Всем привет. В данной статье хочу поделиться знаниями, полученными в процессе автоматизации развертывания наших сервисов на различные серверы в разных дата-центрах.
Задача была следующей: есть определенный набор скриптов для развертывания сервисов, которые нужно запускать на каждом сервере каждого дата-центра. Скрипты выполняют серию операций: проверка статуса, вывод из-под load balancer’а, выпуск версии, развертывание, проверка статуса, отправка уведомлений через email и Slack и т.д. Это просто и удобно, но с ростом числа дата-центров и сервисов процесс выкатки новой версии может занять целый день. Кроме того, за некоторые действия отвечают отдельные команды, например, настройка load balancer’а. Также хотелось, чтобы управляющий процессом код хранился в общедоступном репозитории, дабы каждый член команды мог его поддерживать.
Решить задачу удалось с помощью Jenkins Pipeline Shared Libraries: этапы процесса разделились визуально на логические части, код хранится в репозитории, а осуществить доставку на 20 серверов стало возможно в один клик. Ниже приведен пример подобного тестового проекта:
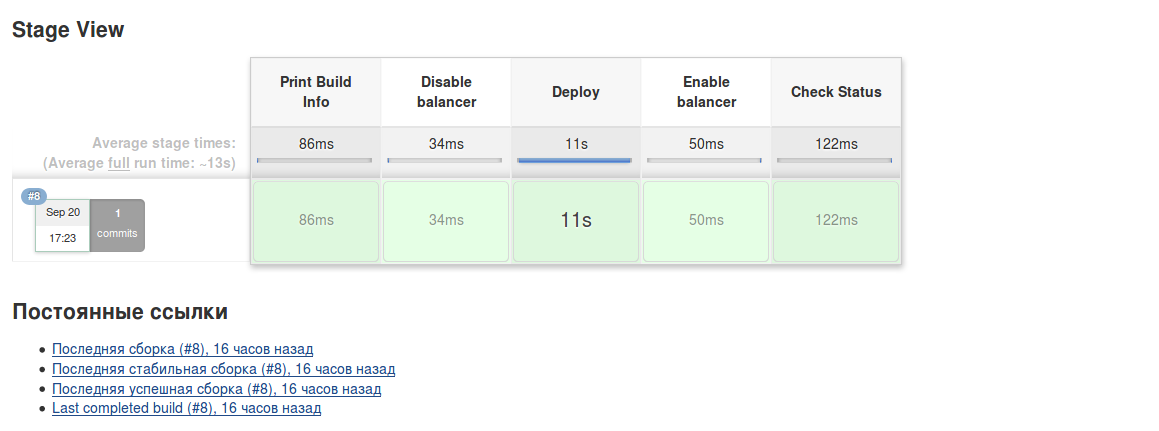
Сейчас я расскажу и покажу примеры как этого достичь. Надеюсь эта статья поможет сохранить время другим разработчикам, а также буду рад дельным комментариям.










 Сетевые политики (Network Policies) — это новая функциональность Kubernetes, которая за счет создания брандмауэров позволяет настроить сетевое взаимодействие между группами подов и других узлов сети. В этом руководстве я постараюсь объяснить особенности, не описанные в официальной документации по сетевым политикам Kubernetes.
Сетевые политики (Network Policies) — это новая функциональность Kubernetes, которая за счет создания брандмауэров позволяет настроить сетевое взаимодействие между группами подов и других узлов сети. В этом руководстве я постараюсь объяснить особенности, не описанные в официальной документации по сетевым политикам Kubernetes.