
10 новых бесплатных онлайн-курсов на Stepic
4 мин
Сегодня мы открыли запись на 10 новых бесплатных онлайн-курсов (MOOC) по предметам от линейной алгебры и дискретных структур до археологии фольклора и инвестиционного банкинга. В числе авторов – преподаватели и научные сотрудники из МФТИ, НИУ ВШЭ, МИАН, ГАИШ МГУ, СПбГУ и ИБ, МИСиС, ЕУ СПб. Большинство новых курсов разрабатывается по итогам конкурса Stepic Challenge, о котором мы писали ранее.

Преподаватели прямо сейчас ведут работу над записью материалов, поэтому если какой-то курс вас заинтересует, вы можете вносить предложения и идеи по его содержанию. Мы постараемся их учесть.
Список новых курсов:
Преподаватели прямо сейчас ведут работу над записью материалов, поэтому если какой-то курс вас заинтересует, вы можете вносить предложения и идеи по его содержанию. Мы постараемся их учесть.
Список новых курсов:
- Дискретные структуры (7 марта 2015)
- Linear Algebra: Problems and Methods (April 3, 2015) (курс на английском языке)
- Химическая эволюция Вселенной (15 апреля 2015)
- Компьютерная графика: основы (9 марта 2015)
- Основы статистики (15 февраля 2015)
- Инвестиционный банкинг изнутри (6 апреля 2015)
- Археология фольклора: мифологические мотивы на карте мира (2 февраля 2015)
- Управление интеллектуальной собственностью. Основы для инженеров (20 апреля 2015)
- Журналистика и медиаграмотность (31 марта 2015)
- Базовый курс подготовки к ОГЭ по математике (1 февраля 2015)
 Привет всем. Я уже однажды писал про Distance Field и приводил реализацию «эвристическим» кодом, дающую неплохую скорость:
Привет всем. Я уже однажды писал про Distance Field и приводил реализацию «эвристическим» кодом, дающую неплохую скорость: 


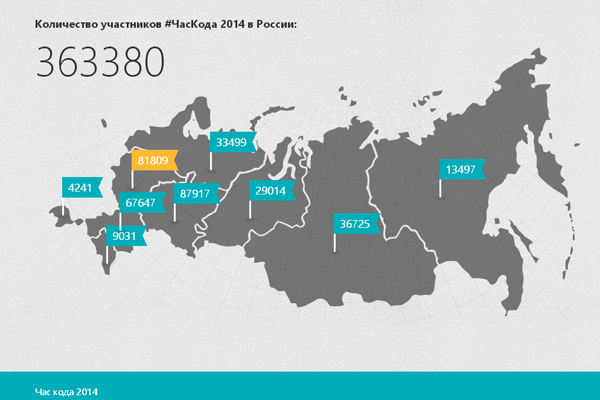




 Сказка ложь, да в ней намек…
Сказка ложь, да в ней намек…