
Задача распознавания физической активности пользователей (Human activity Recognition или HAR) попадалась мне раньше только в качестве учебных заданий. Открыв для себя возможности Caret R Package, удобной обертки для более 100 алгоритмов машинного обучения, я решил попробовать его и для HAR. В UCI Machine Learning Repository есть несколько наборов данных для таких экспериментов. Так как тема с гантелями для меня не очень близка, я выбрал распознавание активности пользователей смартфонов.
Chatbot на нейронных сетях
5 мин
Недавно набрел на такую статью. Как оказалось некая компания с говорящим названием «наносемантика» объявила конкурс русских чатботов помпезно назвав это «Тестом Тьюринга»». Лично я отношусь к подобным начинаниям отрицательно — чатбот — программа для имитации разговора — создание, как правило, не умное, основанное на заготовленных шаблонах, и соревнования их науку не двигают, зато шоу и внимание публики обеспечено. Создается почва для разных спекуляций про разумные компьютеры и великие прорывы в искусственном интеллекте, что крайне далеко от истины. Особенно в данном случае, когда принимаются только боты написанные на движке сопоставления шаблонов, причем самой компании «Наносемантика».
Впрочем, ругать других всегда легко, а вот сделать что-то работающее бывает не так просто. Мне стало любопытно, можно ли сделать чатбот не ручным заполнением шаблонов ответа, а с помощью обучения нейронной сети на образцах диалогов. Быстрый поиск в Интернете полезной информации не дал, поэтому я решил быстро сделать пару экспериментов и посмотреть что получится.
Впрочем, ругать других всегда легко, а вот сделать что-то работающее бывает не так просто. Мне стало любопытно, можно ли сделать чатбот не ручным заполнением шаблонов ответа, а с помощью обучения нейронной сети на образцах диалогов. Быстрый поиск в Интернете полезной информации не дал, поэтому я решил быстро сделать пару экспериментов и посмотреть что получится.
Big Data Week Moscow 2015: презентации спикеров
2 мин

Хабр, на прошлой неделе New Professions Lab провел в Digital October фестиваль больших данных Big Data Week Moscow 2015. В этом посте мы cобрали презентации выступающих, enjoy!
Не очень большие данные и определение тональности текста
2 мин
Всякая идея имеет простое, понятное и неправильное решение.
Одно из таких решений я и опишу в этой статье.
Не пытайтесь повторить эти эксперименты дома.
А если попытаетесь — то претензии по сгоревшим процессорам не принимаются.
Одно из таких решений я и опишу в этой статье.
Не пытайтесь повторить эти эксперименты дома.
А если попытаетесь — то претензии по сгоревшим процессорам не принимаются.
Определяем веса шахматных фигур регрессионным анализом
15 мин
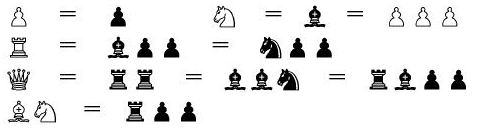 Здравствуй, Хабр!
Здравствуй, Хабр!В этой статье речь пойдёт о небольшом программистском этюде на тему машинного обучения. Замысел его возник у меня при прохождении известного здесь многим курса «Machine Learning», читаемого Andrew Ng на Курсере. После знакомства с методами, о которых рассказывалось на лекциях, захотелось применить их к какой-нибудь реальной задаче. Долго искать тему не пришлось — в качестве предметной области просто напрашивалась оптимизация собственного шахматного движка.
Вступление: о шахматных программах
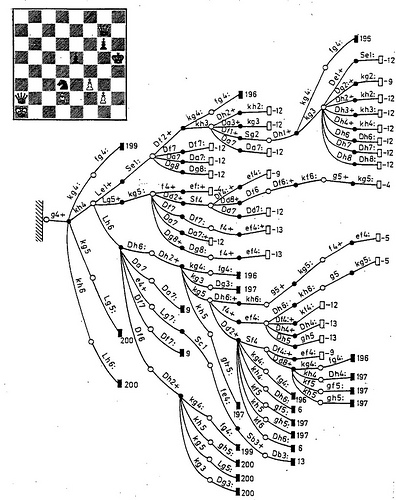
Не будем детально углубляться в архитектуру шахматных программ — это могло бы стать темой отдельной публикации или даже их серии. Рассмотрим только самые базовые принципы. Основными компонентами практически любого небелкового шахматиста являются поиск и оценка позиции.
Поиск представляет собой перебор вариантов, то есть итеративное углубление по дереву игры. Оценочная функция отображает набор позиционных признаков на числовую шкалу и служит целевой функцией для поиска наилучшего хода. Она применяется к листьям дерева, и постепенно «возвращается» к исходной позиции (корню) с помощью альфа-бета процедуры или её вариаций.
Строго говоря, настоящая оценка может принимать только три значения: выигрыш, проигрыш или ничья — 1, 0 или ½. По теореме Цермело для любой заданной позиции она определяется однозначно. На практике же из-за комбинаторного взрыва ни один компьютер не в состоянии просчитать варианты до листьев полного дерева игры (исчерпывающий анализ в эндшпильных базах данных — это отдельный случай; 32-фигурных таблиц в обозримом будущем не появится… и в необозримом, скорее всего, тоже). Поэтому программы работают в так называемой модели Шеннона — пользуются усечённым деревом игры и приближённой оценкой, основанной на различных эвристиках.
Классификация предложений с помощью нейронных сетей без предварительной обработки
6 мин
Довольно часто встречается задача классификации текстов — например, определение тональности (выражает ли текст позитивное мнение или отрицательное о чем-либо), или разнесения текста по тематикам. На Хабре уже есть хорошие статьи с введением в данный вопрос.
Сегодня я хочу поговорить о проблеме классификации отдельных предложений. Решение этой задачи позволяет делать много интересного, например, выделять положительные и отрицательные моменты из длинных текстов, определять тональность твитов, является компонентом многих систем отвечающих на естественно-языковые вопросы (классификация типа вопроса), помогает сегментировать веб-страницы на смысловые блоки и многое другое. Однако, классификация отдельных предложений значительно сложнее классификации больших блоков текста — в одном предложении значительно меньше полезных признаков, и велико влияние порядка слов. Например: «как положено фильму ужасов, этот фильм был ну очень жутким» — содержит негативные слова («ужас», «жуткий»), но выражает положительное мнение о фильме, «все было ужасно красиво», или даже «отличный фильм, ничего не скажешь, только зря деньги потратили».
Сегодня я хочу поговорить о проблеме классификации отдельных предложений. Решение этой задачи позволяет делать много интересного, например, выделять положительные и отрицательные моменты из длинных текстов, определять тональность твитов, является компонентом многих систем отвечающих на естественно-языковые вопросы (классификация типа вопроса), помогает сегментировать веб-страницы на смысловые блоки и многое другое. Однако, классификация отдельных предложений значительно сложнее классификации больших блоков текста — в одном предложении значительно меньше полезных признаков, и велико влияние порядка слов. Например: «как положено фильму ужасов, этот фильм был ну очень жутким» — содержит негативные слова («ужас», «жуткий»), но выражает положительное мнение о фильме, «все было ужасно красиво», или даже «отличный фильм, ничего не скажешь, только зря деньги потратили».
Python Meetup 27.03.15: machine learning, python AST и статистика игроков World of Tanks
1 мин
Туториал
Традиционно в последнюю пятницу месяца состоялся Python Meetup. В мартовском митапе с приглашенными спикерами мы разобрались в следующих темах:
Видео и ссылки на презентации смотрите под катом. Приятного просмотра!

- Машинное обучение на Python
- Как устроен Python AST и какие интересные факты есть у диалекта Ну
- Как при помощи Requests, Asyncio и Aiohttp перестать использовать многопоточный код
Видео и ссылки на презентации смотрите под катом. Приятного просмотра!
Машинное обучение — 4: Скользящее среднее
3 мин
Туториал
Принято считать, что две базовые операции «машинного обучения» — это регрессия и классификация. Регрессия — это не только инструмент для выявления параметров зависимости y(x) между рядами данных x и y (чему я уже посвятил несколько статей), но и частный случай техники их сглаживания. В этом примере мы пойдем чуть дальше и рассмотрим, как можно проводить сглаживание, когда вид зависимости y(x) заранее неизвестен, а также, как можно отфильтровать данные, которые контролируются разными эффектами с существенно разными временными характеристиками.
Один из самых популярных алгоритмов сглаживания, применяемый, в частности, в биржевой торговле — это скользящее усреднение (включаю его в цикл статей по машинному обучению с некоторой натяжкой). Рассмотрим скользящее усреднение на примере колебаний курса доллара на протяжении нескольких последних недель (опять-таки в качестве инструмента исследования используя Mathcad). Сами расчеты лежат здесь.
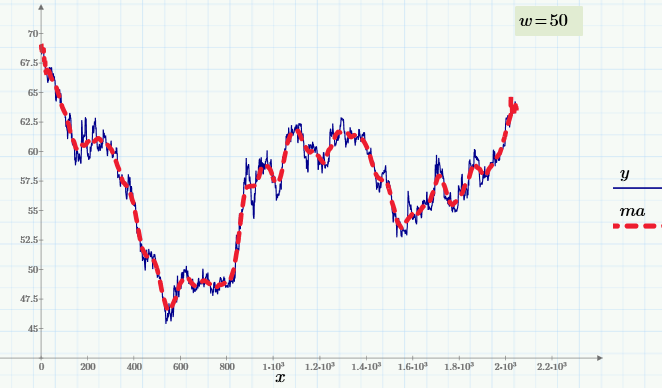
Один из самых популярных алгоритмов сглаживания, применяемый, в частности, в биржевой торговле — это скользящее усреднение (включаю его в цикл статей по машинному обучению с некоторой натяжкой). Рассмотрим скользящее усреднение на примере колебаний курса доллара на протяжении нескольких последних недель (опять-таки в качестве инструмента исследования используя Mathcad). Сами расчеты лежат здесь.
Как мы придумывали систему анализа текстов
5 мин
Доброго времени суток всем. Это наш первый пост в блог стартапа «Meanotek», и наверное он будет больше ознакомительного характера. Чтобы не было совсем скучно читать, мы попробуем рассказать историю, о том как одна практическая задача привела нас к созданию полноценной системы «понимания» текста компьютером, и что из этого получилось.
Мысль научить компьютер общаться на человеческом языке у меня появилась еще в школе, когда у меня дома был один из первых советских аналогов IBM PC, с языком программирования GW BASIC. Понятно, что далеко эта задумка в то время не ушла, потом ее заслонили другие более важные дела, но совершенно неожиданно она всплыла вновь спустя много лет, уже в связи с конкретной потребностью.
Собственно идея пришла в голову во время работы над другим проектом — сайтом поиска отзывов reviewdot.ru. Идея reviewdot.ru была в следующем — пользователь вводит запрос, например «зеркальный фотоаппарат для начинающих» — и получает список ссылок на отзывы в интернете, которые касаются именно этого вопроса. Или к примеру, чтобы по запросу «что ломается в стиральной машине Indesit?” появлялись ссылки на отзыв пользователей марки Indesit, у которых что-то сломалось. Вопрос ценности данного ресурса для людей пока оставим за скобками, и поговорим немного о технической стороне реализации.
Мысль научить компьютер общаться на человеческом языке у меня появилась еще в школе, когда у меня дома был один из первых советских аналогов IBM PC, с языком программирования GW BASIC. Понятно, что далеко эта задумка в то время не ушла, потом ее заслонили другие более важные дела, но совершенно неожиданно она всплыла вновь спустя много лет, уже в связи с конкретной потребностью.
Собственно идея пришла в голову во время работы над другим проектом — сайтом поиска отзывов reviewdot.ru. Идея reviewdot.ru была в следующем — пользователь вводит запрос, например «зеркальный фотоаппарат для начинающих» — и получает список ссылок на отзывы в интернете, которые касаются именно этого вопроса. Или к примеру, чтобы по запросу «что ломается в стиральной машине Indesit?” появлялись ссылки на отзыв пользователей марки Indesit, у которых что-то сломалось. Вопрос ценности данного ресурса для людей пока оставим за скобками, и поговорим немного о технической стороне реализации.
Конференция Microsoft Research — Cloud computing for Research with Microsoft Azure, 19 мая в МГУ
2 мин
Привет!
Май становится все горячее — у нас уже есть Microsoft DevCon 2015 в Яхонтах — главная конференция для разработчиков Microsoft в России, Embedded Day — конференция по встраиваемым технологиям и Интернету Вещейшкола по машинному обучению то Microsoft Research.
Однако мы подготовили еще один настоящий подарок — целую конференцию от Microsoft Research про то, как делать исследования в облаке. С каждым днем количество ресурсов, необходимых для научных вычислений, растёт, и локально справляться уже давно не получается. С приходом облака и прикладных инструментов, а также стараний Microsoft Research, нам есть что предложить научному сообществу. 19 мая, в Московском Государственном Университете, пройдет мини-конференция, где мы обсудим, как облако помогает в прикладных и теоретических изысканиях истины. С нами — ведущие эксперты, доктора наук из Microsoft Research.
В программе:
Май становится все горячее — у нас уже есть Microsoft DevCon 2015 в Яхонтах — главная конференция для разработчиков Microsoft в России, Embedded Day — конференция по встраиваемым технологиям и Интернету Вещейшкола по машинному обучению то Microsoft Research.
Однако мы подготовили еще один настоящий подарок — целую конференцию от Microsoft Research про то, как делать исследования в облаке. С каждым днем количество ресурсов, необходимых для научных вычислений, растёт, и локально справляться уже давно не получается. С приходом облака и прикладных инструментов, а также стараний Microsoft Research, нам есть что предложить научному сообществу. 19 мая, в Московском Государственном Университете, пройдет мини-конференция, где мы обсудим, как облако помогает в прикладных и теоретических изысканиях истины. С нами — ведущие эксперты, доктора наук из Microsoft Research.
В программе:
Big Data Week Moscow 2015: узнайте об индустрии больших данных изнутри
1 мин

Хабр, команда Лаборатории новых профессий приглашает тебя на Big Data Week Moscow — серию открытых встреч, посвященных технологиям больших данных, которые будут проходить с 20 по 24 апреля в центре Digital October.
Стивен Вольфрам: Рубежи вычислительного мышления (отчёт с фестиваля SXSW)
28 мин
Перевод

Перевод поста Стивена Вольфрама (Stephen Wolfram) "Frontiers of Computational Thinking: A SXSW Report".
Выражаю огромную благодарность Кириллу Гузенко за помощь в переводе.
На прошлой неделе я выступал на SXSW Interactive 2015 в Остине, штат Техас. Вот несколько отредактированная стенограмма моего выступления:
Содержание
Наиболее продуктивный год
Язык Wolfram Language
Язык для реального мира
Философия Wolfram Language
Программы размером в один твит
Вычислительное мышление для детей
Ввод запросов на естественном языке
Масштабная идея: Символьное программирование
Язык для развёртывания
Автоматизация программирования
Масштабные программы
Интернет вещей
Машинное обучение
Исследования Вычисляемой Вселенной
Вычислять, подобно тому, как это делает мозг
Язык как символьное представление
Пост-лингвистические понятия
Древняя история
Чем будет заниматься искусственный интеллект?
Бессмертие и за его пределами
Коробка триллиона душ
Обратно в 2015 год
Лекции Техносферы. 1 семестр. Алгоритмы интеллектуальной обработки больших объемов данных
3 мин
Туториал
Продолжаем публиковать материалы наших образовательных проектов. В этот раз предлагаем ознакомиться с лекциями Техносферы по курсу «Алгоритмы интеллектуальной обработки больших объемов данных». Цель курса — изучение студентами как классических, так и современных подходов к решению задач Data Mining, основанных на алгоритмах машинного обучения. Преподаватели курса: Николай Анохин (@anokhinn), Владимир Гулин (@vgulin) и Павел Нестеров (@mephistopheies).
Объемы данных, ежедневно генерируемые сервисами крупной интернет-компании, поистине огромны. Цель динамично развивающейся в последние годы дисциплины Data Mining состоит в разработке подходов, позволяющих эффективно обрабатывать такие данные для извлечения полезной для бизнеса информации. Эта информация может быть использована при создании рекомендательных и поисковых систем, оптимизации рекламных сервисов или при принятии ключевых бизнес-решений.
Объемы данных, ежедневно генерируемые сервисами крупной интернет-компании, поистине огромны. Цель динамично развивающейся в последние годы дисциплины Data Mining состоит в разработке подходов, позволяющих эффективно обрабатывать такие данные для извлечения полезной для бизнеса информации. Эта информация может быть использована при создании рекомендательных и поисковых систем, оптимизации рекламных сервисов или при принятии ключевых бизнес-решений.
Ближайшие события
Сравнение библиотек глубокого обучения на примере задачи классификации рукописных цифр
21 мин
Кручинин Дмитрий, Долотов Евгений, Кустикова Валентина, Дружков Павел, Корняков Кирилл
В настоящее время машинное обучение является активно развивающейся областью научных исследований. Это связано как с возможностью быстрее,выше, сильнее, проще и дешевле собирать и обрабатывать данные, так и с развитием методов выявления из этих данных законов, по которым протекают физические, биологические, экономические и другие процессы. В некоторых задачах, когда такой закон определить достаточно сложно, используют глубокое обучение.
Глубокое обучение (deep learning) рассматривает методы моделирования высокоуровневых абстракций в данных с помощью множества последовательных нелинейных трансформаций, которые, как правило, представляются в виде искусственных нейронных сетей. На сегодняшний день нейросети успешно используются для решения таких задач, как прогнозирование, распознавание образов, сжатие данных и ряда других.
Введение
В настоящее время машинное обучение является активно развивающейся областью научных исследований. Это связано как с возможностью быстрее,
Глубокое обучение (deep learning) рассматривает методы моделирования высокоуровневых абстракций в данных с помощью множества последовательных нелинейных трансформаций, которые, как правило, представляются в виде искусственных нейронных сетей. На сегодняшний день нейросети успешно используются для решения таких задач, как прогнозирование, распознавание образов, сжатие данных и ряда других.
Мешок слов и сентимент-анализ на R
5 мин
Эта статья подготовлена по мотивам (первой части) учебного задания Bag of Words Kaggle, но это не перевод. Оригинальное задание сделано на Python. Я же хотел оценить возможности языка R для обработки текстов на естественном языке и заодно попробовать реализацию Random Forest в обертке R-пакета caret.
Смысл задания – построить «машину», которая будет определенным образом обрабатывать обзоры фильмов на английском языке и определять тональность обзора, относя его к одному из двух классов: негативные/позитивные. В качестве обучающей выборки в задании используется набор данных с двадцатью пятью тысячами ревю из IMDB, размеченных неизвестными добровольцами.
Смысл задания – построить «машину», которая будет определенным образом обрабатывать обзоры фильмов на английском языке и определять тональность обзора, относя его к одному из двух классов: негативные/позитивные. В качестве обучающей выборки в задании используется набор данных с двадцатью пятью тысячами ревю из IMDB, размеченных неизвестными добровольцами.
Быстрая нейронная сеть для каждого
3 мин
Данная статья продемонстрирует возможность легко написать свою нейронную сеть на языке Javа. Дабы не изобретать велосипед, возьмем уже хорошо проработанную библиотеку Fast Artificial Neural Network. Использование нейронных сетей в своих Java-проектах — реально. Часто можно услышать упреки в адрес Java касательно скорости выполнения. Хотя разница не так велика — подробно об этом можно узнать в публикации «Производительность C++ vs. Java vs. PHP vs. Python. Тест «в лоб»». Мы будем использовать обертку вокруг библиотеки FANN.
Антифрод (часть 4): аналитическая система распознания мошеннических платежей
15 мин

В заключительной четвертой части статьи подробно обсудим наиболее сложную с технической точки зрения часть antifraud-сервиса – аналитическую систему распознания мошеннических платежей по банковским картам.
Выявление различного рода мошенничеств является типичным кейсом для задач обучения с учителем (supervised learning), поэтому аналитическая часть антифрод-сервиса, в соответствии с лучшими отраслевыми практиками, будет построена с использованием алгоритмов машинного обучения.
Для стоящей перед нами задачи воспользуемся Azure Machine Learning – облачным сервисом выполнения задач прогнозной аналитики (predictive analytics). Для понимания статьи будут необходимы базовые знания в области машинного обучения и знакомство с сервисом Azure Machine Learning.
Что уже было сделано? (для тех, кто не читал предыдущие 3 части, но интересуется)
В первой части статьи мы обсудили, почему вопрос мошеннических платежей (fraud) стоит так остро для всех участников рынка электронных платежей – от интернет-магазинов до банков – и в чем основные сложности, из-за которых стоимость разработки таких систем подчас является слишком высокой для многих участников ecommerce-рынка.
Во 2-ой части были описаны требования технического и нетехнического характера, которые предъявляются к таким системам, и то, как я собираюсь снизить стоимость разработки и владения antifraud-системы на порядок(и).
В 3-ей части была рассмотрена программная архитектура сервиса, его модульная структура и ключевые детали реализации.
В заключительной четвертой части у нас следующая цель…
Во 2-ой части были описаны требования технического и нетехнического характера, которые предъявляются к таким системам, и то, как я собираюсь снизить стоимость разработки и владения antifraud-системы на порядок(и).
В 3-ей части была рассмотрена программная архитектура сервиса, его модульная структура и ключевые детали реализации.
В заключительной четвертой части у нас следующая цель…
Цель
В этой части я опишу проект, на первом шаге которого мы обучим четыре модели, используя логистическую регрессию, персептрон, метод опорных векторов и дерево решений. Из обученных моделей выберем ту, которая дает большую точность на тестовой выборке и опубликуем ее в виде REST/JSON-сервиса. Далее для полученного сервиса напишем программного клиента и проведем нагрузочное тестирование на REST-сервис.
Машинное обучение в навигационных устройствах: определяем маневры машины по акселерометру и гироскопу
10 мин
Программы, которые доступны нам сегодня для автомобильной навигации оказывают большую помощь водителям. Они помогают нам ориентироваться в незнакомой местности и объезжать пробки. Это большой труд людей со всего мира, который сделал нашу жизнь проще. Но нельзя останавливаться на достигнутом, технологии идут вперед и качество программ также должно расти.

Сегодня, на мой взгляд, одна из проблем навигационных устройств – это то, что они не ведут пользователя по полосам. Эта проблема увеличивает время в пути, пробки и аварийность. Недавно google maps начали отображать разметку дороги перед поворотом, что уже хороший результат, но и тут можно многое улучшить. Карты не знают на какой полосе сейчас находится машина, средствами gps узнать это проблематично, у gps слишком большая погрешность для этого. Если бы мы знали текущую полосу, то знали бы скорость движения по полосами и могли бы задолго подсказывать пользователю в явном виде, на какую полосу и когда ему лучше перестроиться. Например, навигатор говорил бы “Продолжайте держаться этой полосы до перекрестка” или “Перестройтесь на крайнюю левую полосу”.
В этой статье мы попробуем рассказать, как мы пытаемся определять перестроения, текущую полосу движения автомобиля, повороты, обгоны, а также другие маневры с помощью машинного обучения по данным акселерометра и гироскопа.
Сегодня, на мой взгляд, одна из проблем навигационных устройств – это то, что они не ведут пользователя по полосам. Эта проблема увеличивает время в пути, пробки и аварийность. Недавно google maps начали отображать разметку дороги перед поворотом, что уже хороший результат, но и тут можно многое улучшить. Карты не знают на какой полосе сейчас находится машина, средствами gps узнать это проблематично, у gps слишком большая погрешность для этого. Если бы мы знали текущую полосу, то знали бы скорость движения по полосами и могли бы задолго подсказывать пользователю в явном виде, на какую полосу и когда ему лучше перестроиться. Например, навигатор говорил бы “Продолжайте держаться этой полосы до перекрестка” или “Перестройтесь на крайнюю левую полосу”.
В этой статье мы попробуем рассказать, как мы пытаемся определять перестроения, текущую полосу движения автомобиля, повороты, обгоны, а также другие маневры с помощью машинного обучения по данным акселерометра и гироскопа.
Azure Machine Learning для Data Scientist
8 мин
Эта статья создана нашим другом из коммьюнити, Дмитрием Петуховым, Microsoft Certified Professional, разработчиком компании Quantum Art.
Статья — часть цикла про Fraud Detection, остальные статьи можно найти в профиле у Дмитрия.
Azure Machine Learning – облачный сервис для выполнения задач прогнозной аналитики (predictive analytics). Сервис представлен двумя компонентами: Azure ML Studio – средой разработки, доступной через web-интерфейс, и web-сервисами Azure ML.
Типичная последовательность действий data scientist'a при поиске закономерностей в наборе данных с использованием алгоритмов обучения с учителем изображена и подробно описана под хабракатом.
Softbank собирается подключить говорящего робота Pepper к IBM Watson
2 мин

Компания Softbank, крупнейший оператор мобильной связи Японии, в прошлом году представил говорящего робота Pepper. По замыслу, робот должен быть спутником и помощником человека, а для того, чтобы сделать робота «умнее», систему планируют подключить к облачному сервису IBM Watson.
К сожалению, пока что партнеры не объясняют, чего именно собираются добиться путем такого подключения — возможно, робот будет работать в качестве консультанта в салонах Softbank, или же его будут использовать в других целях. Стоит отметить, что компания Softbank собирается использовать возможности IBM Watson не только для того, чтобы сделать своего робота более умным, но и для повышения эффективности работы самой компании.