
Использование InfluxDB для мониторинга систем хранения данных
20 мин
Всем привет! Cегодня я расскажу, как применять InfluxDB для мониторинга систем хранения данных. Я затрону следующие темы:
В конце я расскажу, какие преимущества всё это нам дало и о некоторых из созданных нами инструментальных панелей.
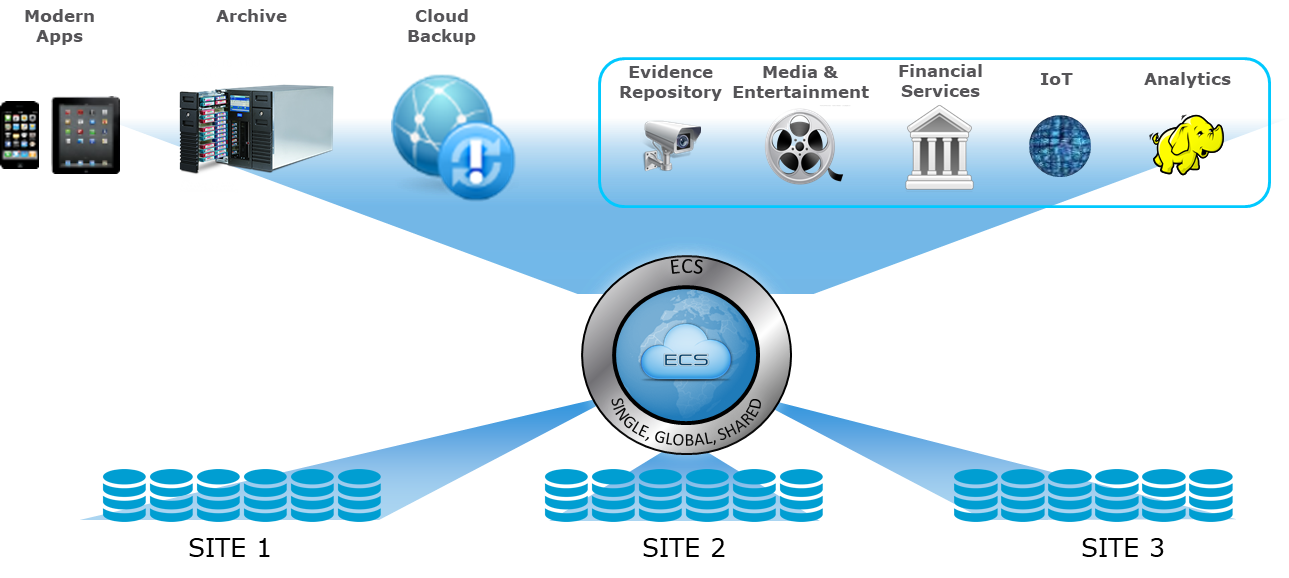
- Наше путешествие в стек мониторинга InfluxDB для мониторинга систем хранения ECS.
- Как мы добавили High Availability в версию InfluxDB c открытым исходным кодом.
- Как мы улучшили слой вычисления запроса, выделив его из InfluxDB и сделав его горизонтально масштабируемым.
- Как мы смогли развернуть стек InfluxDB на ресурсах со сравнительно небольшим объёмом памяти.
- И наконец, как мы смогли включить стек мониторинга для хранилища ECS в несколько этапов.
В конце я расскажу, какие преимущества всё это нам дало и о некоторых из созданных нами инструментальных панелей.

















