
Привет, Хабр!
На днях мы выпустили CLion 2018.3. Третий в этом году крупный релиз подытоживает нашу работу по двум важным направлениям развития — улучшению языковой поддержки и удаленной разработке.
Кроме того, мы, наконец:

Подробнее об этих и других нововведениях читайте ниже. А чтобы попробовать новые возможности и улучшения, скачивайте бесплатную 30-дневную версию с нашего сайта.
На днях мы выпустили CLion 2018.3. Третий в этом году крупный релиз подытоживает нашу работу по двум важным направлениям развития — улучшению языковой поддержки и удаленной разработке.
Кроме того, мы, наконец:
- добавили средства профилирования кода;
- переделали команды в редакторе для сборки/пересборки кода на уровне одного файла, нескольких таргетов или всего проекта целиком;
- вместе с другими IDE на базе платформы IntelliJ добавили поддержку Git submodules и GitHub pull requests;
- улучшили средства универсального доступа к возможностям IDE (accessibility).
Подробнее об этих и других нововведениях читайте ниже. А чтобы попробовать новые возможности и улучшения, скачивайте бесплатную 30-дневную версию с нашего сайта.



 Современные компьютерные технологии, технические и программные решения — всё это сильно облегчает и ускоряет проведение различных научных исследований. Зачастую компьютерное моделирование — единственный способ проверки многих теорий. Научный софт имеет свои особенности. Например, такой софт зачастую подвергается очень тщательному тестированию, но слабо документирован. Тем не менее программное обеспечение пишется людьми, а люди допускают ошибки. Ошибки в научных программах могут ставить под сомнение целые исследования. В этой статье будут приведены десятки проблем, обнаруженных в коде пакета программ NCBI Genome Workbench.
Современные компьютерные технологии, технические и программные решения — всё это сильно облегчает и ускоряет проведение различных научных исследований. Зачастую компьютерное моделирование — единственный способ проверки многих теорий. Научный софт имеет свои особенности. Например, такой софт зачастую подвергается очень тщательному тестированию, но слабо документирован. Тем не менее программное обеспечение пишется людьми, а люди допускают ошибки. Ошибки в научных программах могут ставить под сомнение целые исследования. В этой статье будут приведены десятки проблем, обнаруженных в коде пакета программ NCBI Genome Workbench.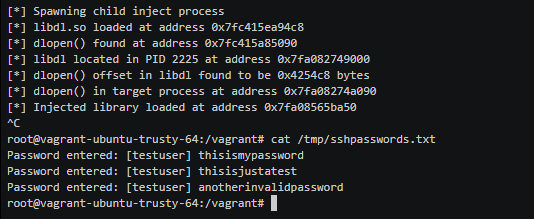



 Я говорю о неверном использовании функции
Я говорю о неверном использовании функции 


.jpg){kind=link}
{kind=link}