О KNIME
Вашему вниманию представляется обзор Knime Analytics Platform – open source фреймворка для анализа данных. Данный фреймворк позволяет реализовывать полный цикл анализа данных включающий чтение данных из различных источников, преобразование и фильтрацию, собственно анализ, визуализацию и экспорт.
Скачать KNIME (eclipse-based десктоп приложение) можно отсюда: www.knime.org
Кому может быть интересна эта платформа:
- Тем, кто хочет анализировать данные
- Тем, кто хочет анализировать данные и не владеет навыками программирования
- Тем, кто хочет покопаться в неплохой библиотеке реализованных алгоритмов и, возможно, узнать что-то новое








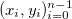 и соответствующий им набор положительных весов
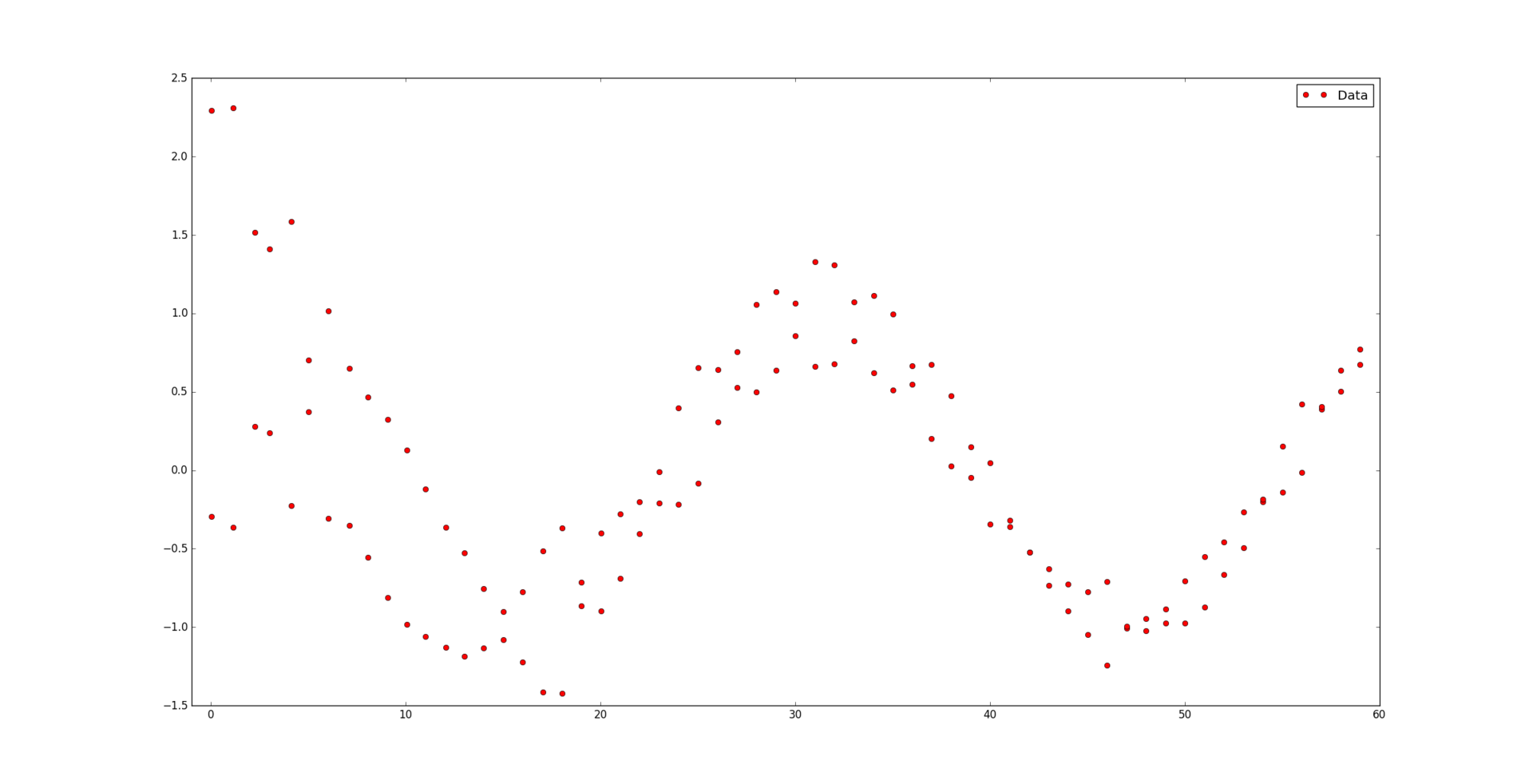
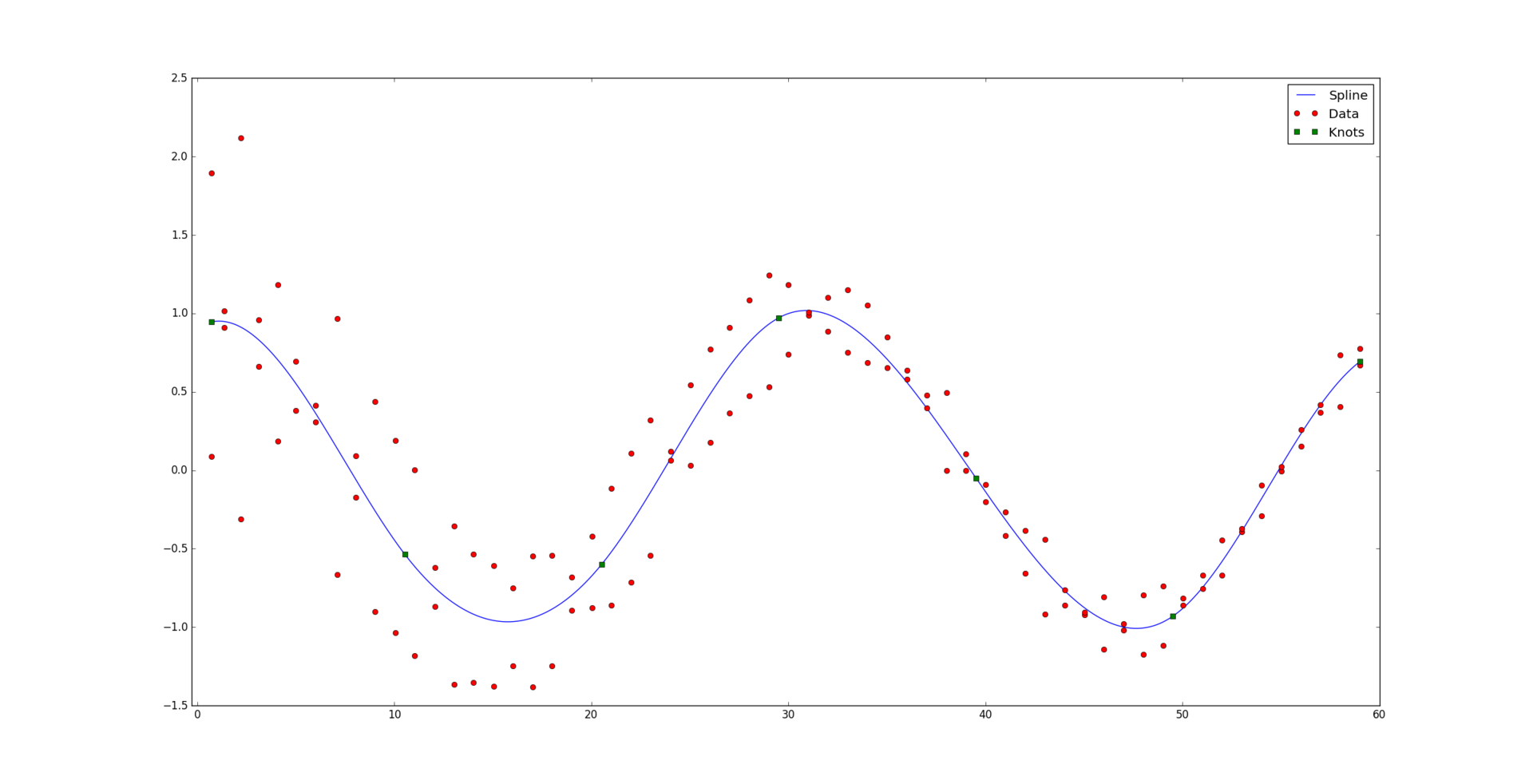
и соответствующий им набор положительных весов 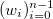 . Мы считаем, что некоторые точки могут быть важнее других (если нет, то все веса одинаковые). Неформально говоря, мы хотим, чтобы на соответствующем интервале была проведена красивая кривая таким образом, чтобы она «лучше всего» проходила через эти данные.
. Мы считаем, что некоторые точки могут быть важнее других (если нет, то все веса одинаковые). Неформально говоря, мы хотим, чтобы на соответствующем интервале была проведена красивая кривая таким образом, чтобы она «лучше всего» проходила через эти данные.