Простой план-фактный анализ в Power BI Desktop. Часть вторая – визуализация
4 мин
Туториал
Всем привет!
Перед вами продолжение рассказа про план-фактный анализ в Power BI Desktop. Первую часть можно почитать здесь. Если хотите прочитать в целом про платформу Power BI, то добро пожаловать сюда.
Сегодня расскажу про построение интерактивных отчётов и совсем немного про создание вычисляемых полей в Power BI Desktop. Под катом будет много гифок, так что аккуратнее с трафиком.
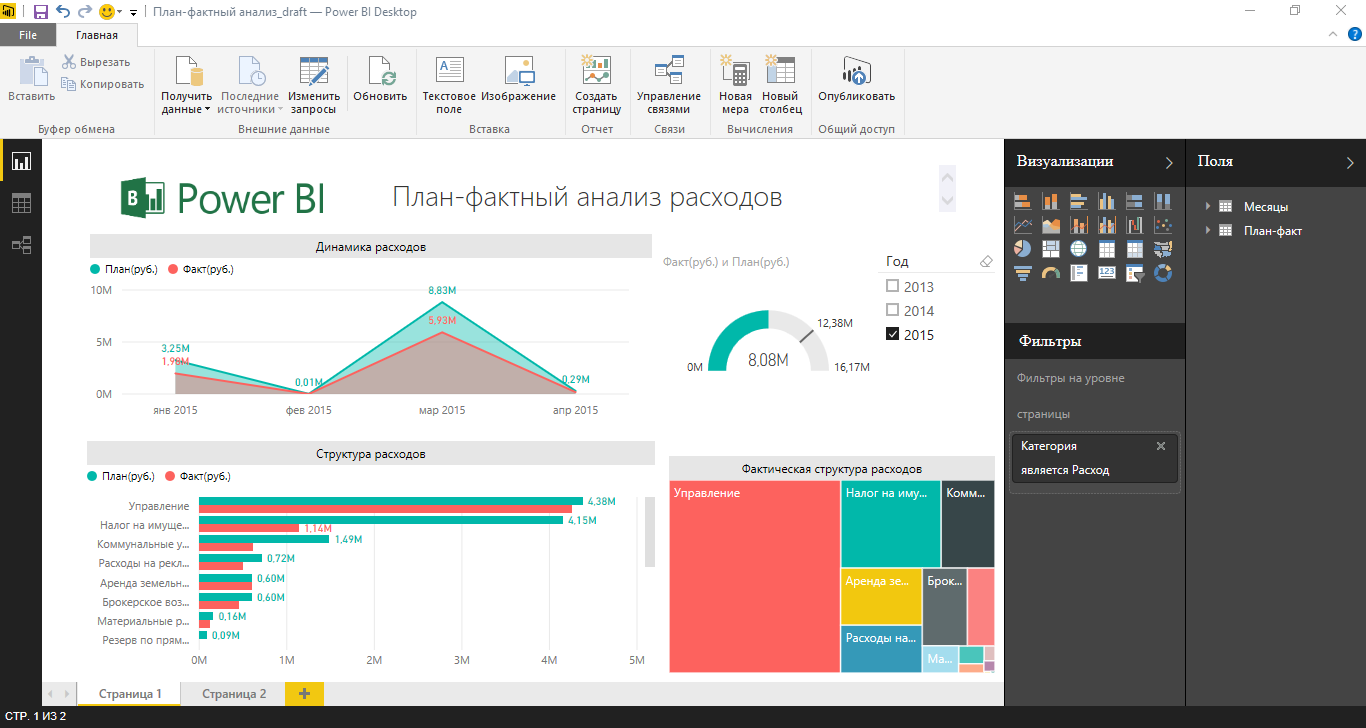
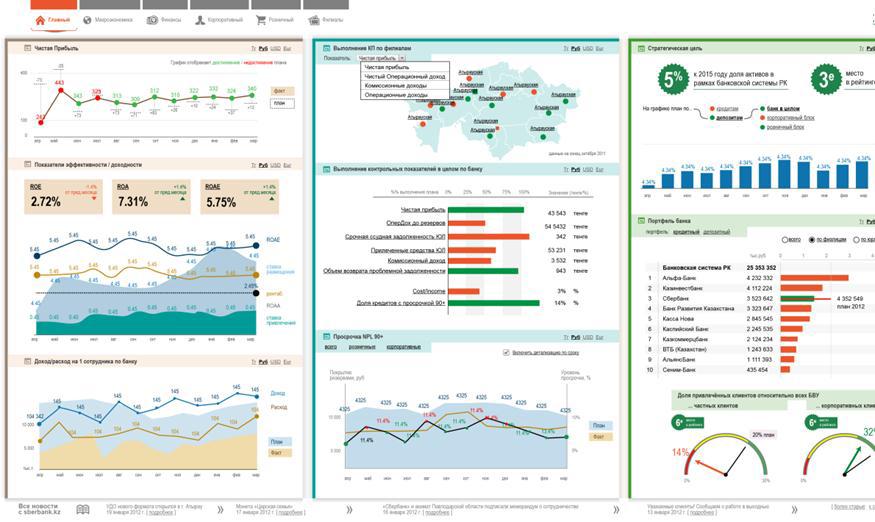
Рисунок 1. Внешний вид Power BI Desktop
Перед вами продолжение рассказа про план-фактный анализ в Power BI Desktop. Первую часть можно почитать здесь. Если хотите прочитать в целом про платформу Power BI, то добро пожаловать сюда.
Сегодня расскажу про построение интерактивных отчётов и совсем немного про создание вычисляемых полей в Power BI Desktop. Под катом будет много гифок, так что аккуратнее с трафиком.
Рисунок 1. Внешний вид Power BI Desktop