
Международная популярность Сноудена — миф или реальность? Результаты глобального мониторинга социальных медиа
4 мин
Эдварда Сноудена не существует и о нем говорят только в России. «Сноуден — предатель, враг и изменник», — считают жители США. «Сноуден — международный герой и пример для подражания», — говорят… ну где-то наверняка говорят, думали мы. Когда мы приступали к работе над новой задачей, нам казалось, что тема Эдварда Сноудена заинтриговала весь мир. Поэтому задача, поставленная нашими партнерами из фонда «Vox Populi», специализирующегося на исследованиях общественного мнения в социальных медиа, казалась нам довольно простой: оценить интерес населения к ситуации по Сноудену в мире, и в России и США в частности. Но мониторинг соцмедиа для социологических исследований — сущность новая, а потому вдвойне интересная: во-первых, никогда не знаешь, какой именно результат получишь; во-вторых, восхищаешься возможностями социовселенной, созданной человечеством. Результат и в этот раз получился несколько бОльшим и довольно неожиданным: мы проанализировали многоязычный поток сообщений из 230 (!) стран мира. О том, как мы разделяли по языкам и геолоцировали это царство Вавилонское — под катом.

HP Vertica, первый запущенный проект в РФ, опыт полтора года реальной эксплуатации
17 мин
В качестве вступительного слова
На Хабре и других источниках уже было описание HP Vertica, но, в основном, вся информация сводилась к теории. До недавнего времени в реальной промышленной эксплуатации Vertica использовалась (так как мы называем ее Вертика, предлагаю назначить женский род) в Штатах и немного в Европе, на Хабре же о ней писали ребята с LifeStreet Media. Уже прошло полтора года работы с Vertica, наше хранилище данных содержит десятки терабайт данных. В минуту сервер данных обрабатывает тысячи запросов, многие из которых содержат десятки миллиардов записей. Загрузка данных идет не переставая в реалтайме объемами порядка 150 гб в сутки … В общем я подумал, что стоит восполнить пробел и поделиться ощущениями от езды на реально современных новых технологиях под BigData.
Кому это будет полезно
Думаю, это будет полезно для разработчиков, архитекторов и интеграторов, которые сталкиваются с задачами хранения и аналитической обработки больших данных по объему, содержанию и сложности анализа. Тем более, у Vertica сейчас наконец то есть вменяемая бесплатная полноценная версия Community Edition. Она позволяет развернуть кластер из 3 серверов и загрузить в хранилище данных до 1 тб сырых данных. С учетом производительности и легкости развертывания решений на Vertica, считаю это предложение достойным для того, чтобы его рассмотреть при выборе хранилища данных для компаний, у которых объем данных впишется в 1 тб.
В один абзац о том, как мы выбирали
Кратко без повода к холивару:
При выборе сервера хранилищ данных нас интересовали принципы ценообразования, высокая производительность и масштабируемость работы с большими объемами данных, возможность загрузки данных в реалтайм с множества разных источников данных, легкость стартапа проекта своими силами и минимальная стоимость сопровождения: в итоге по всем этим показателям лучше всего для нас выступила Vertica, победив IBM Netezza и EMC GreenPlum. Последние не смогли полностью удовлетворить всем нашим требованиям. Это могло вылиться в дополнительные издержки на разработку и сопровождение нашего проекта, имеющего не сильно большой бюджет.
Как выглядит Verica с точки зрения архитектора
Архитектор — это самый важный для хранилища данных человек в Vertica. Именно в первую очередь от него зависит успешность и производительность функционирования хранилища данных. У архитектора две сложных задачи: грамотно подобрать техническую начинку кластера Vertica и правильно спроектировать физическую модель базы данных.
На что влияет техническая архитектура
Алгоритмизация правосудия
3 мин
Recovery Mode
Количество информации, доступной для обработки и анализа с помощью компьютеров, растёт, как снежный ком. Данные с камер видеонаблюдения, GPS-трекеров, сенсоров мобильных телефонов, записи финансовых транзакций, история посещений страниц в интернете оказывают всё большее влияние на принятие решений. И чем больше этих данных, тем больше приходится полагаться на их автоматическую интерпретацию. Неизбежное следствие этого — появление систем «компьютерного правосудия», которые без участия человека выявляют нарушения законов и правил. Штрафы за превышение скорости, выписываемые автоматически на основании данных с видеокамер и радаров или система анализа контента на Youtube, которая ищет нарушения копирайта — это уже повседневная реальность.
Группа американских учёных, объединяющая юристов, лингвистов и программистов, провела интересный эксперимент в этой сфере. В ходе эксперимента 52 студента-программиста должны были составить программу, которая анализировала бы данные с GPS-трекера, установленного в автомобиле и выписывала штрафы за нарушение скоростного режима в соответствии с правилами дорожного движения штата Нью-Йорк. Это оказалось очень непростой задачей — даже в самых законопослушных государствах законы никогда не выполняются буквально и на все 100%. Часть нарушений остаются незамеченными, часть слишком незначительна, чтобы правоохранители обратили на них внимание. Компьютеры же ничего не забывают и ничего не упускают. Бездумное применение правил и алгоритмов приводит к излишне жестким наказаниям и нелепым ошибкам вроде блокирования видео с шумом ветра за нарушение копирайта.
Группа американских учёных, объединяющая юристов, лингвистов и программистов, провела интересный эксперимент в этой сфере. В ходе эксперимента 52 студента-программиста должны были составить программу, которая анализировала бы данные с GPS-трекера, установленного в автомобиле и выписывала штрафы за нарушение скоростного режима в соответствии с правилами дорожного движения штата Нью-Йорк. Это оказалось очень непростой задачей — даже в самых законопослушных государствах законы никогда не выполняются буквально и на все 100%. Часть нарушений остаются незамеченными, часть слишком незначительна, чтобы правоохранители обратили на них внимание. Компьютеры же ничего не забывают и ничего не упускают. Бездумное применение правил и алгоритмов приводит к излишне жестким наказаниям и нелепым ошибкам вроде блокирования видео с шумом ветра за нарушение копирайта.
Знакомство с Apache Mahout
5 мин
Перевод
Привет.
Моя первая статья на Хабре показала, что не многие знают о библиотеке Mahout. (Может быть, конечно, я в этом ошибаюсь.) Да и ознакомительного материала по этой теме здесь нет. Поэтому я решил написать пост, рассказывающий о возможностях библиотеки. Пара проб пера показали, что лучшим введением в тему будут небольшие выдержки из книги “Mahout in Action” Owen, Anil, Dunning, Friedman. Поэтому я сделал вольный перевод некоторых мест, которые, как мне кажется, хорошо рассказывают об области применения Mahout.

Моя первая статья на Хабре показала, что не многие знают о библиотеке Mahout. (Может быть, конечно, я в этом ошибаюсь.) Да и ознакомительного материала по этой теме здесь нет. Поэтому я решил написать пост, рассказывающий о возможностях библиотеки. Пара проб пера показали, что лучшим введением в тему будут небольшие выдержки из книги “Mahout in Action” Owen, Anil, Dunning, Friedman. Поэтому я сделал вольный перевод некоторых мест, которые, как мне кажется, хорошо рассказывают об области применения Mahout.
Apache Mahout. Метрики для определения схожести пользователей
4 мин
Привет.
Читаю книгу Mahout in Action. Столкнулся с эффектом “смотрю в книгу – вижу фигу”. Для его устранения решил конспектировать.
Apache Mahout – это библиотека для работы с алгоритмами машинного обучения, которая может быть использована как надстройка к Hadoop или самостоятельно. В библиотеке реализованы методы коллаборативной фильтрации, кластеризации и классификации.
Рассматриваем рекомендательную систему на основе коллаборатвной фильтрации. Она может быть пользователе-ориентированной (user-based) или свойство-ориентированной (item-based).
Одно из основных понятий пользователе-ориентированных рекомендательных систем это метрика для определения схожести пользователей. Предположим что мы имеем данные по просмотрам и оценкам фильмов разными пользователями. Будем сравнивать двух пользователей: X и Y. Они выставили оценки фильмам X(x1, x2, ..., xn) и Y(y1, y2, ..., ym), где n, m – количество оценок поставленных первым и вторым пользователем соответственно. N – количество оценок, которые были поставленны обоими пользователями одним и тем же фильмам (пересечение множеств фильмов посмотренных первым и вторым). Будем считать что (xi, yi) – это пара оценок выставленная пользователями одному фильму.
В Mahout реализованы метрики на основании нескольких алгоритмов. Описываю сами алгоритмы, а не их реализации в Mahout.
Читаю книгу Mahout in Action. Столкнулся с эффектом “смотрю в книгу – вижу фигу”. Для его устранения решил конспектировать.
Apache Mahout – это библиотека для работы с алгоритмами машинного обучения, которая может быть использована как надстройка к Hadoop или самостоятельно. В библиотеке реализованы методы коллаборативной фильтрации, кластеризации и классификации.
Рассматриваем рекомендательную систему на основе коллаборатвной фильтрации. Она может быть пользователе-ориентированной (user-based) или свойство-ориентированной (item-based).
Коллаборативная фильтрация — это один из методов построения прогнозов, использующий известные предпочтения (оценки) группы пользователей для прогнозирования неизвестных предпочтений другого пользователя. Его основное допущение состоит в следующем: те, кто одинаково оценивали какие-либо предметы в прошлом, склонны давать похожие оценки другим предметам и в будущем. (из википедии)
Одно из основных понятий пользователе-ориентированных рекомендательных систем это метрика для определения схожести пользователей. Предположим что мы имеем данные по просмотрам и оценкам фильмов разными пользователями. Будем сравнивать двух пользователей: X и Y. Они выставили оценки фильмам X(x1, x2, ..., xn) и Y(y1, y2, ..., ym), где n, m – количество оценок поставленных первым и вторым пользователем соответственно. N – количество оценок, которые были поставленны обоими пользователями одним и тем же фильмам (пересечение множеств фильмов посмотренных первым и вторым). Будем считать что (xi, yi) – это пара оценок выставленная пользователями одному фильму.
В Mahout реализованы метрики на основании нескольких алгоритмов. Описываю сами алгоритмы, а не их реализации в Mahout.
Больше, чем GoogleReader: давайте сделаем это вместе!
6 мин
Мы хотим оповестить экспертное сообщество Хабра о публичном этапе проекта по созданию сервиса, включающего, помимо возможностей почившего гугл-ридера, множество новых фич, функций и пряников!
И, поскольку мы делаем проект для нас с вами, наших коллег, обычных гиков и продвинутых юзеров, то надеемся на ваши комментарии, критику, замечания, предложения — всё, что поможет на выходе получить продукт, которым нам всем будет удобно пользоваться. Хотите с нами? Welcome!

И, поскольку мы делаем проект для нас с вами, наших коллег, обычных гиков и продвинутых юзеров, то надеемся на ваши комментарии, критику, замечания, предложения — всё, что поможет на выходе получить продукт, которым нам всем будет удобно пользоваться. Хотите с нами? Welcome!
Можно ли уйти от HDD в хостинговых серверах?
3 мин

Тот факт, что хостинг является весьма затратным с точки зрения дискового пространства, пожалуй, ни для кого не является сюрпризом. Так же как и тот факт, что используемые для хранения данных решения в этом случае должны быть как можно быстрее. Поэтому, в идеале, для таких хранилищ хорошо было бы использовать только SSD, но в очень многих случаях это — недостижимый идеал, в первую очередь, из-за высокой (хотя и снижающейся) цены. Особенно жестко вопрос цены стоит для больших ЦОДов.
Помочь в этой ситуации могут гибридные решения, сочетающие традиционные HDD и flash-накопители для кэширования.
Мега-ЦОДы — пионеры инноваций. Часть 2
4 мин

Мы продолжаем знакомство с современными сверхбольшими дата-центрами, начатое прошлой статьей, и сегодня поговорим о том, как решается одна из наиболее важных проблем — хранение данных. Кроме того, мы немного поговорим о ближайшем будущем таких мега-ЦОД.
Map-Reduce на примере MongoDB
5 мин
В последнее время набирает популярность семейство подходов и методологий обработки данных, объединенных общими названиями Big Data и NoSQL. Одной из моделей вычислений, применяемых к большим объемам данных, является технология Map-Reduce, разработанная в недрах компании Google. В этом посте я постараюсь рассказать о том, как эта модель реализована в нереляционной СУБД MongoDB.
Что касается будущего нереляционных баз вообще и технологии Map-Reduce в частности, то на эту тему можно спорить до бесконечности, и пост совершенно не об этом. В любом случае, знакомство с альтернативными традиционным СУБД способами обработки данных является полезным для общего развития любого программиста, так же как, к примеру, знакомство с функциональными языками программирования может оказаться полезным и для программистов, работающих исключительно с императивными языками.
Нереляционная СУБД MongoDB представляет данные в виде коллекций из документов в формате JSON и предоставляет разные способы обработки этих данных. В том числе, присутствует собственная реализация модели Map-Reduce. О том, насколько целесообразно применять именно эту реализацию в практических целях, будет сказано ниже, а пока ограничимся тем, что для ознакомления с самой парадигмой Map-Reduce эта реализация подходит как нельзя лучше.
Итак, что же такого особенного в Map-Reduce?
Что касается будущего нереляционных баз вообще и технологии Map-Reduce в частности, то на эту тему можно спорить до бесконечности, и пост совершенно не об этом. В любом случае, знакомство с альтернативными традиционным СУБД способами обработки данных является полезным для общего развития любого программиста, так же как, к примеру, знакомство с функциональными языками программирования может оказаться полезным и для программистов, работающих исключительно с императивными языками.
Нереляционная СУБД MongoDB представляет данные в виде коллекций из документов в формате JSON и предоставляет разные способы обработки этих данных. В том числе, присутствует собственная реализация модели Map-Reduce. О том, насколько целесообразно применять именно эту реализацию в практических целях, будет сказано ниже, а пока ограничимся тем, что для ознакомления с самой парадигмой Map-Reduce эта реализация подходит как нельзя лучше.
Итак, что же такого особенного в Map-Reduce?
Улучшения XQuery в MarkLogic Server
6 мин
В MarkLogic Server реализован собственный диалект XQuery, который называется XQuery 1.0-ml. Не трудно догадаться, что это — тот самый XQuery 1.0 с некоторыми дополнениями от MarkLogic, призванными сделать жизнь разработчика лучше.
Microsoft Dryad vs Apache Hadoop. Неначатое сражение за Big Data
12 мин
UPD: сменил заголовок статьи, т.к. прошлый заголовок я написал, пока был лунатиком (шутка, разумеется).

На прошлой неделе на Хабре появилось 2 поста о фреймворке распределенных вычислений от Microsoft Research – Dryad. В частности, подробно были описаны концепции и архитектура ключевых компонентов Dryad – среды исполнения Dryad и языка запросов DryadLINQ.
Логическим завершением цикла статей о Dryad видится сравнение фреймворка Dryad с другими, знакомыми разработчикам MPP-приложений, инструментами: реляционными СУБД (в т.ч. параллельными), GPU-вычислениями и платформой Hadoop.
DryadLINQ. Распределенный LINQ от Microsoft Research
11 мин
Предметом внимания вчерашнего поста на Хабре стал фреймворк распределенных вычислений от Microsoft Research — Dryad.
В основе фреймворка лежит представление задания, как направленного ациклического графа, где вершины графа представляют собой программы, а ребра — каналы, по которым данные передаются. Также обзорно была рассмотрена экосистема фреймворка Dryad и сделан подробный обзор архитектуры одного из центральных компонентов экосистемы фреймворка – среды исполнения распределенных приложений Dryad.
В этой статье обсудим компонент верхнего уровня программного стэка фреймворка Dryad – язык запросов к распределенному хранилищу DryadLINQ.
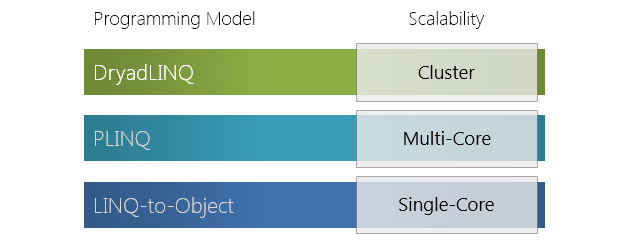
В основе фреймворка лежит представление задания, как направленного ациклического графа, где вершины графа представляют собой программы, а ребра — каналы, по которым данные передаются. Также обзорно была рассмотрена экосистема фреймворка Dryad и сделан подробный обзор архитектуры одного из центральных компонентов экосистемы фреймворка – среды исполнения распределенных приложений Dryad.
В этой статье обсудим компонент верхнего уровня программного стэка фреймворка Dryad – язык запросов к распределенному хранилищу DryadLINQ.
Ближайшие события
Dryad. Фреймворк распределенных вычислений
10 мин
Представьте себе фреймворк общего назначения для распределенного исполнения приложений со следующими статистическими показателями*:

* Статистические данные за 2011 год.
А теперь представьте, что это не Hadoop.
О том, что это за фреймворк, о идеях и концепциях, заложенных в его основу и о том, почему этот фреймворк даже более инновационный (субъективно), чем Hadoop, речь пойдет ниже.
* Статистические данные за 2011 год.
А теперь представьте, что это не Hadoop.
О том, что это за фреймворк, о идеях и концепциях, заложенных в его основу и о том, почему этот фреймворк даже более инновационный (субъективно), чем Hadoop, речь пойдет ниже.
Решения Fujitsu для резервного копирования и архивирования
6 мин
В настоящее время роль информационных технологий в бизнес-процессах современных предприятий невозможно переоценить. При этом, чем глубже происходит их интеграция, тем важнее становится стоимость обрабатываемых данных, тем дороже обходится их потеря. Таким образом, вопрос защиты данных, их архивирования и хранения уже сейчас волнует не только системных администраторов, но и руководителей предприятий и владельцев бизнеса.
Современные реалии в случае возникновения какого-либо непредвиденного сбоя (аварии) требуют минимизации двух основных параметров: объема потерянных данных и времени восстановления. При этом объем потерянных данных фактически напрямую зависит от времени, прошедшего с момента сохранения последнего состояния системы до момента аварии. Тем самым, для минимизации данного параметра необходимо как можно чаще выполнять резервное копирование, в свою очередь увеличивая и без того растущий объем хранимых данных. Именно организация бэкапа, на текущий момент, становится основной задачей системного администратора.
Основные проблемы защиты данных
Современные реалии в случае возникновения какого-либо непредвиденного сбоя (аварии) требуют минимизации двух основных параметров: объема потерянных данных и времени восстановления. При этом объем потерянных данных фактически напрямую зависит от времени, прошедшего с момента сохранения последнего состояния системы до момента аварии. Тем самым, для минимизации данного параметра необходимо как можно чаще выполнять резервное копирование, в свою очередь увеличивая и без того растущий объем хранимых данных. Именно организация бэкапа, на текущий момент, становится основной задачей системного администратора.
Эластичное избыточное S3-совместимое хранилище за 15 минут
6 мин
Туториал
S3 сегодня не удивишь наверное никого. Его используют и как бэкенд хранилище под веб сервисы, и как хранилище файлов в медиа индустрии, так и как архив для бэкапов.

Рассмотрим небольшой пример развертывания S3-совместимого хранилища на основе объектного хранилища Ceph
Рассмотрим небольшой пример развертывания S3-совместимого хранилища на основе объектного хранилища Ceph
Распределенная файловая система Ceph FS за 15 минут
4 мин
Туториал
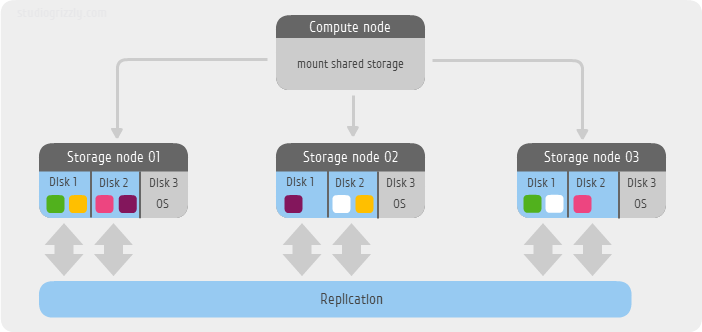
Нам понадобится всего лишь несколько минут для того что бы поднять распределенную файловую систему Ceph FS
Практика LSI
4 мин
Даже самые заядлые скептики уже признают, что технологии SSD обладают рядом неоспоримых преимуществ по сравнению с обычными жесткими дисками и позволяют получить значительно большую производительность операций ввода/вывода (а в некоторых случаях скорости I/O — много не бывает). Вместе с тем, SSD еще не готовы к повсеместному внедрению вместо традиционных жестких дисков по целому ряду причин: начиная с цены и заканчивая надежностью. Что же делать? На выручку приходят гибридные решения, которые сочетают традиционные диски с SSD, позволяя получить (пусть и с определенными оговорками) преимущества обоих решений.
Если не углубляться в детали, то сам принцип работы гибридных систем достаточно прост (а если углубиться — то можно настолько погрузиться, что и не вернешься за год) и одинаков для всех систем, начиная с дисков Seagate Momentus XT и Apple Fusion Drive, заканчивая дорогими и сложными решениями для больших систем хранения данных и дата-центров, о которых сегодня и пойдет речь.
Для основного хранения данных используются традиционные жесткие диски, по необходимости объединенные в RAID, а SSD используется для кэширования самых часто используемых данных, к которым надо обращаться чаще всего. Управление кэшированием системы берут на себя, и чаще всего кэш-раздел в системе вообще недоступен в виде отдельного диска.
В больших и «серьезных» системах вопросы оптимизации ввода/вывода стоят еще острее, чем для настольных компьютеров. То, что для пользователя является секундной задержкой в запуске тяжелой программы, в случае нагруженного сервера может вылиться во многие тысячи долларов убытков, если дисковая подсистема станет «бутылочным горлышком», замедляющим всю работу.
Говоря о больших системах хранения данных, нельзя не вспомнить про компанию LSI, которая, являясь одним из крупнейших поставщиков для систем хранения данных, не могла остаться в стороне. В портфеле продуктов LSI есть набор решений для ускорения работы дисковых систем, объединенных в семейство Nytro.
Если не углубляться в детали, то сам принцип работы гибридных систем достаточно прост (а если углубиться — то можно настолько погрузиться, что и не вернешься за год) и одинаков для всех систем, начиная с дисков Seagate Momentus XT и Apple Fusion Drive, заканчивая дорогими и сложными решениями для больших систем хранения данных и дата-центров, о которых сегодня и пойдет речь.
Для основного хранения данных используются традиционные жесткие диски, по необходимости объединенные в RAID, а SSD используется для кэширования самых часто используемых данных, к которым надо обращаться чаще всего. Управление кэшированием системы берут на себя, и чаще всего кэш-раздел в системе вообще недоступен в виде отдельного диска.
В больших и «серьезных» системах вопросы оптимизации ввода/вывода стоят еще острее, чем для настольных компьютеров. То, что для пользователя является секундной задержкой в запуске тяжелой программы, в случае нагруженного сервера может вылиться во многие тысячи долларов убытков, если дисковая подсистема станет «бутылочным горлышком», замедляющим всю работу.
Говоря о больших системах хранения данных, нельзя не вспомнить про компанию LSI, которая, являясь одним из крупнейших поставщиков для систем хранения данных, не могла остаться в стороне. В портфеле продуктов LSI есть набор решений для ускорения работы дисковых систем, объединенных в семейство Nytro.
Data mining: Инструментарий — Theano
6 мин
Туториал

В предыдущих материалах этого цикла мы рассматривали методы предварительной обработки данных при помощи СУБД. Это может быть полезно при очень больших объемах обрабатываемой информации. В этой статье я продолжу описывать инструменты для интеллектуальной обработки больших объёмов данных, остановившись на использовании Python и Theano.
Цикл зрелости технологий на 2013 год по версии Gartner
2 мин
Исследовательская компания Gartner хорошо известна на рынке аналитики информационных технологий. Я бы даже сказал — является одним из лидеров этого рынка. Ежегодно она выкладывают крайне интересный график, именуемый «Цикл зрелости технологий» (в англ. Hype cycle, или дословно – «цикл шумихи»). На этом графике, в хронологическом порядке, разложены технологии, которые либо уже готовы к применению, либо только-только вступают в стадию исследований.
Вот так выглядит график на 2013 год (выполнен по состоянию на июль 2012 года):

Итак, график делится на пять частей. Первая – «технологический триггер». Т.е. то время, когда технология только-то начинает свое существование (хотя бы в виде идеи). Этап второй – «пик завышенных ожиданий». Т.е. период времени, когда о технологии начинает узнавать общественность. На вершине этого пика о технологии говорят все и на каждом углу, и даже бульварная пресса начинает писать об этом как о почти свершившемся факте. Дальше следует «пропасть разочарования», т.е. то время, когда оказывается, что в реальности технология позволяет делать совсем не то, что от нее хотели. Из этой пропасти выбираются далеко не все. Ну и следом идет «склон просвещения» и «плато продуктивности», по сути – последние этапы перед массовым внедрением.
Вот так выглядит график на 2013 год (выполнен по состоянию на июль 2012 года):
Итак, график делится на пять частей. Первая – «технологический триггер». Т.е. то время, когда технология только-то начинает свое существование (хотя бы в виде идеи). Этап второй – «пик завышенных ожиданий». Т.е. период времени, когда о технологии начинает узнавать общественность. На вершине этого пика о технологии говорят все и на каждом углу, и даже бульварная пресса начинает писать об этом как о почти свершившемся факте. Дальше следует «пропасть разочарования», т.е. то время, когда оказывается, что в реальности технология позволяет делать совсем не то, что от нее хотели. Из этой пропасти выбираются далеко не все. Ну и следом идет «склон просвещения» и «плато продуктивности», по сути – последние этапы перед массовым внедрением.