
Консенсус в распределенных системах. Paxos
7 мин
В последнее время в научных публикациях всё чаще упоминается алгоритм достижения консенсуса в распределенных системах под названием Paxos. Среди таких публикаций ряд работ сотрудников Google (Chubby, Megastore, Spanner) ранее уже частично освещенных на хабре, архитектуры систем WANdisco, Ceph и пр. В то же время, сам алгоритм Paxos считается сложным для понимания, хоть и основывается он на элементарных принципах.
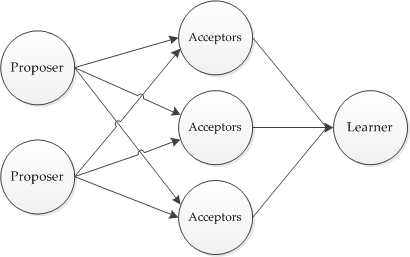
В этой статье я постараюсь исправить эту ситуацию и рассказать об этом алгоритме понятным языком, как когда-то это попытался сделать автор алгоритма Лесли Лэмпорт.
В этой статье я постараюсь исправить эту ситуацию и рассказать об этом алгоритме понятным языком, как когда-то это попытался сделать автор алгоритма Лесли Лэмпорт.
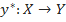 , значения которой известны только на объектах конечной обучающей выборки
, значения которой известны только на объектах конечной обучающей выборки 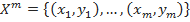 . Требуется построить алгоритм
. Требуется построить алгоритм 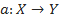 , способный классифицировать произвольный объект x∈X. Однако более распространенным является вероятностная постановка задачи. Пусть X — множество описаний объектов, Y — множество номеров (или наименований) классов. На множестве пар «объект, класс» X×Y определена вероятностная мера P. Имеется конечная обучающая выборка независимых наблюдений
, способный классифицировать произвольный объект x∈X. Однако более распространенным является вероятностная постановка задачи. Пусть X — множество описаний объектов, Y — множество номеров (или наименований) классов. На множестве пар «объект, класс» X×Y определена вероятностная мера P. Имеется конечная обучающая выборка независимых наблюдений 




 В жизни каждого мужчины наступает момент, когда трафик растёт и
В жизни каждого мужчины наступает момент, когда трафик растёт и 
 Генетические алгоритмы были изобретены в 1950-х годах как результат первых экспериментов по моделированию естественной эволюции на компьютере. С тех пор они используются для решения самых разнообразных оптимизационных задач, где градиентные методы почему-то не подходят. Биологическая составляющая генетических алгоритмов имеет здесь очень упрощенный вид и речь в данном случае идет скорее о следовании общей идее эволюционного отбора, чем полноценному его моделированию. Тем не менее, иногда результаты работы ГА получается интерпретировать в биологическом смысле. В нашей статье мы рассказываем об опыте применения генетических алгоритмов для задачи распознавания лиц с целью получения «регионов важности» лица. Применение этого подхода позволило в среднем на 20% повысить точность распознавания нашей системы распознавания лиц.
Генетические алгоритмы были изобретены в 1950-х годах как результат первых экспериментов по моделированию естественной эволюции на компьютере. С тех пор они используются для решения самых разнообразных оптимизационных задач, где градиентные методы почему-то не подходят. Биологическая составляющая генетических алгоритмов имеет здесь очень упрощенный вид и речь в данном случае идет скорее о следовании общей идее эволюционного отбора, чем полноценному его моделированию. Тем не менее, иногда результаты работы ГА получается интерпретировать в биологическом смысле. В нашей статье мы рассказываем об опыте применения генетических алгоритмов для задачи распознавания лиц с целью получения «регионов важности» лица. Применение этого подхода позволило в среднем на 20% повысить точность распознавания нашей системы распознавания лиц.
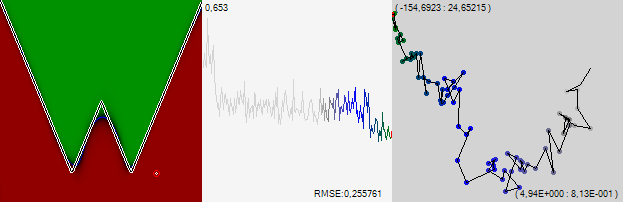
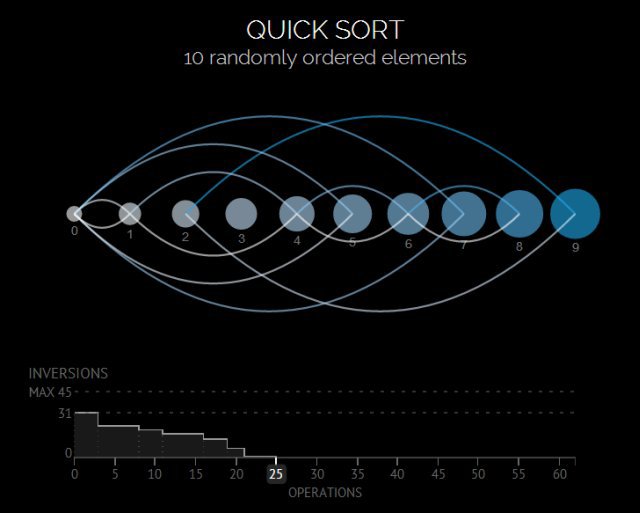
 Поскольку побеждать
Поскольку побеждать 