Мой друг Роберт Ходжес на днях опубликовал
статью про репликацию из OLTP в OLAP базу данных (а именно, из MySQL в Vertica), которую его компания построила на своем продукте Tungsten. Самое интересное, это преобразование данных, которое происходит в процессе репликации. Подход достаточно общий, и может быть использован и для других систем.
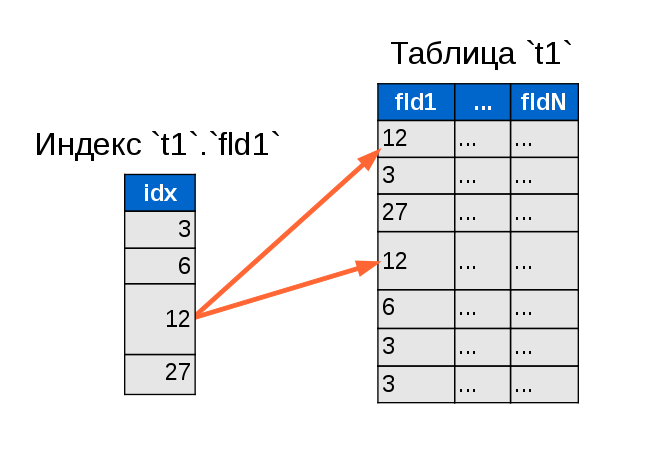
Обычный подход к репликации — это синхронный или асинхронный перенос бинарного лога с одной базы данных (мастер) на другие (слейвы). В бинарном логе строго последовательно записываются все операции, которые модифицируют данные. Если его «проиграть» на другой системе с той же начальной точки, то должно получиться точно такое же состояние данных, как и на исходной. «Проигрывание» происходит по одной операции или по одной транзакции, то есть очень маленькими кусочками.
Этот подход плохо работает с OLAP-специфичными, и особенно, колонко-ориентированными базами данных, которые хранят данные физически не по строкам, а по колонкам. Такие базы данных оптимизированы на запись, чтение и сортировку больших массивов данных, что типично для аналитических задач, но не на маленькие операции на единичных записях, потому что любая операция затрагивает много колонок, которые физически хранятся в разных файлах (а иногда и разных дисках). Хуже всего обстоит дело с изменением данных. Конечно, все базы данных поддерживают стандарт SQL и оператор UPDATE, но на физическом уровне он, как правило, транслируется в то, что обновляемая запись помечается как удаленная, а вместо нее вставляется измененная копия. Потом, когда-нибудь, «сборщик мусора» перетрясет таблицу и удаленные записи удалятся навсегда. Помимо плохой эффективности, отсюда следует, что частые удаления и обновления приводят к «засорению» базы данных, что снижает ее производительность в том числе и на чтение.
Роберт предложил, как мне кажется, новый, хотя и естественный подход к решению проблемы репликации данных для таких случаев. Бинарный лог преобразуется в последовательность частично упорядоченных множеств операций типа DELETE/INSERT для каждой таблицы, причем, так слово «множество» подразумевает, что «одинаковые» в некотором смысле операции достаточно сделать один раз. Поясню чуть подробнее.

 Почти в каждом более менее динамическом проекте бывает возникает необходимость выполнять очереди задач в фоне (отправка email, обновления кеша, реиндексация поиска и т.д.). Job сервера (Gearman и т.п.) хороши, но для большинства простых задач они избыточны. Классическая реализация очередей в MySQL (при помощи SELECT … LOCK FOR UPDATE) при росте нагрузки со временем начинает приводить к проблемам с блокировкой. Потому, как это обычно бывает, пришлось написать свой «велосипед» для работы с фоновыми задачами, который бы «точно работал» и был предельно прост.
Почти в каждом более менее динамическом проекте бывает возникает необходимость выполнять очереди задач в фоне (отправка email, обновления кеша, реиндексация поиска и т.д.). Job сервера (Gearman и т.п.) хороши, но для большинства простых задач они избыточны. Классическая реализация очередей в MySQL (при помощи SELECT … LOCK FOR UPDATE) при росте нагрузки со временем начинает приводить к проблемам с блокировкой. Потому, как это обычно бывает, пришлось написать свой «велосипед» для работы с фоновыми задачами, который бы «точно работал» и был предельно прост.

 Конечно, в одной статье (и даже не в одной) невозможно описать универсальный «рецепт», который бы подошел абсолютно для всех проектов: для кого-то важнее производительность (иногда — даже в ущерб надежности), для кого-то — наоборот, отказоустойчивость превыше всего, где-то много маленьких таблиц, где-то — большой объем данных…
Конечно, в одной статье (и даже не в одной) невозможно описать универсальный «рецепт», который бы подошел абсолютно для всех проектов: для кого-то важнее производительность (иногда — даже в ущерб надежности), для кого-то — наоборот, отказоустойчивость превыше всего, где-то много маленьких таблиц, где-то — большой объем данных…
 Наверное всем известно, что Django является одним из самых популярных фреймворков для web-разработки на python-е. И даже если в основе web-проекта лежит сторонний код, то зачастую при разработке используют отдельные части этого фреймворка — например ORM. В данной статье я хотел бы рассказать об особенностях использования Django ORM при работе с базой данных MySQL, а именно про транзакции и подводные камни, связанные с ними. Так, например, если в какой-то момент вы осознаёте, что вместо ожидаемых данных, возвращается совершенно другой результат, то возможно, данная статья поможет разобраться что к чему.
Наверное всем известно, что Django является одним из самых популярных фреймворков для web-разработки на python-е. И даже если в основе web-проекта лежит сторонний код, то зачастую при разработке используют отдельные части этого фреймворка — например ORM. В данной статье я хотел бы рассказать об особенностях использования Django ORM при работе с базой данных MySQL, а именно про транзакции и подводные камни, связанные с ними. Так, например, если в какой-то момент вы осознаёте, что вместо ожидаемых данных, возвращается совершенно другой результат, то возможно, данная статья поможет разобраться что к чему.