
Резервное копирование данных в MySQL
5 мин
Резервное копирование базы данных — это такая штука, которую вечно приходится настраивать для уже работающих проектов прямо на «живых» production-серверах.
Подобная ситуация легко объяснима. В самом начале любой проект еще пуст и там просто нечего копировать. В фазе бурного развития головы немногочисленных разработчиков заняты исключительно прикручиванием фишек и рюшек, а также фиксом критических багов с дедлайном «позавчера». И только когда проект «взлетит», приходит осознание, что главная ценность системы — это накопленная база данных, и её сбой станет катастрофой.
Эта обзорная статья — для тех, чьи проекты уже достигли этой точки, но жареный петух ещё не клюнул.
Подобная ситуация легко объяснима. В самом начале любой проект еще пуст и там просто нечего копировать. В фазе бурного развития головы немногочисленных разработчиков заняты исключительно прикручиванием фишек и рюшек, а также фиксом критических багов с дедлайном «позавчера». И только когда проект «взлетит», приходит осознание, что главная ценность системы — это накопленная база данных, и её сбой станет катастрофой.
Эта обзорная статья — для тех, чьи проекты уже достигли этой точки, но жареный петух ещё не клюнул.

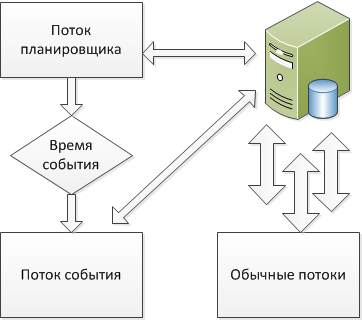 Для тех, кто активно пользуется MySQL, не секрет, что начиная с версии 5.1, MySQL поддерживает события (events). Если вам нужно выполнять запросы или отдельные процедуры по расписанию, а перейти с запуска консоли на встроенный функционал MySQL
Для тех, кто активно пользуется MySQL, не секрет, что начиная с версии 5.1, MySQL поддерживает события (events). Если вам нужно выполнять запросы или отдельные процедуры по расписанию, а перейти с запуска консоли на встроенный функционал MySQL 