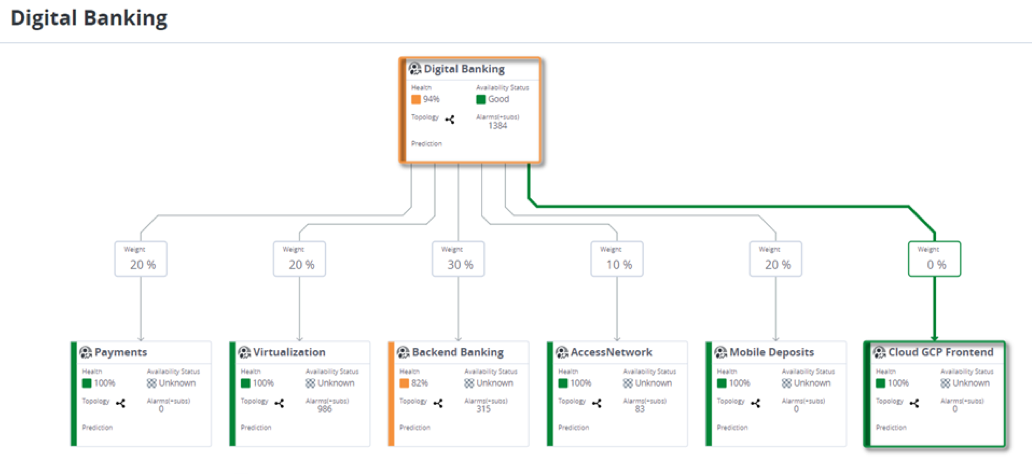
Как все знают, монорепозиторий - это несколько частей проекта (приложения, сервисы, библиотеки и т.д.), которые хранятся в одном репозитории. Плохо это или хорошо - не тема данной публикации. Но все же упомяну некоторые причины по которым я решил их использовать.
В скриптах деплоймента (или в моем случае еще и в настройках GitLab репозитория), нужно сформировать токены/ключи доступов к докер реджистри, кубернетесу, разным кластерам и т.д. И если у вас пару сервисов, то это не проблема, но если сервисов 15-20, то это весьма болезненный процесс. Особенно, когда настройки кластера меняются и нужно эти изменения вносить во все репозитории.
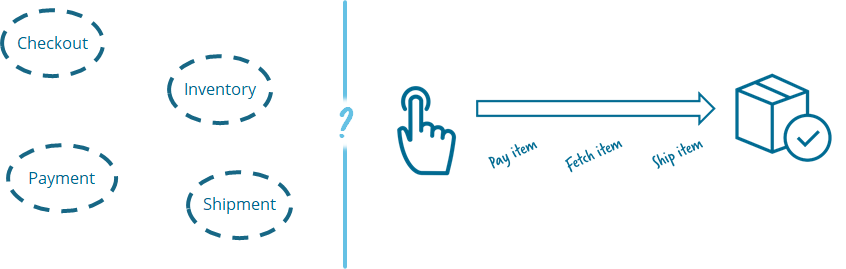
В определенных случаях среди нескольких сервисов, можно выделить общий код, который можно переиспользовать (описание интерфейсов, утилиты и т.д.) и особенно важно на самом старте проекта, когда эти общие куски кода только формируются не тратить время на коммиты в отдельные репозитории, если нужно всего лишь добавить поле в общий интерфейс.
После того как мы перешли на монорепозиторий появилось еще несколько преимуществ, без которых, в принципе, тоже можно жить, но все равно это был приятный бонус.
И вот мы решили использовать монорепозиторий, но с чего начать и как все организовать?