах и на первый взгляд может показаться, что все свелось к замене yield from на await, а декоратора, создающего сопрограмму на async. Сюда можно добавить и возникающее ощущение, что все это сделано исключительно для использования с модулем asyncio.
Но это, конечно же, не так, тема глубже и интереснее.
Поверхностный просмотр «PEP 0492 — Coroutines with async and await syntax» поначалу оставил у меня вопрос «Зачем это надо». Сопрограммы удовлетворительно реализуются на расширенных генераторах и на первый взгляд может показаться, что все свелось к замене yield from на await, а декоратора, создающего сопрограмму на async. Сюда можно добавить и возникающее ощущение, что все это сделано исключительно для использования с модулем asyncio.
Но это, конечно же, не так, тема глубже и интереснее.



 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.




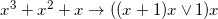 , которая на 6 джаве с выключенным JIT у меня давала около 10% ускорения, при этом на первый взгляд даже не очевидно что эти формулы эквивалентны (ОТКУДА ТУТ OR? ЭТО ВООБЩЕ ЗАКОННО?!), хотя это так. Под катом я расскажу, как именно получались такие результаты и каким образом компьютер придумывал лучший код чем тот, который мог написать я сам.
, которая на 6 джаве с выключенным JIT у меня давала около 10% ускорения, при этом на первый взгляд даже не очевидно что эти формулы эквивалентны (ОТКУДА ТУТ OR? ЭТО ВООБЩЕ ЗАКОННО?!), хотя это так. Под катом я расскажу, как именно получались такие результаты и каким образом компьютер придумывал лучший код чем тот, который мог написать я сам.