Аннотация
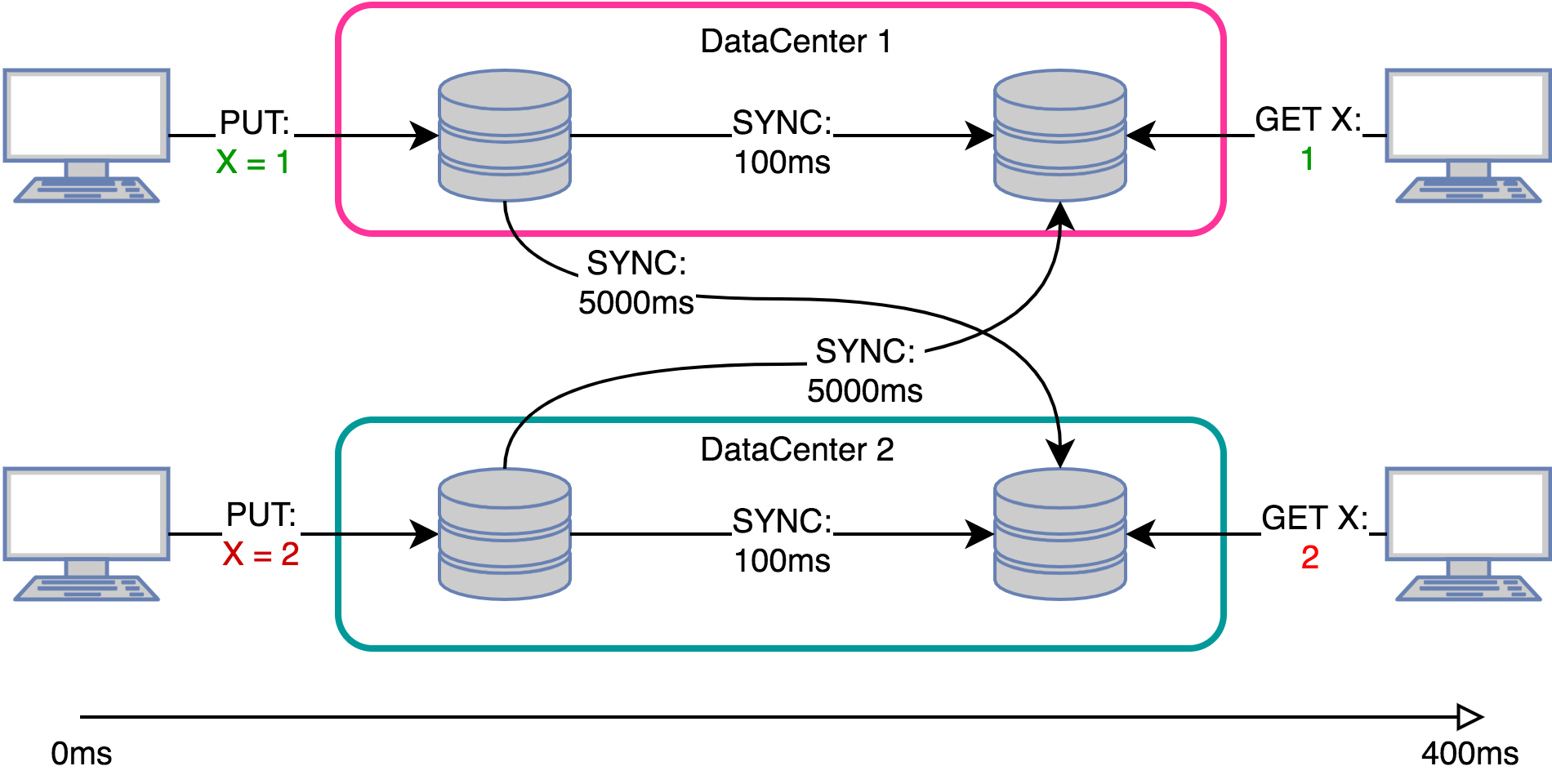
Обработка данных в реальном времени ровно один раз (exactly-once) — задача крайне нетривиальная и требующая серьезного и вдумчивого подхода на всей цепочке вычислений. Некоторые даже считают, что такая задача невыполнима. В реальности хочется иметь подход, обеспечивающий отказоустойчивую обработку вообще без каких-либо задержек и использование различных хранилищ данных, что выдвигает новые еще более жесткие требования, предъявляемые к системе: concurrent exactly-once и гетерогенность персистентного слоя. На сегодняшний день такое требование не поддерживает ни одна из существующих систем.
Предложенный подход последовательно раскроет секретные ингредиенты и необходимые понятия, позволяющие относительно просто реализовать гетерогенную обработку concurrent exactly-once буквально из двух компонент.
Введение
Разработчик распределенных систем проходит несколько стадий:
Стадия 1: Алгоритмы. Здесь происходит изучение основных алгоритмов, структур данных, подходов к программированию типа ООП и т.д. Код исключительно однопоточный. Начальная фаза вхождения в профессию. Тем не менее, достаточно непростая и может длиться годами.
Стадия 2: Многопоточность. Далее возникают вопросы извлечения максимальной эффективности из железа, возникает многопоточность, асинхронность, гонки, дебагинг, strace, бессонные ночи… Многие застревают на этом этапе и даже начинают с какого-то момента ловить ничем не объяснимый кайф. Но лишь единицы доходят до понимания архитектуры виртуальной памяти и моделей памяти, lock-free/wait-free алгоритмах, различных асинхронных моделях. И почти никто и никогда — верификации многопоточного кода.
Стадия 3: Распределенность. Тут такой треш творится, что ни в сказке сказать, ни пером описать.