Не так давно наткнулся на статью на Хабре о том, как пользоваться Power BI и как проводить с помощью него Простой план-фактный анализ. Автору огромный респект за труд — материал, действительно, полезный. Более чем достаточно для начинающего. Однако, насколько я понял, для многих работа с PQ/PBI так и заканчивается нажатием на кнопочки в интерфейсе.
В принципе, большинству пользователей этого вполне достаточно для решения несложных задач. Тем более, что это самое большинство, что называется, в быту — непрограммистывообщениразу. Да и, как показала практика, далеко не все знают, что в PQ есть режим расширенного редактирования запросов. А между тем, боязнь (нежелание/неумение) копнуть глубже лишает возможности задействовать весь заложенный функционал PQ/PBI в полной мере. Отмечу хотя бы тот факт, что в интерфейсе присутствуют далеко не все кнопочки, для которых есть функции. Думаю, не сильно ошибусь, если скажу, что функций, пожалуй, раза в два больше, чем кнопок.
Если же вы чувствуете, что для решения имеющихся задач вам недостаточно отведённого в интерфейсе функционала и/или есть время удовлетворить академический интерес, добро пожаловать под кат…
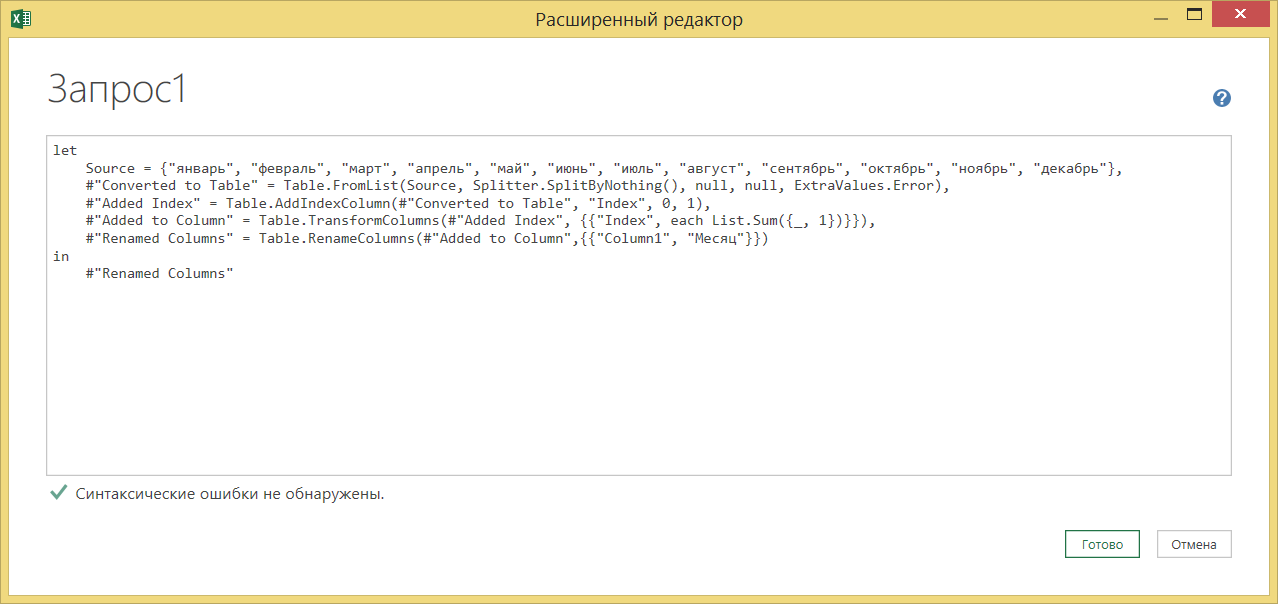
В принципе, большинству пользователей этого вполне достаточно для решения несложных задач. Тем более, что это самое большинство, что называется, в быту — непрограммистывообщениразу. Да и, как показала практика, далеко не все знают, что в PQ есть режим расширенного редактирования запросов. А между тем, боязнь (нежелание/неумение) копнуть глубже лишает возможности задействовать весь заложенный функционал PQ/PBI в полной мере. Отмечу хотя бы тот факт, что в интерфейсе присутствуют далеко не все кнопочки, для которых есть функции. Думаю, не сильно ошибусь, если скажу, что функций, пожалуй, раза в два больше, чем кнопок.
Если же вы чувствуете, что для решения имеющихся задач вам недостаточно отведённого в интерфейсе функционала и/или есть время удовлетворить академический интерес, добро пожаловать под кат…