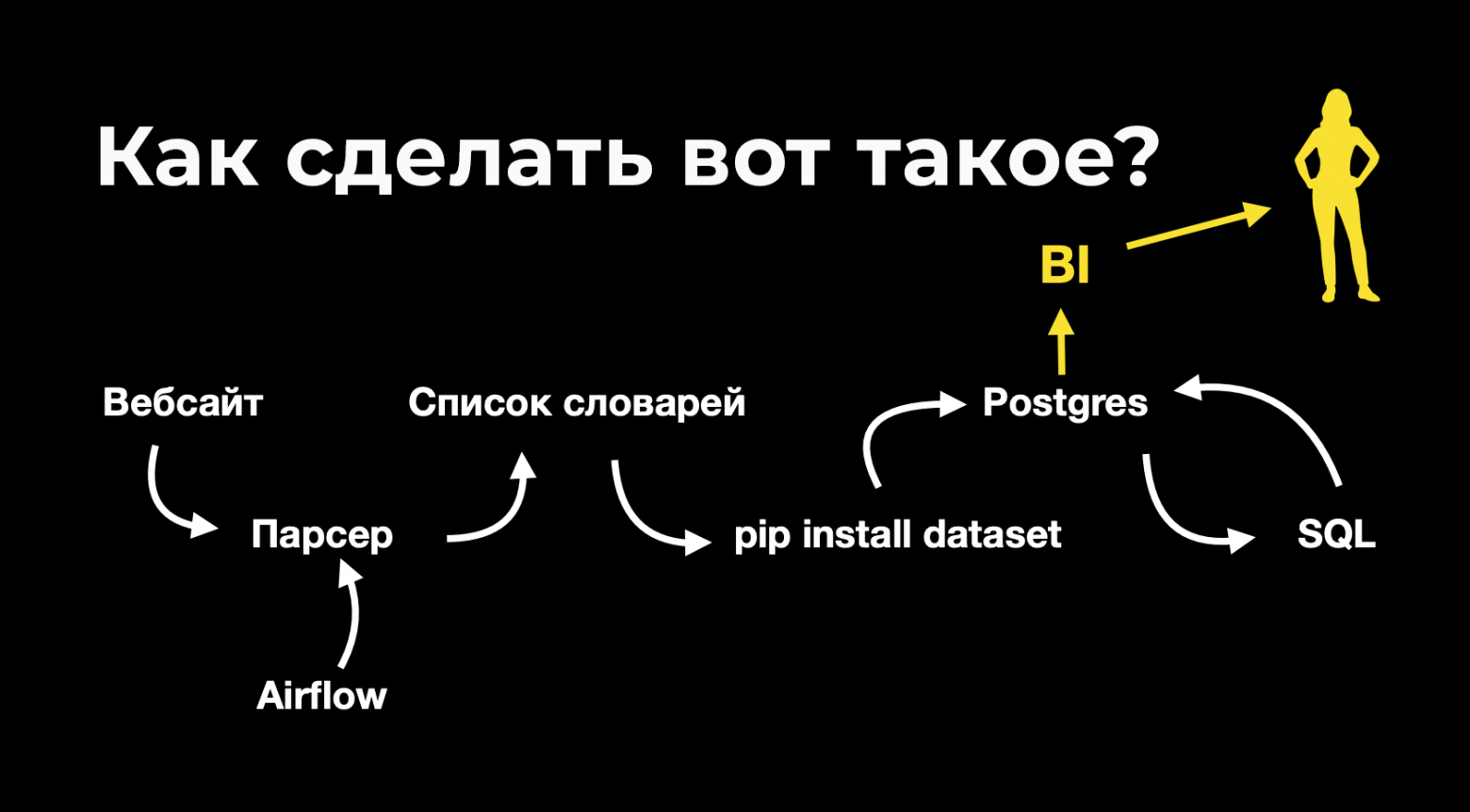
Думаю, многие согласятся, что современный русский язык находится под постоянным давлением со стороны английского в части заимствований. Мы уже обыденно произносим и понимаем фразу типа «когда юзер пытался залогиниться через АДэ, в браузере что-то заглючило, надо винду ребутнуть, наверное». Так получается короче, быстрее, но, кажется, это может плохо кончиться в итоге. Эллочка-людоедка, новояз Оруэлла и бейсик-инглиш Огдена, ю ноу. Корень проблемы в корнях. И мы теряем корни в буквальном смысле слова. Свои корни теряем, а чужие нам не позволяют правильно понимать смысл слов. Поясню на примере.
О чём говорят люди, когда обсуждают Data Governance и Data Management на русском? Давайте разбираться.
Есть в английском два слова примерно об одном и том же: «governance» и «management». При этом «governance» однокоренное с «government» (правительство). Аналогично, в русском языке есть два самых употребляемых слова на эту тему: «управление» и «руководство». При этом, «управление» — однокоренное со словом «правительство». Кроме того, слово «management» восходит к латинскому «manus» (рука), а «руководство» прямо содержит в себе корень слова «рука».
С точки зрения корней, логично переводить «governance» как «управление» (отсылка к «правительству»), а «management» как «руководство» (отсылка к «руке»).
А с точки зрения взаиморастворения культур не всё так однозначно, ибо у них есть «data management» и отдельно «data governance», и всем понятно, что это разные вещи. Там люди чётко понимают, что «governance» выше, чем «management». А у нас редкий человек объяснит, чем «управление» отличается от «руководства». Вот и получается, что использовать Data Governance и Data Management в русском очень трудно, особенно так, чтобы тебя поняли.