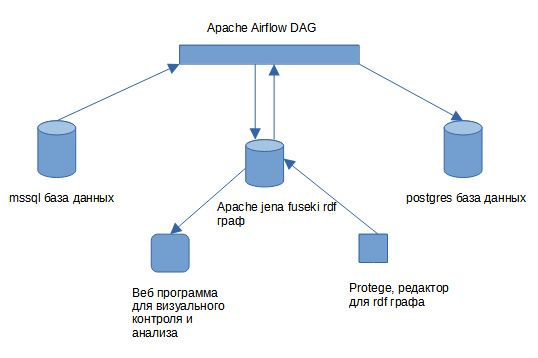
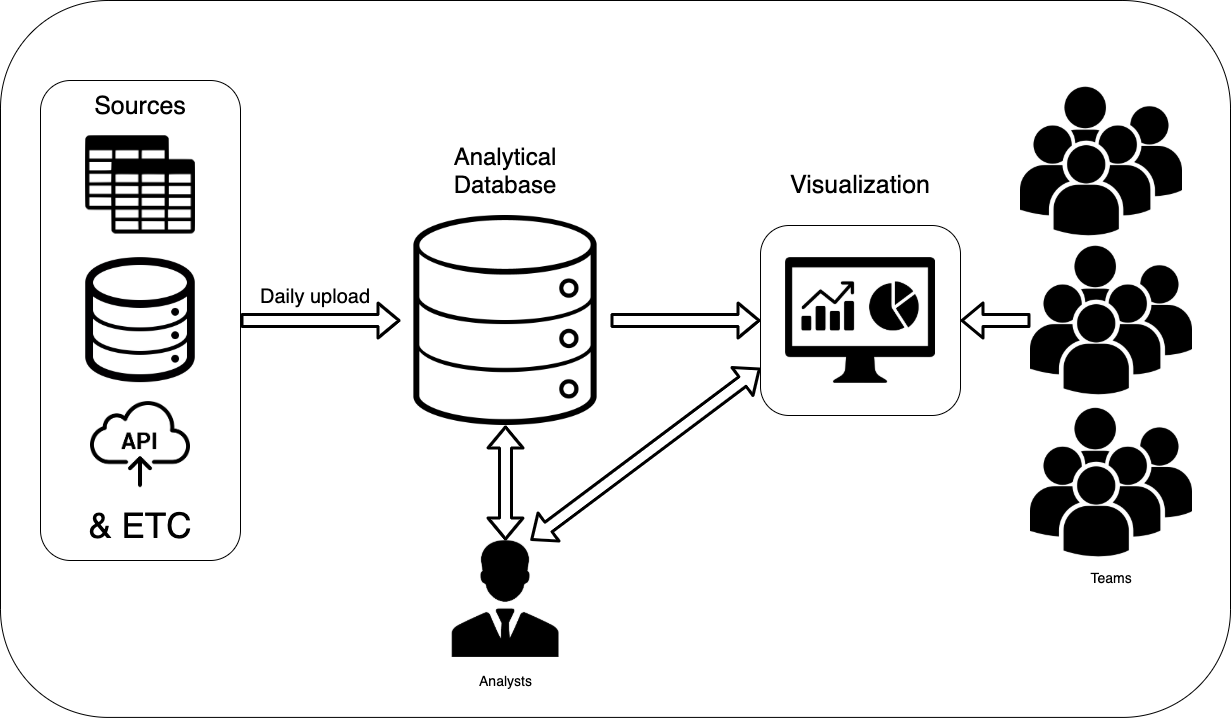
Почему Data Science не для вас?

Data Science сейчас во многом благодаря активному маркетингу становится очень популярной темой. Быть датасаентистом – модно и, как говорят многие рекламки, которые часто попадаются на глаза, не так уж и сложно. Ходят слухи, что работодатели стоят в очереди за возможность взять человека с курсов. Получить оффер на работу крайне легко, ведь в ваши обязанности будет входить требование данных от заказчика (как обычно говорят, чем больше данных – тем лучше) и закидывать их в искусственный интеллект, который работает по принципу черного ящика. Кстати, еще и платят немереное количество денег за всё это.
Спойлер: это не так.
В этой душераздирающей статье решили попробовать отговорить людей, которые готовы оставить кучу денег за курсы по Data Science, браться за это дело, а может быть и помочь определиться с тем, что на самом деле стоит сделать, чтобы встать на путь истинный.