
Какие мысли у вас возникают, когда вы слышите понятие «Видеоаналитика 2.0»?
Решение каких актуальных задач можно было бы поручить гипотетическим технологиям видеоанализа следующего поколения?
Среди популярных ответов наверняка встретятся «некооперативное распознавание личности человека среди идущей толпы с вероятностью, близкой к 100%», «выявление злоумышленников среди посетителей», “межкамерное одновременное сопровождение множества объектов без срыва трекинга”, “распознавание и классификация без ошибок всего, что видно в кадре”.
Инженер, связанный с инсталляциями систем безопасности пожелает максимальной автоматизации настройки детекторов за счет продвинутых алгоритмов самообучения, что позволит существенно снизить затраты на пуско-наладку и гарантийное обслуживание.
А
самый умный кто-то скажет, что видеоаналитика 2.0 возможна только при наличии искусственного интеллекта, что на текущем уровне развития технологий невозможно. Поэтому нам ничего не остается, кроме как наблюдать за лидерами рынка аналитики, которые и так выжимают максимально возможное из имеющихся вычислительных ресурсов и ждать массового внедрения квантовых компьютеров. Надеясь, что оно все же произойдет.


 На днях стало известно о том, что Digital Video, создатели проекта TOONZ, и японский издатель DWANGO подписали соглашение о приобретении компанией DWANGO проекта Toonz, программного обеспечения для создания 2D анимации.
На днях стало известно о том, что Digital Video, создатели проекта TOONZ, и японский издатель DWANGO подписали соглашение о приобретении компанией DWANGO проекта Toonz, программного обеспечения для создания 2D анимации.  В век «онлайна», печатная фотография стала больше походить на диковинку, как это было раньше с фотографией цифровой. В последнее время, различного рода фотобудки, стали набирать популярность, как интересный способ развлечь гостей и получить памятный сувенир в виде фотографии. Я фотограф, который увлекается программированием, и при этом сочетании, было бы странно не попробовать сделать себе фотобудку.
В век «онлайна», печатная фотография стала больше походить на диковинку, как это было раньше с фотографией цифровой. В последнее время, различного рода фотобудки, стали набирать популярность, как интересный способ развлечь гостей и получить памятный сувенир в виде фотографии. Я фотограф, который увлекается программированием, и при этом сочетании, было бы странно не попробовать сделать себе фотобудку. 


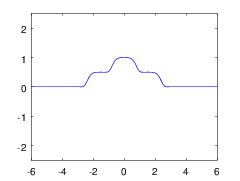 ===>
===> 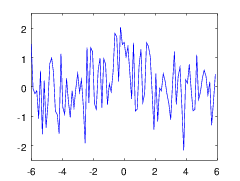 ===>
===> 
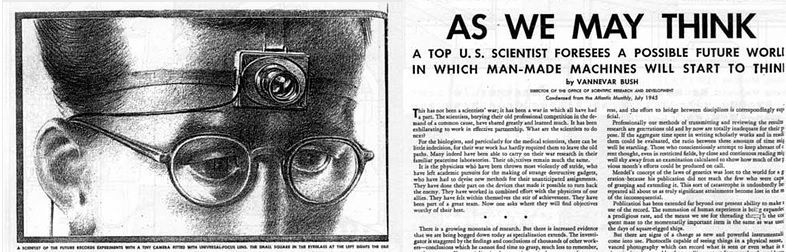
 В 1940 году Вэнивар Буш был назначен председателем Национального исследовательского комитета по вопросам обороны США, а с 1941 по 1947 год возглавлял организацию преемника комитета — Бюро научных исследований и развития, занимавшееся координацией усилий научного сообщества (6000 ведущих учёных страны) в целях военной обороны, разработкой ядерного оружия и Манхэттенским проектом.
В 1940 году Вэнивар Буш был назначен председателем Национального исследовательского комитета по вопросам обороны США, а с 1941 по 1947 год возглавлял организацию преемника комитета — Бюро научных исследований и развития, занимавшееся координацией усилий научного сообщества (6000 ведущих учёных страны) в целях военной обороны, разработкой ядерного оружия и Манхэттенским проектом.






