

Интересно, как работают технические транзакции с Camunda и фреймворком Spring? Узнайте больше о транзакционном поведении в этом посте.
Интересно, как работают технические транзакции с Camunda и фреймворком Spring? Узнайте больше о транзакционном поведении в этом посте.

Переезд с Microsoft на Linux - это то, с чем сталкивается последнее время практически каждый инженер, и меня сия чаша тоже не миновала. Но за годы работы с MS я привык раздавать права на все что угодно через группы в AD и отказываться от этого совершенно не хотелось.
Запросы к вендеру, поиск инструкций в интернете не принес желаемого результата и как обычно в опенсорсе пришлось разбираться самому как реализовать свою хотелку.

В статье рассматривается пошаговое создание образов «с нуля» для контейнерного движка Podman. Внутрь контейнера «упакована» база данных Oracle Database 21c Express Edition. И всё это отечественной операционной системе РЕД ОС.
*2 контейнера

Как эффективно организовать процесс обмена знаниями в компании, минимизировать потерю времени и повысить продуктивность команды. В статье делимся проверенными инструментами и подходами из личного опыта техписов, которые сделали взаимодействие внутри команды удобным и результативным.
Всем привет. На днях пришлось вспомнить магию Postgres, задача была решена, по результатам написал инструкцию в корпоративную базу знаний, что бы в следующий раз не тратить время на "воспоминания". Решил поделиться.
Ниже речь будет идти о чтении данных одной БД из другой БД. В частности я решал такую проблему:
В нашей Системе данные о пользователях записаны в одной БД, а данные об их торгах в другой, без дополнительных настроек Postgres не позволяет использовать в одном запросе данные из разных БД.
То есть запрос вида:
select a.id from auth.public.user a join trade.public.tenders t on a.id = t.user_id;
Вызовет ошибку "[0A000] ERROR: cross-database references are not implemented".
Что делать ?

Существуют различные шаблоны проектирования облачных сервисов. Про тот же Sidecar или Ambassador, я думаю, слышали многие. Шаблоны предназначены для решения определенных задач и те два шаблона, о которых речь пойдет в сегодняшней статье, тоже нужны для конкретной задачи — работы с базами данных.
СУБД является неотъемлемой частью хоть сколько‑нибудь серьезного современного приложения. Соответственно, при проектировании приложения может возникнуть вопрос, как лучше сервисам взаимодействовать с базой данных: предоставляя общий доступ к одной базе или же у каждого микросервиса должна быть своя база данных. Мы рассмотрим два шаблона, предназначенных для решения данной задачи — это Shared database и Database per Microservice. Начнем с Shared database.
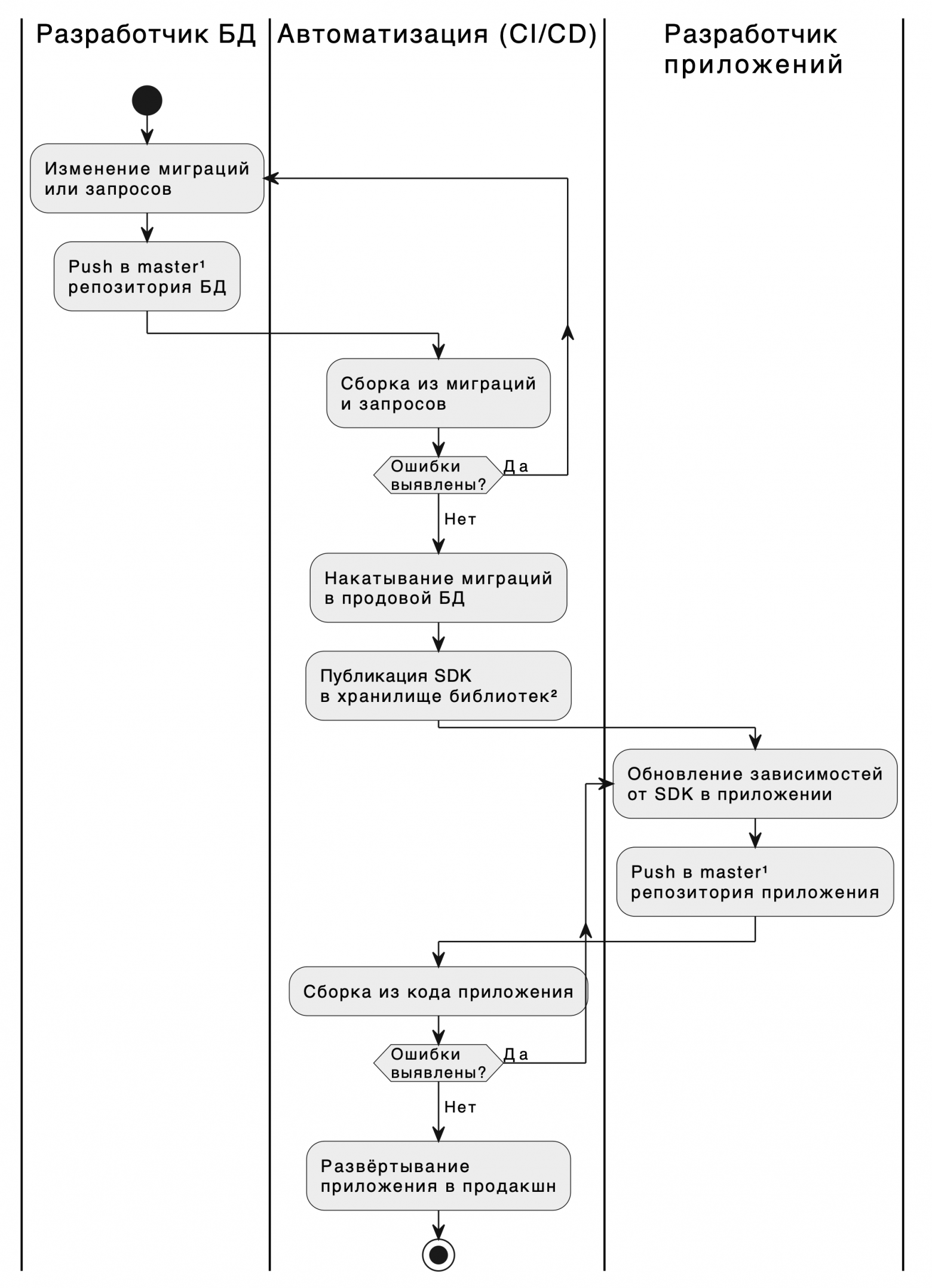
В статье рассматривается Continuous Deployment для БД с бесшовными релизами за счёт обратно-совместимых обновлений и автоматизации проверок совместимости с помощью подхода DB-First.

Первоначальная документация YDB, опубликованная в рамках open-source запуска в 2022 году, имела структуру, на которую в значительной степени повлиял закон Конвея. Создание проекта с открытым исходным кодом значительно повышает планку того, что ожидается от документации по технологии. В нашем случае для быстрого создания большого количества контента перед запуском потребовалась командная работа по принципу «разделяй и властвуй». На раннем этапе такое четкое владение каждым фрагментом было полезным. Однако, поскольку общий объем документации со временем продолжает расти, читателям становится всё труднее находить нужную им информацию. Чтобы решить эту проблему, мы перепроектируем структуру документации, чтобы она была ориентирована на пользователя. Таким образом, если вы являетесь командой, работающей с кластером YDB, каждый может иметь свою собственную любимую директорию в документации в соответствии со своей ролью в команде и не отвлекаться на контент, ориентированный на читателей с другой ролью.
Эта реструктуризация ещё в процессе: появился новый раздел для DevOps-инженеров, а также дополнительные разделы для администраторов баз данных, разработчиков приложений, инженеров по безопасности, аналитиков и т.д. Перемещение контента может потребовать выработки новых привычек, но в долгосрочной перспективе такая структура должна упростить навигацию. Мы создаём перенаправление со старого URL на новый при перемещении любой страницы документации, чтобы свести неудобства к минимуму.

Чего у меня не отнять, дак это мастерства заголовка...
В какой-то момент при локальной разработке (да, в общем-то и при тестировании на иных стендах) задумываешься о том, как бы избавиться от довольно монотонных действий. Одним из них является ввод пароля в рамках процесса аутентификации в PostgreSQL. В этой статье я расскажу как слегка автоматизировать данный процесс.
Данная статья является легким переосмыслением того, что я написал на медиуме. Ибо думать я продолжаю на русском.
TL;DR исходники к вашим услугам.
В рамках любых взаимодействий мы сталкиваемся с такими сущностями как авторизация и аутентификация. Повторять в 100500 раз что есть что я не буду (но мне не лень такую длинную ремарку напечатать, ага). В рамках PostgreSQL первое обеспечивается через Roles, а второе через Privileges.

Приветствую, current_user()!
Хочется тебе показать, как можно хранить sql-скрипты объектов БД так, чтобы было удобно и разработчику, и ревьюеру, а так-же рассказать о плюсах и минусах такого подхода.
Так-же хотелось-бы узнать твоё мнение о таком подходе и обсудить, возможно стоит что-нибудь добавить в нём.

Любая компания, ориентированная на персоналистское взаимодействие с пользователем, так или иначе занимается сбором, обработкой и сохранением его персональных данных (ФИО, возраст, электронная почта, место проживания или пребывания, объемы приобретенных товаров и многое другое). Подобные материалы интересны хакерам и иным злоумышленникам: правильно обработав эту информацию, всегда возможно, используя инструменты социальной инженерии, получить доступ к деньгам клиента.

В последние месяцы в мире FirebirdSQL происходит значительное оживление: помимо релиза Firebird 5 было опубликовано много инструментов, статей и материалов, что я решил подготовить небольшой дайждест для читателей Хабра, которые, вероятно, соскучились по новостям о любимой СУБД.
Во-первых, вышла новая версия Калькулятора Конфигураций для Firebird, с поддержкой Firebird 5. В калькулятор (полностью бесплатный, доступен без регистрации) вводятся характеристики сервера, ...

Речь сегодня пойдет об отказоустойчивости и даже о катастрофоустойчивости.
Почему вроде бы правильно настроенное архивирование базы данных не всегда помогает спасти систему в случае инцидентов? Этим вопросом я, наверное, многих даже задел за живое. Одних тем, что сама постановка вопроса им кажется абсурдной – у этой группы админов все настроено идеально, работает как часы и они готовы к любым катаклизмам. А кого-то тем, что напоминаю о тех самых инцидентах, когда возвращаться в тот день, даже мысленно, совсем не хочется.
В рамках проектов аудита производительности мы обязательно проверяем систему заказчика на предмет используемых средств отказоустойчивости и катастрофоустойчивости. И если есть основания, обязательно предоставляем рекомендации по улучшениям. Соответствующий раздел в своё время стал обязательным в каждом отчёте аудита не на пустом месте. За долгие годы мы встречались с таким количеством ситуаций, что можно начинать писать книгу :) Сама по себе ситуация краха системы редкая, поэтому вопросы отказоустойчивости далеко не везде в приоритете, а с учетом распространения в последние годы разнообразных ЦОД’ов, появляется большой соблазн снять с себя ответственность за целостность базы данных и непрерывного доступа к ней. Так что, с появлением ЦОД’ов люди совсем расслабились. А зря.
Опишу несколько характерных примеров из нашей практики, с которыми мы столкнулись, причем в роли спасателей клиентской инфраструктуры и данных. Иногда на кону стояло само существование БД, иногда – интервал потерянных данных, иногда – время простоя бизнеса.
MySQL продолжает наращивать инновации и теперь включает в себя богатые возможности процедурного программирования внутри базы данных. Отныне разработчики могут писать хранимые программы на языке JavaScript (функции и процедуры) в сервере баз данных MySQL. Хранимые программы будут выполняться с помощью GraalVM. Эта версия доступна в качестве "Preview" в MySQL Enterprise Edition и может быть загружена через Oracle Technology Network (OTN). MySQL-JavaScript также доступен в облачном сервисе MySQL Heatware на OCI, AWS и Azure.

Под занавес уходящего года предлагаю традиционно вспомнить, про какие интересные возможности и особенности работы с PostgreSQL мы рассказали в нашем блоге.
Если не видели дайджест за прошлый год — время наверстать упущенное!

В Postgres достаточно подробная документация, и видимо поэтому , при инсталляции Postgres для 1С большинство параметров приходится выставлять самим. Параметров в Postgres много, а составить эффективную комбинацию не так просто. Все упрощается если рассмотреть профиль нагрузки, например, 1С это прежде всего профиль OLTP нагрузки – так устроены его метаданные (объекты). Если сосредоточится на оптимизации профиля OLTP, понимание Postgres сразу упростится.

Для эффективного хранения и обработки таких объемных и динамичных данных требуются специальные базы данных. Традиционные реляционные базы данных могут быть неэффективны в работе с временными рядами из-за их большого объема и сложности обработки. Поэтому существуют специализированные базы данных для временных рядов (TSDBMS), которые предназначены именно для этой задачи.
TSDBMS обладают оптимизированными структурами данных и индексами, которые позволяют справляться с высокой частотой обновления данных и проводить сложные операции агрегации и анализа. Они также предоставляют механизмы для горизонтального масштабирования и обеспечения отказоустойчивости, что критически важно при работе с такими динамичными данными.

Если вы работает с базами данных, то, скорее всего, знакомы с B-tree индексами. У них множество применений и они являются дефолтными типами индекса в большинстве движков баз данных. Если вы работаете с полнотекстовым поиском или пространственными данными, то скорее всего вы знакомы еще и с GIN и GIST индексами. Если вы работаете с массивными временными рядами, то слышали еще и о BRIN индексах.
Однако, есть еще один менее популярный тип, о котором большинство даже ничего не слышало. Пару версий PostgreSQL назад он был не то что даже непопулярен, но и строго не рекомендован к использованию. Однако в некоторых случаях он может обойти даже B-tree в плане производительности.
Сейчас мы переоткроем хэш-индекс!

Как внедрить Change Data Capture в Oracle и при этом не отдать все ресурсы
Современную жизнь теперь уже невозможно представить без цифровых технологий. Объем доступных и собранных данных существенно вырос, в результате чего стали появляться ограничения для традиционно используемых инструментов анализа и хранения данных, и именно тогда и возникло понятие больших данных.
А для решения проблем хранения и обработки больших объемов данных возникает потребность в их репликации из классического хранилища-источника в аналитическое хранилище для проведения аналитики без влияния на продуктивную эксплуатацию. Для обеспечения актуальности данных в аналитическом хранилище, их необходимо обновлять их при изменении операционных данных источника. Однако, простая перезагрузка данных - неэффективна, так как обычно изменяется только небольшая часть исходных данных. Поэтому в качестве решения предлагается использовать инкрементную загрузку данных с использованием паттерна "Change Data Capture", которая будет актуализировать аналитическое хранилище посредством периодического обновления данных, которые были изменены.
CassandraDB – она же просто Кассандра – хорошо зарекомендовала себя в нише высокопроизводительных NoSQL баз данных. Но, вот, её активно стала вытеснять ещё более быстрая, надежная и легко масштабируемая ScyllaDB - этакая Кассандра++. Как тут удержаться и не проверить, так ли прекрасна эта зверушка, как про неё говорят её создатели? Тем более вендоры других популярных баз данных того и гляди закроют поддержку для российских пользователей. Нужно иметь под рукой пару-тройку запасных вариантов. Сегодня мы рассмотрим, как одноглазый монстрик приживается в диких условиях кровавого энтерпрайза, и насколько целесообразно его использовать.
Об этом расскажет Илья Орлов, техлид компании STM Labs. Вместе с командой он разрабатывает высоконагруженные решения для всевозможных задач: бизнес-порталов с использованием собственной платформы, мониторинга фискальных данных и прочее. Они любят экспериментировать с разными БД, поэтому статья будет об использовании ScyllaDB на промышленных мощностях.