
Natural Language Processing *
Компьютерный анализ и синтез естественных языков

ИИ уже пишет тексты не хуже профессионалов

Неделю назад OpenAI отменила список ожидания для доступа к нейросети GPT-3. Теперь разработчики из 152 стран, где поддерживается сервис, могут зарегистрироваться и свободно пользоваться инструментами.
Это очень сильный шаг вперед. Шесть лет назад у нас были только примитивные языковые генераторы, которые могли писать базовые отчеты о прибылях и убытках. Потом появилась нейросеть GPT-2, которая была как минимум в 10 раз мощнее и была способна обрабатывать 1,5 миллиарда параметров (переменных, определяющих возможности машинного обучения). Теперь — у нас в свободном доступе есть GPT-3, который может обрабатывать 175 миллиардов.
ИИ может в ответ на запросы генерировать почти неотличимый от человеческого текст. А также анализировать и резюмировать любые источники неструктурированных данных, если они написаны письменным языком.
Это значит, например, что и-мейлы или эссе скоро могут писаться по одному нажатию на кнопку. Людям не обязательно быть грамотными или даже знать стилистику текста, которую от них ожидают. Достаточно задать то, что ты хочешь, и у тебя будет готовый материал под любые потребности. Как Google, только для текстов, которые еще не написаны.
Кластерный анализ корпуса текстов

Иногда возникает необходимость провести анализ большого количества текстовых данных, не имея представления о содержании текстов. В таком случае можно попытаться разбить тексты на кластеры, и cгенерировать описание для каждого кластера. Таким образом можно в первом приближении сделать выводы о содержании корпуса текстов.
Проблема омографов в задачах G2P и автоматической простановки ударений

Задачи автоматического перевода слов в фонемы, автоматической простановки ударения, и автоматической простановки буквы ё сейчас решаются довольно успешно даже на уровне открытых решений (например: 1, 2, 3).
Тем не менее, практически ни одно открытое решение не позволяет разрешать неопределённости, возникающие при обработке слов-омографов. И оказывается, что эта на первый взгляд незначительная деталь очень сильно влияет на восприятие результатов алгоритмов (будь то G2P или автоматические ударения). В статье предлагаются некоторые способы решения проблемы омографов, а также указывается основная причина того, что эта задача до сих пор не решена публично.
Генеративные диалоговые модели: как мы разговорили виртуальных ассистентов Салют
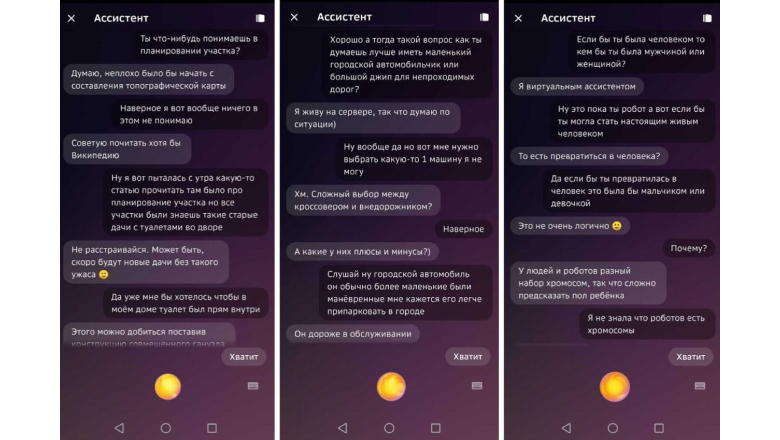
Порой люди обращаются к искусственному интеллекту не для того, чтобы заказать еду, найти подходящий фильм или решить какую-то ещё свою задачу, а для того, чтобы просто поболтать. Например, потому что грустно, а рядом нет тех, с кем было бы удобно про это поговорить. И пусть виртуальные помощники пока не заменяют настоящих друзей или близких людей (они и не должны), но всё же они могут поднять настроение, помочь снизить уровень напряжения. Чтобы такое общение было живым и действительно интересным, мы разработали и применяем мощные разговорные модели на русском языке для виртуальных ассистентов Салют в режиме «Собеседник». Так, за Сбера с пользователем общается SBERT (retrieval-модель), за Джой — ruGPT-3 (генеративная модель), а за Афину — обе сразу. Поговорим сегодня о генеративной части.
Передаю слово моему коллеге, руководителю RnD NLP SberDevices Валерию Терновскому.
Асимметричный анализ тональности деловых новостей

В этой статье мы рассмотрим подход к асимметричному анализу тональности деловых новостей. Главная особенность задачи заключается в том, что нам хотелось бы понять не просто тональную окраску всей новости, а тональность относительно конкретной сущности-организации в тексте. То есть в одном и том же тексте мы ожидаем получать разный сантимент для разных компаний.
Обнаружение фишинговых сообщений с сохранением конфиденциальности с помощью нейронных сетей

Фишинговые сообщения, которые кажутся очень похожими на настоящие, например, рассылку от вашего любимого интернет-магазина, но при этом они заманивают нажимать на прикрепленные вредоносные ссылки или документы.
Разбираемся, как нейронные сети помогают защититься от таких атак!
Мир против интентов

Я давно собирался и наконец-то решился высказать и доказать одну крамольную мысль. Датасайентисты из области NLU и NLP могут заранее готовит кирпичи, чтобы швырнуть ими в меня. Будет много жареного!
Начнём с главного - мир ошибается. Де факто! Диалоговые технологии развиваются не в том направлении и не теми темпами. Сайентисты научили алгоритмы превращать звук голоса в текст, а текст обратно в слышимую речь. Но между этими двумя частями находится задача понимания СМЫСЛА сказанного - того, что было заложено в произнесённый текст. “Рот” и “уши” сделать сумели, а к “голове” их прикрепить не получается. Вернее, то что подают за решение, решением не является. То что выдают за современные технологии IT-гиганты такой “детский сад”, что мама дорогая! Как это не стыдно выкладывать в мир таким компаниям как Гугл, Майкрософт и Яндекс. Примитивизм и убогость голосовых навыков просто удручает.
Диалоговые помощники для работы со структурированными данными
- Кто в нашей компании отвечает за согласование доступа в выходные на объект N?
- Александр Иванов.
- А какой у него телефон?
С таким диалогом легко справится любой офисный клерк, но для чат-ботов и диалоговых помощников подобные сценарии беседы до сих пор являются проблемой.
В статье мы рассказываем о том, как решили задачу преобразования вопросов пользователей на естественном языке в запросы к корпоративному графу знаний.
Извлекаем суть новости. Опыт Яндекса
Как и всё в Новостях, построение такой выжимки должно быть полностью автоматическим. До внедрения выжимки текстовая часть сюжета выглядела так:

Теперь она выглядит так:

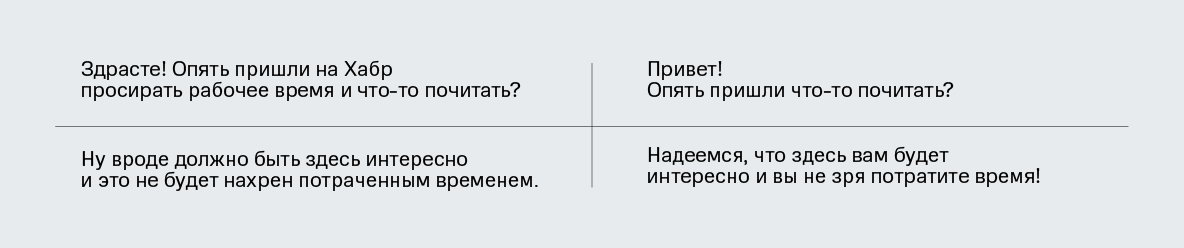
Методы детоксификации текстов для русского языка
ВНИМАНИЕ! В статье есть примеры текстов, содержащие мат и грубые выражения. Мы ни в коем случае не хотим оскорбить наших читателей, все подобные тексты приведены лишь в научных целях в качестве примеров токсичности в реальных текстах из Интернета.
Всем привет! Меня зовут Дарина Дементьева, я являюсь аспиранткой в Сколковской лаборатории обработки естественного языка (Skoltech NLP), где занимаюсь исследовательскими проектами совместной лаборатории Skoltech NLP и MTS AI. В рамках работы в совместной лаборатории мы провели серию исследований, посвященных важной социальной проблеме – борьбе с токсичной речью в Интернете или детоксификации текстов.
В этой статье мы расскажем про результаты исследований методов детоксификаций для русского языка. Эта работа была опубликована и презентована на конференции Диалог, а также принята в журнал MDPI. Результаты экспериментов на английском языке приняли для презентации на одной из ведущих конференций в области обработки естественного языка EMNLP. Мы представляем вам краткую выжимку с описанием моделей, постановкой и результатами экспериментов, а в конце вы сможете самостоятельно ̶п̶о̶м̶а̶т̶е̶р̶и̶т̶ь̶с̶я̶ ̶в̶ ̶ч̶а̶т̶е̶ протестировать модели в бою. Теперь – добро пожаловать под кат!
Синтезируем голос бабушки, дедушки и Ленина + новости нашего публичного синтеза

На Хабре часто висят в топе: политика и очередные запреты, трактор, ну и конечно сенсационные новости про "очередные достижения AI". Также журналисты маркетологи любят перепечатывать нормальные статьи наподобие этой но под максимально кричащими заголовками в духе "AI поработит мир, ваш голос уже украли".
Не секрет, что имея бюджет на вычисления в единицы или десятки миллионов долларов, напоказ достичь можно многого. Но реальность как правило оказывается более сложной и прозаической.
Вопреки этому тренду, в этой статье мы постараемся на пальцах и близко к народу:
- На реальных примерах показать возможности генерации голоса на малом числе данных или на данных с неидеальным качеством;
- Немного порассуждать на тему цифровых памятников (это чем-то похоже на интерактивные или трехмерные фотографии), сделанных из голоса человека;
- Также немного порассуждать на тему того, какую объективную опасность это представляет для общества;
И также мы конечно поделимся новостями нашего публичного синтеза речи.
Ближайшие события
Обзор методов улучшения речи и шумоподавления: от классики к SotA

Всем привет! Меня зовут Оля Яковенко, я разработчик в MTS AI, занимаюсь задачами по автоматической обработке сигналов. В частности, на данный момент я исследую различные подходы шумоподавления для последующего распознавания речи, и сегодня я хотела бы поделиться с вами обзором и некоторыми находками на эту тему.
Улучшаем генеративных чатботов на нейросети ruGPT3: умный ранжировщик ответов

Нейронные сети все прочнее входят в нашу жизнь. В последнее время особую значимость приобретают исследования, связанные с обучением искусственных нейронных сетей в сфере анализа естественного языка (NLP, NLU) для создания реалистичных, человечных разговорных «скиллов». Одним из первых примеров «человечных» диалоговых решений стала Xiaoice от Microsoft, которая обладала навыками дружелюбности. Позже такие компании как Яндекс, Google [1], Mail.ru и другие выпустили на рынок своих голосовых помощников. Однако все они столкнулись с фундаментальной проблемой: их решения хорошо выполняют запросы пользователей, связанные с четкими командами («расскажи новости»), но совершенно не обладают человечными способностями, качествами характера, эмуляцией чувств, эмпатией и поэтому не способны поддерживать человеческий разговор на различные темы. При этом «видимость человечности» часто обеспечивается набором шаблонных фраз и шуток, подходящих практически в любой ситуации (неспецифичных контексту разговора).
В этой статье мы покажем, как устроен и как работает разработанный нами умный Ранжировщик ответов для нейросеток Трансформер и какой эффект он оказывает на качество разговора любых генеративных чатботов.
Формы глаголов в английском языке
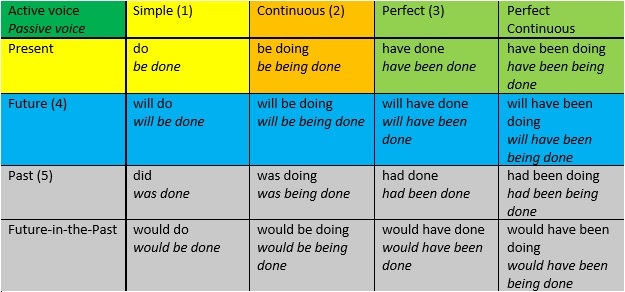
Многие при изучении английского языка сталкивались с необходимостью заучивания форм вспомогательных глаголов в каждом из времен английского языка. Однако, эти вспомогательные глаголы формируются по довольно простому алгоритму, о котором я и расскажу в этой заметке.
Каждое из 16 времен (каждое время – в двух вариантах: действительный и страдательный залог) может быть охарактеризовано наличием или отсутствием каждого из следующих 5 признаков.
Частотный биграммный анализ на Python

Понадобилось мне для одного проекта, о котором хотелось бы отдельно написать через недельку, узнать частотность (как базовую, так и парную) буквенных символов в русском и английском языках.
Побродив по бескрайним просторам интернета, я с удивлением обнаружил, что исследований на такую базово простую, и в то же время локально востребованную тему преступно мало. Их буквально можно пересчитать по пальцам.
Для английского языка было найдено 12 более или менее достоверных анализов для базовой символьной частотности, из которых только 3 обладают внушительными базовыми выборками, и 5 биграммных анализов (парная частотность), из которых внушительной выборкой могут похвастать лишь 2.
Для русского и того меньше – 7 анализов базовой частотности, из которых 3 без указанного значения выборки, остальные же в пределах х×106 символов. Биграммных – 3, один из которых сделан по единственной книге «Преступление и наказание», а второй на 5.000 символов.
Несложно догадаться, как обстоит дело с менее популярными языками.
Создайте средство проверки на плагиат с помощью машинного обучения
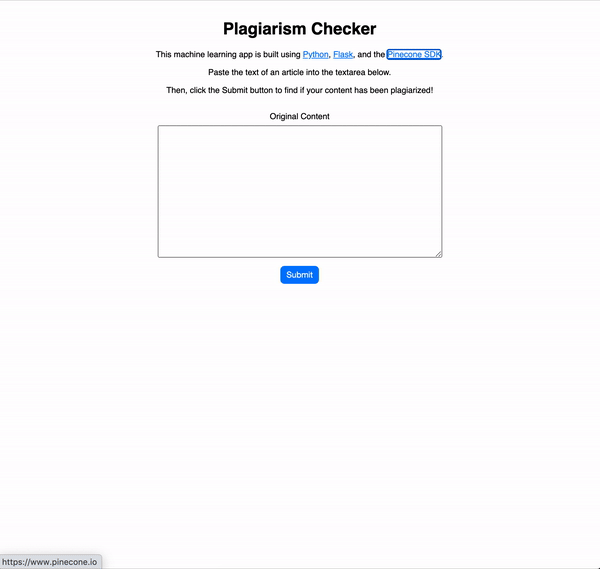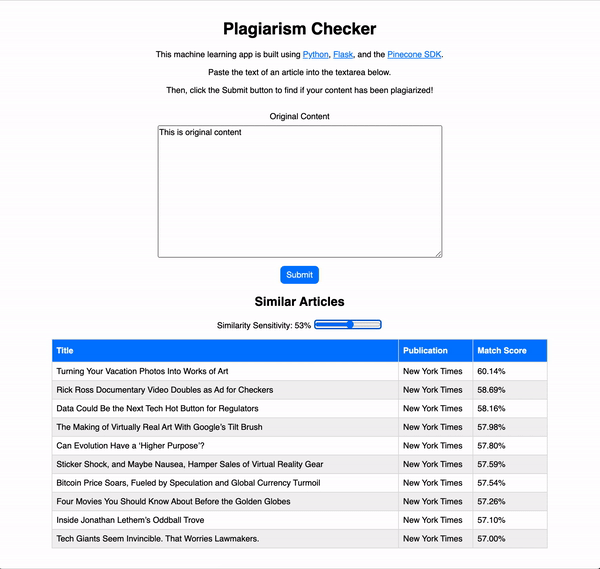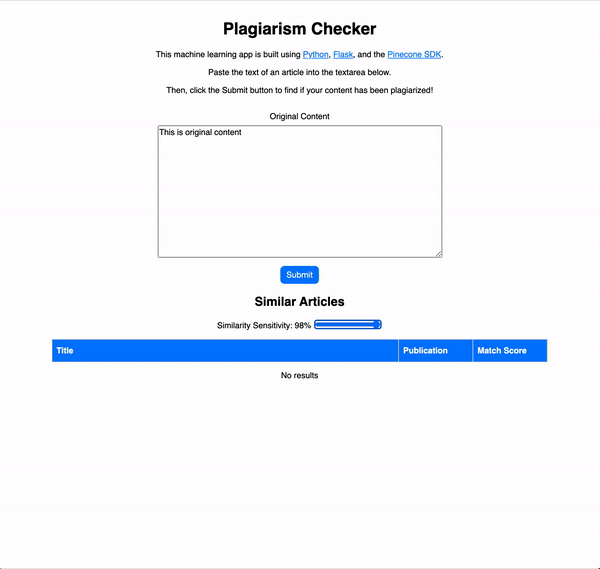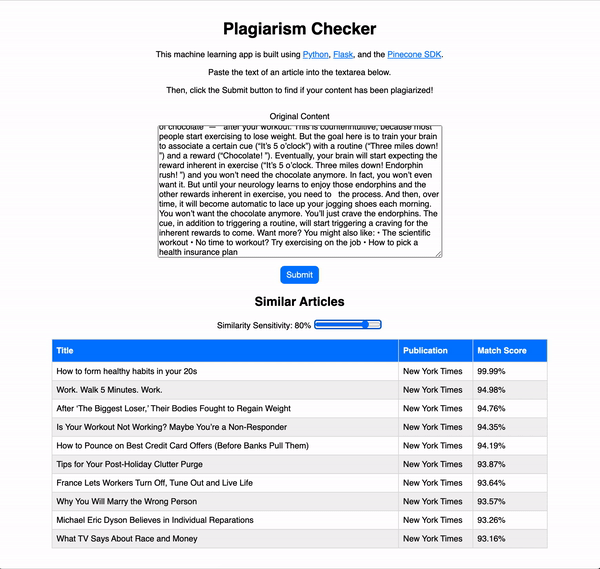
Используя машинное обучение, мы можем создать нашу собственную программу проверки на плагиат, которая выполняет поиск украденного контента в огромной базе данных. В этой статье мы сделаем демонстрационное приложение для этой цели.
Плагиат широко распространен в Интернете и в процессе обучения. При большом количестве контента иногда трудно определить, когда что-то стало плагиатом.
Авторы, пишущие сообщения в блогах, могут захотеть проверить, не украл ли кто-то их работу и не разместил ли ее в другом месте. Учителя могут захотеть сравнить работы студентов с другими научными статьями на предмет скопированных работ. Новостные агентства могут захотеть проверить, не украла ли контент ферма их новостные статьи и не презентовала ли на это содержание как на свое.
Итак, как нам защититься от плагиата? Разве не было бы хорошо, если бы у нас было программное обеспечение, которое делало бы за нас всю тяжелую работу?
Используя машинное обучение, мы можем создать нашу собственную программу проверки на плагиат, которая выполняет поиск украденного контента в огромной базе данных. В этой статье мы сделаем именно это.
Мы создадим Python Flask приложение, которое использует Pinecone - службу поиска сходства для поиска возможного плагиата.
Нейросети для Natural Language Inference (NLI): логические умозаключения на русском языке
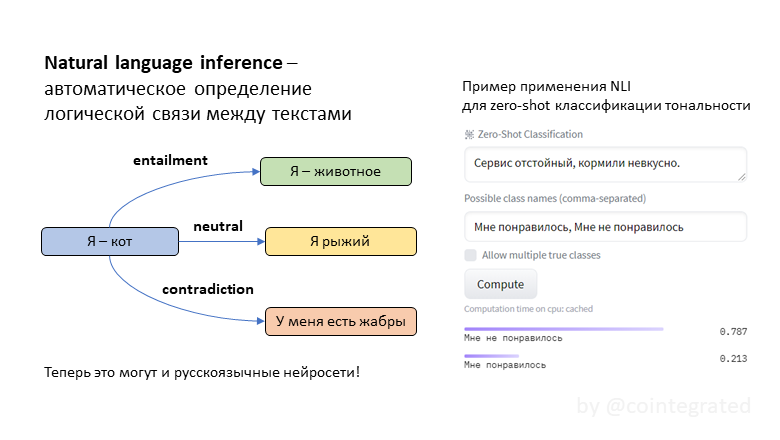
NLI (natural language inference) – это задача автоматического определения логической связи между текстами. Обычно она формулируется так: для двух утверждений A и B надо выяснить, следует ли B из A. Эта задача сложная, потому что она требует хорошо понимать смысл текстов. Эта задача полезная, потому что "понимательную" способность модели можно эксплуатировать для прикладных задач типа классификации текстов. Иногда такая классификация неплохо работает даже без обучающей выборки!
До сих пор в открытом доступе не было нейросетей, специализированных на задаче NLI для русского языка, но теперь я обучил целых три: tiny, twoway и threeway. Зачем эти модели нужны, как они обучались, и в чём между ними разница – под катом.
Способы упрощения текстов: плюсы, минусы, альтернативы
Сложно понять содержимое текста, если в нем встречается много незнакомых слов. Вариант решения этой проблемы – замена слов на близкие к ним по значению. Заменить слово на синоним можно, например, тремя способами – трансформером, word2vec и его модификацией - RusVectores.
Зачем вообще упрощать текст? Есть, как минимум, три кейса, почему есть вероятность столкнуться с этой задачей:
- если перед вами текст на иностранном языке, то замена «сложного» слова на синоним поможет сориентироваться в сути предложения
- если вы работаете с доменной тематикой, то также подбор синонимов может сделать текст проще для восприятия (так, например, «ирригация» можно заменить на «орошение» и наоборот, в таком случае шанс понять текст у читающего увеличивается)
- для расширения датастета: аугментация текстовых данных – это всегда вызов, важно учитывать контекст для того, чтобы подобрать синоним. Тут, конечно, важно учитывать размер корпуса, частота встречаемости слов в рамках контекста будет точнее, если корпус состоит из миллионов предложений, а не из тысяч.
Если говорить более предметно, то это задача делится на две: поиск сложного слова или словосочетания и поиска его замены, исходя из контекста. Давайте последовательно разберемся с каждой из задач.
Если кому-то интересно ознакомиться только с кодом, то welcome на github, там можно найти пошаговую реализацию.
Задача выделения сложных слов