Data Mesh – ячеистые топологии для работы с данными
Средний
8 мин
Обзор
Перевод
Из каких соображений можно хранить данные в виде ячеистой сети

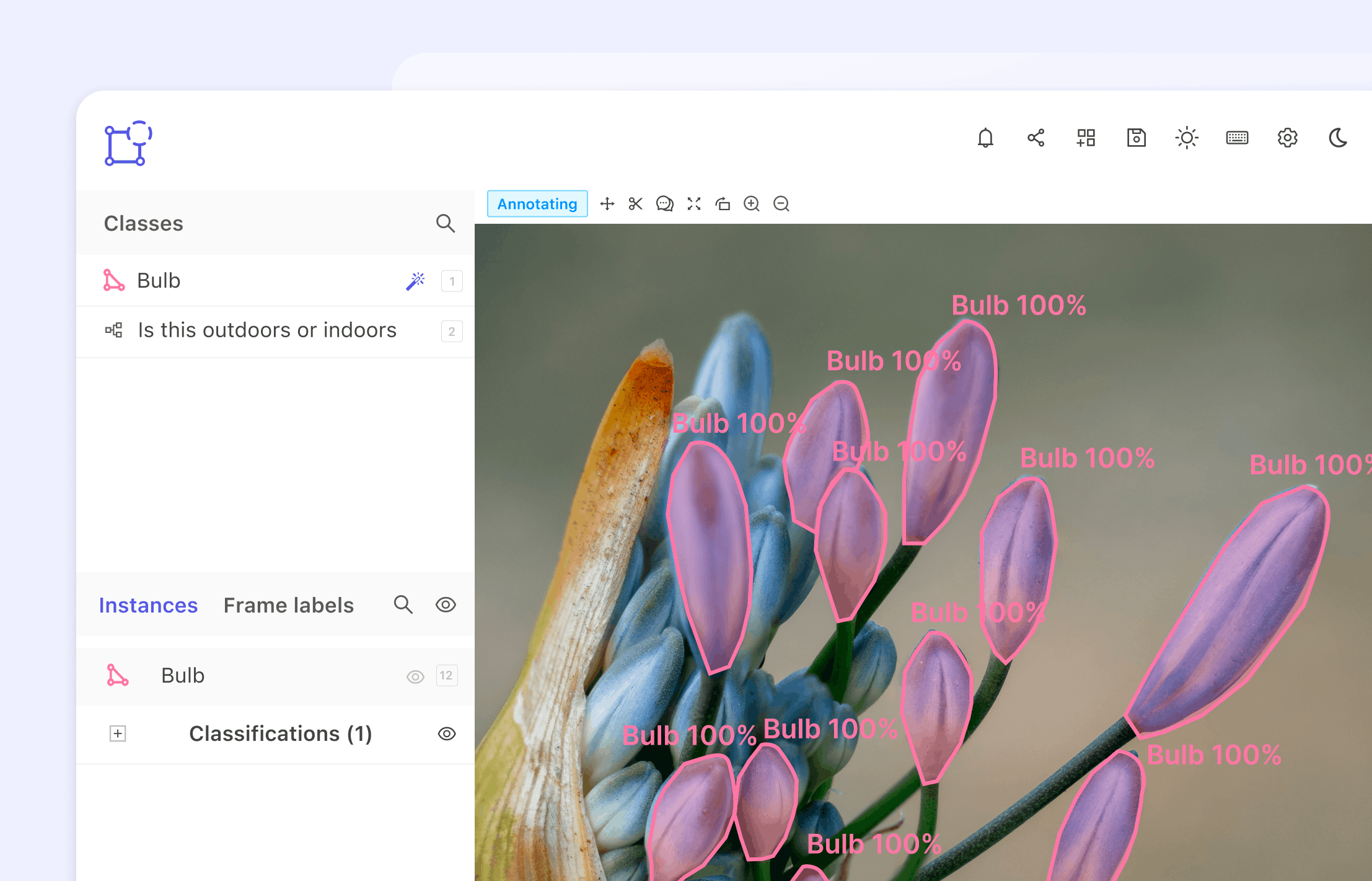
Во всех организациях, где мне доводилось работать, всегда понимали важность данных. Поэтому я видел, что руководство либо заинтересовано, либо прямо планирует создать платформу нового поколения для обращения с этими данными. Как правило, ставится цель перейти от сильно связанных интерфейсов и вариабельных потоков данных к целостной архитектуре, которая позволяла бы аккуратно связать всю экосистему. Речь идёт о распределённой облачной ячеистой топологии (data mesh), где данные можно группировать в зависимости от их предметной области, трактовать “данные как продукт,” организуя в каждой предметной области конвейерную обработку собственных данных. Такой подход отличается от перекачки данных (data plumbing), практикуемой на традиционных (монолитных) платформах, которые, как правило, отличаются сильной связанностью данных. Из-за этого зачастую замедляется поглощение, хранение, преобразование и потребление данных из централизованного озера или хаба.
Такая смена парадигмы в распределённой архитектуре данных сопряжена с некоторыми нюансами и требует учитывать факторы, которые связаны в основном со зрелостью организации, имеющимися навыками, структурой организации, предрасположенностью к риску, размерами организации и динамикой её развития. С учётом всех этих нюансов и соображений могут использоваться различные варианты ячеистой топологии.