OpenRefine и другие альтернативные MS Excel инструменты нормализации справочников для Экспертов НСИ
Судя по вакансиям на hh.ru, у некоторых компаний в русскоязычном сегменте наступила стадия принятия необходимости введения должности «Эксперт НСИ», хотя бы в виде функциональной роли.
Аббревиатурой «НСИ» (нормативно‑справочная информация) в компаниях может обозначаться достаточно широкий спектр источников информации, как структурированной (например таблицы единиц измерения или кодов операций в учётных системах и другие нетранзакционные данные), так и неструктурированной (тексты государственных или отраслевых стандартов, корпоративных организационно‑распорядительных документов и т. д.).
Нормализация и классификация записей справочников НСИ, в том числе справочника Номенклатур — одна из типовых функциональных обязанностей, входящих в описание роли «Эксперт НСИ».
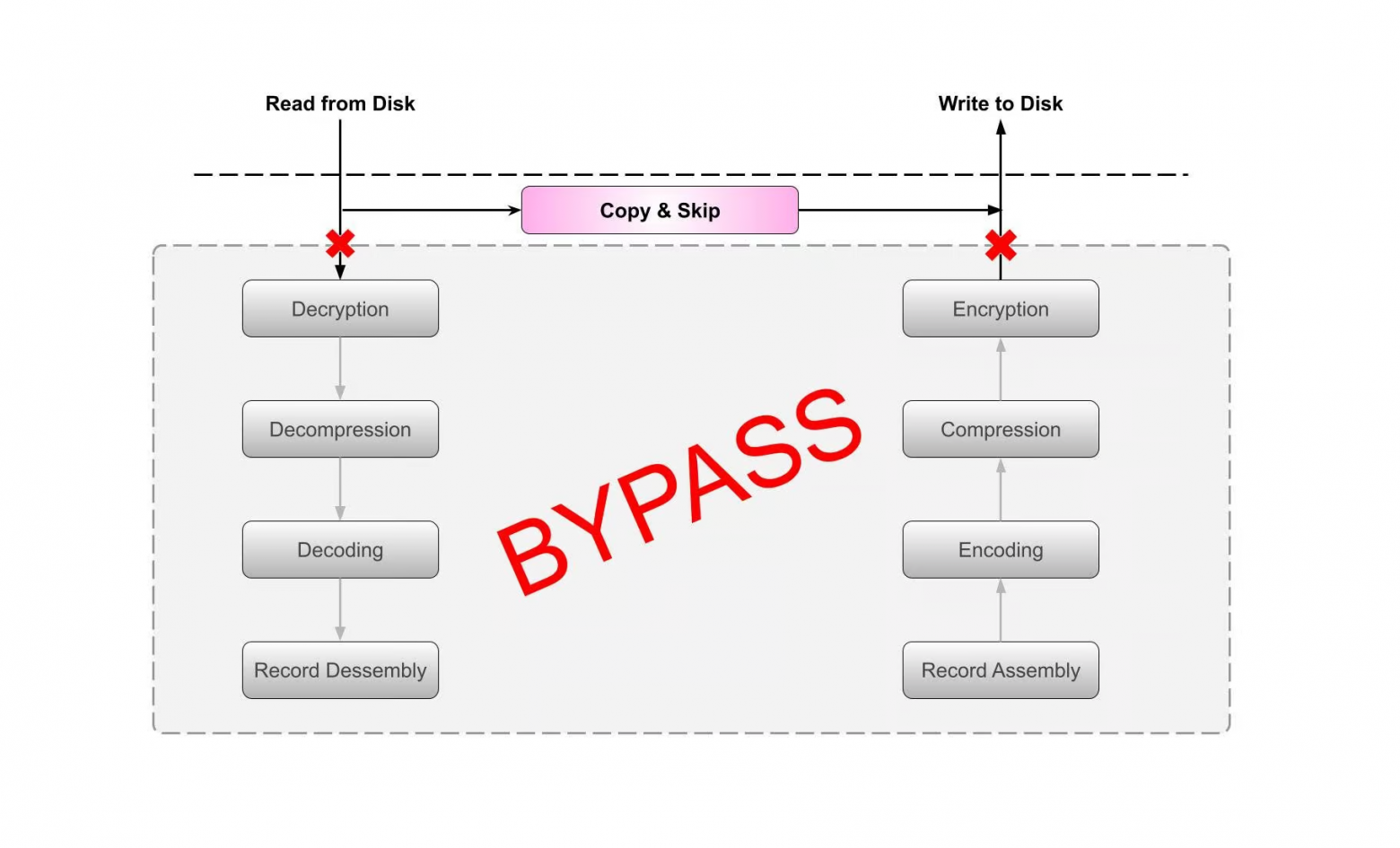
Технически справочник НСИ в учётных системах может представляться в виде набора связанных таблиц в базе данных учётной системы, за содержание которых должен бы назначаться ответственный от бизнеса или группа таковых.