Я только что закончил серию изменений в коде браузера Chrome, которая уменьшила размер его бинарника под Windows примерно на 1 мегабайт, перенесла около 500 КB из read/write сегмента в read-only, а также уменьшила потребление оперативной памяти в общем примерно на 200 KB на каждый процесс Chrome. Удивительное заключается в том, что конкретно данная серия изменений состояла исключительно из удаления и добавления ключевого слова const в некоторых местах кода. Да, компиляторы — странные.
Эта задача возникла, когда я
писал документацию для некоторых утилит, которые я использую для исследования регрессий кода, связанных с увеличением размера скомпилированных бинарников под Windows. Я запустил утилиту, скопировал в документацию её вывод и начал его описывать, когда заметил нечто странное: несколько больших глобальных объектов, которые согласно архитектуре должны были быть константными, почему-то находились в сегменте read/write данных. Сокращённая версия того вывода утилиты показана ниже:
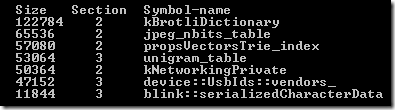
Большинство исполняемых форматов имеют как минимум два сегмента данных — один для read/write объектов и ещё один для read-only. Если у вас есть константные данные, такие, например, как
kBrotliDictionary, то их будет логично поместить в read-only сегмент, который является сегментом «2» в бинарнике Chrome под Windows. Однако некоторые константные данные, такие как
unigram_table,
device::UsbIds::vendors_ и
blink::serializedCharacterData были в секции «3», то есть в read/write сегменте.



 Название статьи намекает разработчикам Visual Studio, что они могут получать пользу от использования статического анализатора кода PVS-Studio. В статье приводятся результаты анализа библиотек, входящих в состав недавно выпущенной версии Visual C++ 2017, и даются рекомендации по улучшению и устранению ошибок. Приглашаю читателей узнать, как разработчики Visual C++ Libraries отстреливают ноги: будет интересно и познавательно.
Название статьи намекает разработчикам Visual Studio, что они могут получать пользу от использования статического анализатора кода PVS-Studio. В статье приводятся результаты анализа библиотек, входящих в состав недавно выпущенной версии Visual C++ 2017, и даются рекомендации по улучшению и устранению ошибок. Приглашаю читателей узнать, как разработчики Visual C++ Libraries отстреливают ноги: будет интересно и познавательно.








 Чтобы исправить это, мы взяли интервью у Filip W, Microsoft MVP, контрибьютора Roslyn и просто одного из наиболее популярных в мире ASP.NET блоггеров. Почему Filip считает, что изменения в новом С# могут пройти незамеченными, зачем писать собственные анализаторы кода, а также почему скриптинг на C# лучше, чем любом скриптовом языке?
Чтобы исправить это, мы взяли интервью у Filip W, Microsoft MVP, контрибьютора Roslyn и просто одного из наиболее популярных в мире ASP.NET блоггеров. Почему Filip считает, что изменения в новом С# могут пройти незамеченными, зачем писать собственные анализаторы кода, а также почему скриптинг на C# лучше, чем любом скриптовом языке? В
В