«Усложнённость (Simplexity) — процесс, которым природа достигает простых результатов сложными путями.» — Bruce Schiff

1. Введение
Представьте себе следующую задачу: у нас есть таблица из
n целочисленных ключей
A1, A2, …, An, и целочисленное значение
X. Нам нужно найти индекс числа
X в этой таблице,
но при этом мы особо никуда не торопимся. На самом деле, мы бы хотели делать это как можно дольше.
Для этой задачи мы могли бы остановиться на самом тривиальном алгоритме, а именно, перебирать все
An по порядку и сравнивать их с
X. Но, может так случиться, что
X =
A1, и алгоритм остановится на самом первом шаге. Таким образом, мы видим, что наивный алгоритм в наилучшем случае имеет временную сложность
O(1). Возникает вопрос — можем ли мы улучшить (то есть, ухудшить) этот результат?
Разумеется, мы можем сильно замедлить этот алгоритм, добавив в него пустых циклов перед первой проверкой равенства
X и
A1. Но, к сожалению, этот способ нам не годится, потому что любой дурак заметит, что алгоритм просто-напросто впустую тратит время. Таким образом, нам нужно найти такой алгоритм, который бы всё-таки продвигался к цели, не смотря на отсутствие энтузиазма, или вовсе желания до неё в конечном итоге дойти.



 В предыдущих частях цикла мы рассмотрели алгоритмы
В предыдущих частях цикла мы рассмотрели алгоритмы 

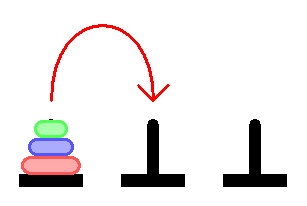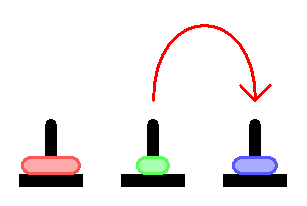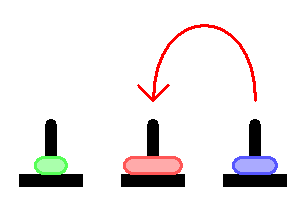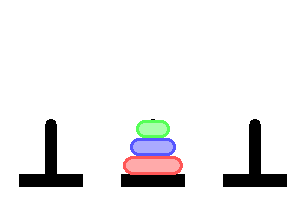 Пообщавшись с некоторыми знакомыми программистами, внезапно обнаружил, что не все знают про Ханойскую башню, а среди тех кто знает — мало кто понимает как решается эта задача.
Пообщавшись с некоторыми знакомыми программистами, внезапно обнаружил, что не все знают про Ханойскую башню, а среди тех кто знает — мало кто понимает как решается эта задача.