Что такое эксплореры блокчейна. Как читать историю транзакций в обозревателе блоков
5 мин

Зачем нужен обозреватель блокчейна и как смотреть транзакции в блоке.
Краткое содержание:
Зачем нужны обозреватели блоков

Нюансы проектирования распределенных систем
Зачем нужен обозреватель блокчейна и как смотреть транзакции в блоке.
Краткое содержание:
Зачем нужны обозреватели блоков


В этой статье разберем вариант реализации функционала перезапроса сообщений из семейства resilience шаблонов. Мы поговорим о retry. Точнее обсудим:
1. Что такое устойчивость и какое влияние на нее имеет retry?
2. Анализируем, где применять retry;
3. Реализуем retry;
4. Пишем unit-тесты с wiremock;
5.Делаем starter;
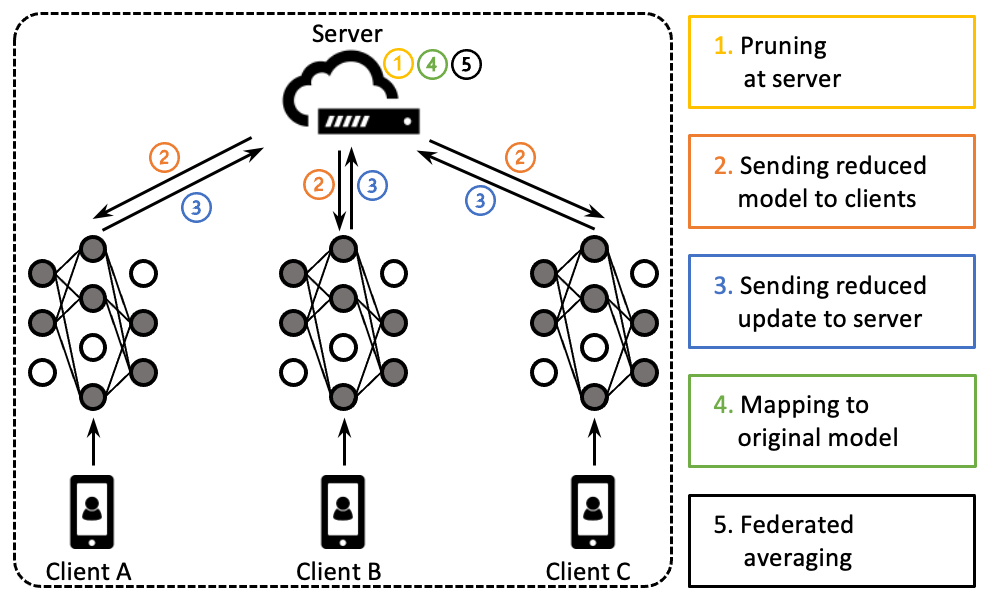
Эта публикация является компиляцией изученных материалов по теме и писалась с целью в материале разобраться и упорядочить собственные знания – такой аналог реферата/курсовой. Т.к. исходный материал в основном на английском, возможно, данная статья кому-то также будет полезна.
Вместо пролога
Federated Learning – подход к решению задач машинного обучения, который позволяет анализировать данные непосредственно в их источниках, не объединяя их на каком-то центральном ресурсе, а объединяя уже результаты таким способом, чтобы итог обучения был не хуже, чем в традиционных подходах.
Есть две «легенды» появления FL. Первая рассказывает о данных столь больших, что обучение на них занимает недели и даже месяцы. Данные стали разбивать на части. Затем части отдавать отдельным вычислительным узлам. Затем данные перестали собирать и стали обрабатывать прямо в источниках.
Вторая «легенда» – о конфиденциальности тренировочных данных. Трудности обезличивания данных (как ни хэшируй, а информацию с конкретным объектом можно сопоставить, особенно если количество наблюдений в источнике невелико) привели к мысли передавать не сами данные, а результаты обучения на них.
(«Легенды» – потому что у всякой версии есть примеры обратного: медицинские данные не велики, а наоборот, малы и трудно собрать их в одном месте – какое уж тут разбиение, тут проблема в том, что для глубокого обучения такие малые выборки не дадут хорошей эффективности, нужно не данные обрабатывать, а развивать методы машинного обучения на малых данных.)

Привет, Хабр.
Меня зовут Владимир Евсеев, я Senior Java developer, Teamlead в SSP SOFT.
Наша команда приступила к масштабному проекту: системе, обеспечивающей транспортный уровень документооборота банка. Сегодня я расскажу, как мы справились с первым этапом: выстроили магистраль, способную передавать около 150 000 файлов в сутки, или 1,5 терабайта информации. Поделюсь, что получилось и что еще предстоит довести до совершенства.

Ссылка на видео-туториал и подробное объяснение
В этом материале речь пойдет про стандарт EIP-2535, также широко известен как Diamond или Multi-Facet Proxy. Стандарт дает возможность создавать модульные, обновляемые смарт контракты, которые обладают рядом преимуществ перед такими стандартами обновляемых контрактов как Transparent и UUPS.

В 2022 г. в результате хакерских атак блокчейны потеряли токенов более чем на 1 млрд. долларов США. Самые крупные ограбления произошли в результате атак на блокчейн-мосты. Что такое блокчейн-мост? Какие уязвимости он в себе таит? Есть ли у этой технологии будущее?

В этой статье поговорим о Greenplum — СУБД, основанной на PostgreSQL. Разберём её общую архитектуру, способы хранения данных, а также перечислим проблемы, с которыми можно столкнуться в ходе эксплуатации.

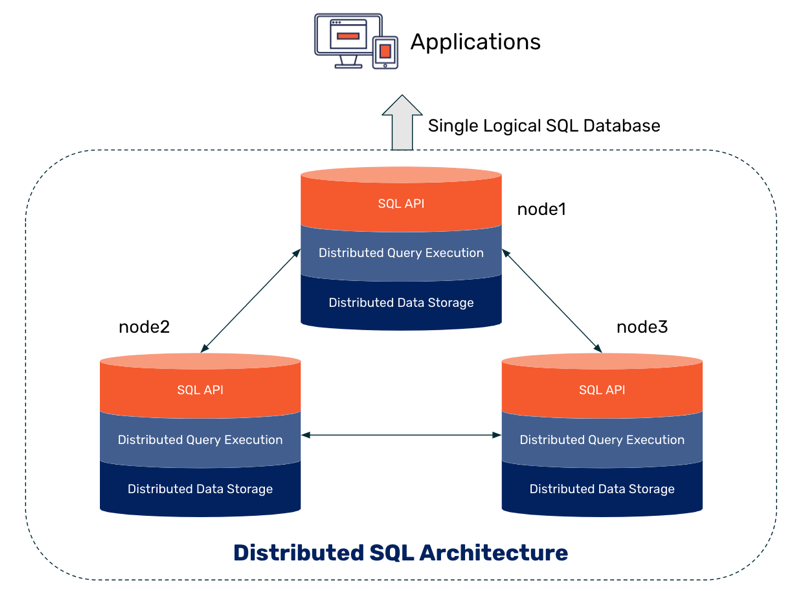
Привет! Меня зовут Пётр, я менеджер по отказоустойчивости в QIWI. В этом посте мы поговорим про выбор новых классов продуктов. Как-то раз мы с одним разработчиком из другой компании стали обсуждать, почему бы не выбрать для работы какую-то распределенную СУБД, поддерживающую SQL? Из этой дискуссии родился мой доклад для нашей QIWI Server Party. Представляю вам его текстовую версию.

В статье - о механизме шардинга (распределения данных) смарт-контрактов в блокчейне TON.
Это именно то дизайн-решение, которое потенциально позволит TON обслуживать миллиарды пользователей без деградации в скорости и цене транзакций.
Жетоны (Jettons) - TON'овский аналог ERC20 токенов из Ethereum.

Системы оркестрации контейнеров существенно упростили управление многокомпонентными системами, в том числе основанными на микросервисной архитектуре. Но остался открытым вопрос организации надежного обмена сообщениями между микросервисами, координации последовательности операций при распределенной архитектуре. В этой статье мы рассмотрим подход Incubating (CNCF)-проекта Dapr (Distributed Application Runtime) по использованию Sidecar-контейнеров в Kubernetes для реализации микросервисной архитектуры, основанной на событиях.

В первой теоретической части мы поговорили про то, что такое обновляемый смарт-контракт и как работают обновления.
Напомним, что большинство вещей всегда требует некоторого обновления. Но тогда данные, хранящиеся в блокчейн, неизменяемы. Так как же тогда смарт-контракты могут быть обновляемыми?
Короткий ответ заключается в том, что смарт-контракты сами по себе не могут изменяться - они постоянны и неизменяемы после развертывания на блокчейне. Но dApp может быть разработан таким образом, чтобы один или несколько смарт-контрактов работали вместе, обеспечивая его "бэкенд". Это означает, что мы можем обновить схему взаимодействия между этими смарт-контрактами. Модернизация смарт-контракта не означает, что мы изменяем код развернутого смарт-контракта, а означает, что мы меняем один смарт-контракт на другой. Мы делаем это таким образом, что (в большинстве случаев) конечному пользователю не придется менять способ взаимодействия с dApp.

ИТ в медицине — достаточно скользкая тема. Нужно отметить, что за последние 10 лет реально растет "проникновение" (как выражаются бюрократы) ИТ в медицину и в здравоохранение в целом. Спецы, работающие в линейных МО (мед. организациях), не дадут соврать. Мне даже представляется, что РФ не то, что отстает, но даже где-то и опережает глобальные тренды. Правда, на мой взгляд, есть разрыв между собственно технологиями и уровнем подготовки и мотивации пользователей, для которых они создаются. Ну и сами ИТ решения не всегда решения, а, скорее, головная боль
Любой МО нужен софт, и не просто бухгалтерский 1С, управление торговлей и CRM, нужен специализированный, МИСы (медицинские информационные системы), и не одна. Нужно вести учет приема пациентов, как-то получать, анализировать и хранить диагностические данные (изображения, графики, результаты анализов, и много чего еще), вести карты с записями о болезнях и т.д. и т.п.
Если МО участвует в программе обязательного мед. страхования (ОМС), она должна ежемесячно формировать и отправлять в территориальный (федеральный) фонд ОМС (ТФОМС) отчеты о количестве принятых в МО пациентов, характере и стоимости оказанной им мед. помощи. Без этого, никак нет возможности получить денежное возмещение от страховых компаний за оказанные услуги.
Собственно отчет — это 2-3 XML файла, упакованных в ZIP архив. Для подготовки пакетов с отчетами, разбора протоколов ошибок и оформления реестров к счетам для страховых компаний, я написал небольшую библиотеку и web приложение (сервер задач) для доступа к библиотеке по REST API.
Возможно, это будет интересно специалистам, или более широкой публике.


В этой статье мы изучим фундаментальные принципы проектирования, лежащие в основе создания обновляемых смарт-контрактов. К концу прочтения этой и следующей части статьи вы должны будете понять, почему мы обновляем смарт-контракты, как обновлять смарт-контракты и какие аспекты следует учитывать при этом.
Чтобы получить максимальную пользу от этой статьи, вы должны иметь начальные знания о смарт-контрактах на базе Ethereum и EVM. В этой серии статей приводится краткое описание кода, так что опыт программирования не менее трех месяцев будет полезен, как и базовое понимание Solidity и способов его компиляции, что такое смарт-контракты и как они развертываются, а также как использовать такие инструменты, как Metamask и Hardhat.

Стандарты токенов - это набор согласованных правил, которые определяют дизайн, разработку, поведение и работу криптовалютных токенов на определенном протоколе блокчейна. Для того чтобы стандарты токенов были полезны, они должны быть массово приняты. Без принятия эти правила не могут быть возведены в статус "стандарта", поскольку стандарты - это правила, которым обычно следует широкий круг людей.
В этой публикации мы рассмотрим, почему стандарты важны для повышения уровня принятия и использования криптовалютных токенов. Мы также рассмотрим, как разрабатываются стандарты Ethereum и кратко обсудим стандарты Solana.

Эта статья впервые появилась в журнале Computer и подготовлена InfoQ & IEEE Computer Society.
Теорема CAP гласит, что любая сетевая система с общими данными может иметь только два из трех желаемых свойств. Однако, работая непосредственно с разделениями, разработчики могут оптимизировать согласованность и доступность, тем самым достигая некоторого компромисса между всеми тремя.
За десятилетие, прошедшее с появления теоремы, разработчики и исследователи использовали теорему CAP (а иногда и злоупотребляли ею) как повод для изучения широкого спектра новых распределенных систем. Движение NoSQL также использовало её в качестве аргумента против традиционных баз данных.
В теореме CAP говорится, что любая сетевая система с общими данными может иметь не более двух из трех желаемых свойств:
Такое толкование CAP помогало разработчикам быть открытыми для более широкого диапазона систем и компромиссов; действительно, за последнее десятилетие возникло множество новых систем и много споров об относительных достоинствах согласованности и доступности. Формулировка «2 из 3» всегда вводила в заблуждение, поскольку имела тенденцию чрезмерно упрощать противоречия между свойствами. Но сейчас такие тонкости имеют значение. CAP запрещает лишь крошечную часть проектного пространства: идеальная доступность и согласованность при наличии разделений, которые встречаются редко.

Привет, Хабр! Меня зовут Сергей Корнеев, и я хочу рассказать о том, как мы организовали сбор данных в компании “Россети”. На момент запуска проекта я работал в “Россети.Цифра” и руководил внедрением BI-платформы. Нам с командой удалось решить проблему ручного сбора данных на базе Visiology Smart Forms, и именно об этом я расскажу сегодня.