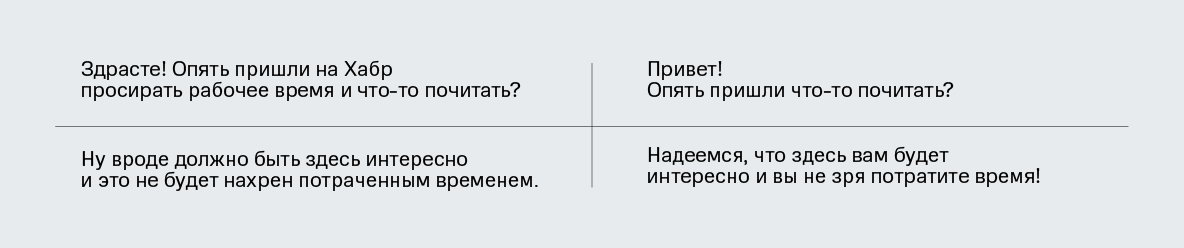
ВНИМАНИЕ! В статье есть примеры текстов, содержащие мат и грубые выражения. Мы ни в коем случае не хотим оскорбить наших читателей, все подобные тексты приведены лишь в научных целях в качестве примеров токсичности в реальных текстах из Интернета.
Всем привет! Меня зовут Дарина Дементьева, я являюсь аспиранткой в Сколковской лаборатории обработки естественного языка (Skoltech NLP), где занимаюсь исследовательскими проектами совместной лаборатории Skoltech NLP и MTS AI. В рамках работы в совместной лаборатории мы провели серию исследований, посвященных важной социальной проблеме – борьбе с токсичной речью в Интернете или детоксификации текстов.
В этой статье мы расскажем про результаты исследований методов детоксификаций для русского языка. Эта работа была опубликована и презентована на конференции Диалог, а также принята в журнал MDPI. Результаты экспериментов на английском языке приняли для презентации на одной из ведущих конференций в области обработки естественного языка EMNLP. Мы представляем вам краткую выжимку с описанием моделей, постановкой и результатами экспериментов, а в конце вы сможете самостоятельно ̶п̶о̶м̶а̶т̶е̶р̶и̶т̶ь̶с̶я̶ ̶в̶ ̶ч̶а̶т̶е̶ протестировать модели в бою. Теперь – добро пожаловать под кат!
Мотивация
Начнем с того, где вообще может пригодиться детоксификация текстов.
Use Case 1: Подсказка пользователю «на эмоциях».
К сожалению, за долгие годы существования интернет стал местом с большим количеством токсичного и обидного контента. Споры в комментариях часто перерастают в перепалки с грубостями и матами. Поэтому многие социальные сети уже сейчас пытаются бороться с подобным контентом:
— Facebook уже тестирует модели, которые будут обнаруживать разжигание словесных перепалок в группах;
— Instagram представил фичу, которая фильтрует оскорбительный контент;
— VK внедрил фичу, которая взамен матерных слов в сообщении предлагает отправить стикер.
Одним из решений борьбы с токсичным контентом может стать предупреждение пользователя о намерении опубликовать оскорбительный контент и рекомендация более нейтрального детоксифицированного варианта его сообщения.

Use Case 2: Цензор для чатботов.
Уже случалось, что кроме людей источником вопиющей токсичности становились чат-боты. Например, резонансный случай произошел с ботом от Microsoft TayTweet, который от бота, любящего людей, прошел путь до настоящего нациста. Сейчас компании относятся более аккуратно к обучению своих ботов. Чтобы предотвратить такие казусы, здесь также могла бы помочь детоксификация текстов.

Данные
Для русского языка существует несколько непараллельных датасетов для классификации токсичности в текстах. Мы взяли два таких корпуса из соревнований на Kaggle [1, 2], и объединили их в единый RuToxic датасет, состоящий из 163187 сэмплов – 31407 (19%) токсичных и 131780 нетоксичных – из таких социальных сетей как Одноклассники и Пикабу.
Методология
Теперь – о методах. Мы протестировали пару простых бейзлайнов и две более сложные модели – detoxGPT, основанный на предобученной ruGPT модели, и condBERT, который основан на BERT архитектуре. Ниже приводим подробное описание каждого метода.
Бейзлайны
Delete. Этот бейзлайн основан на простой идее, позаимствованной из СМИ: часто можно увидеть, как матерные слова «запикиваются» во время телепередач или закрываются звездочками в статьях. По такому же принципу, мы «скроем» маты – удалим их из сообщения. Для этого мы собрали словарь наиболее встречаемых ругательств (но он, конечно же, не исчерпывающий – очень тяжело соревноваться с богатством русского языка). Токенизируя и приводя к леммам при помощи UDPipe, мы удаляем найденные в словаре токены из поступившего на вход токсичного предложения.
Retrieve. Другой бейзлайн основан на гипотезе, что если взять большой корпус нетоксичных текстов, то в нем можно будет найти нетоксичные предложения, в какой-то мере похожих по содержанию на оригинальное токсичное. Мы взяли предложения из нетоксичной части датасета RuToxic и искали предложение с наименьшим расстоянием по векторным представлениям к токсичному запросу. Для получения векторных представлений текстов мы усредняли векторные предложения слов, полученные из fasttext модели от RusVectores. В качестве расстояния между векторами мы использовали косинусное.
detoxGPT
GPT-2 [3] – это мощная языковая модель, которая может быть адаптирована к широкому кругу seq2seq задач NLP с использованием достаточно небольшого набора обучающих данных. До недавнего времени таких моделей для русского языка не было. Осенью 2020 года для конкурса AI Journey были представлены модели ruGPT3, способные генерировать последовательные и понятные тексты на русском языке. Мы протестировали эти модели для нашей задачи. Для этого мы использовали несколько сценариев:
- zero-shot: модель берется «из коробки» как есть (без дообучения). Входные данные представляют собой токсичное предложение, которое мы хотели бы детоксифицировать, с префиксом «Перефразируй» (рус. Paraphrase) и суффиксом «>>>» для обозначения задачи перефразирования. ruGPT3 уже обучен этой задаче, поэтому сценарий аналогичен выполнению перефразирования.
- few-shot: модель также берется «из коробки» без изменений. Однако в отличие от предыдущего сценария мы подаем на вход модели префикс, состоящий из параллельного набора данных токсичных и нейтральных предложений, в следующей форме: >>> . Эти примеры должны помочь модели понять, что нам требуется решить задачу детоксификации, а не просто перефразирования. За параллельными предложениями следует снова входное предложение, которое мы хотели бы детоксифицировать, с префиксом «Перефразируй» и суффиксом >>>.
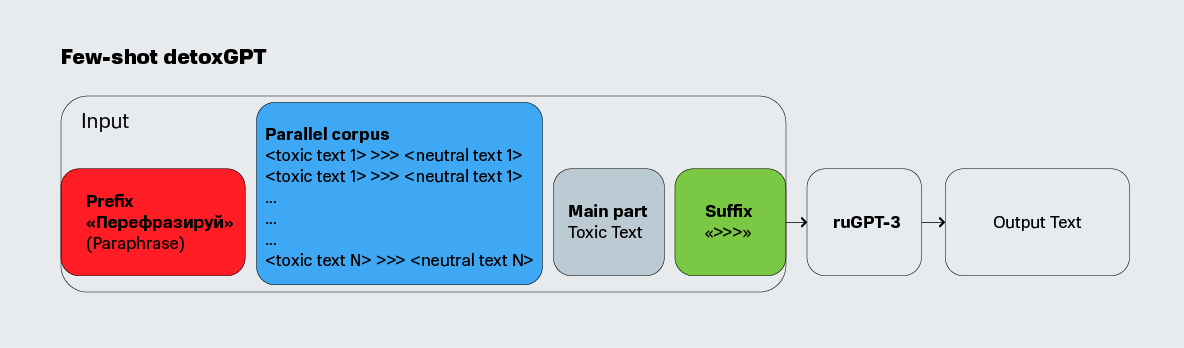
fine-tuned: модель дообучается на наборе параллельных данных. То есть, на вход модели для обучения подаются примеры по типу >>> . Далее на вход модели подается предложение для детоксификации в том же формате, что и в предыдущих пунктах.

Модель GPT, способную решать задачу переноса стиля с токсичного на нетоксичный, мы назвали кодовым названием detoxGPT. Да, главным недостатком этого метода является параллельный корпус данных – он очень редко существует для задач переноса стиля для текстов. Мы собственноручно разметили 200 предложений, случайно выбранных из датасета RuToxic, сделав для них параллельные детоксифицированные версии. Параллельный датасет получился небольшой, но даже после дообучения на таком корпусе данных из 200 предложений, модель уже может решать поставленную задачу. А собрать такой корпус из нескольких сотен параллельных пар не занимает много времени.
Мы потестировали несколько моделей из семейства ruGPT3: small (125 млн параметров с контекстом 2048), medium (350 млн параметров с контекстом 2048) и large (760 млн параметров с контекстом 2048).
condBERT
BERT (Bidirectional Encoder Representations from Transformers) [4] – это языковая модель, которая была обучена предсказывать пропущенные слова по остальной части предложения. Хотя BERT в основном используется для получения векторных представлений слов или задач маркировки последовательностей и классификации текста, его также можно использовать в сценарии заполнения пробелов в предложении, то есть для извлечения слова в контексте, который был заменен токеном [MASK].
Чтобы сделать BERT пригодным для задачи переноса стиля, нам нужно изменить модель так, чтобы маскирование и замена слов изменяли стиль входного предложения. Это можно сделать с помощью дообучения BERT на корпусах, специфичных для исходного и целевого стилей, чтобы модель запомнила распределения слов в соответствии с нужным стилем, и выполняла нужные замены.
Чтобы модель знала, какие именно токены в предложении считать токсичными и для каких надо искать замену, можно приписать токенам словаря BERT-а оценку токсичности. Для этого мы обучили небольшую модель – логистическую регрессию – и приписали ее коэффициенты к каждому токену словаря, назвав «уровнем токсичности».
Этого шага уже достаточно, чтобы использовать модель для переноса стиля. Но BERT все еще может не очень удачно делать замены, так как изначально модель не обучена на замены [MASK] на нетоксичные токены. Чтобы это исправить, модель можно дополнительно дообучить на корпусе текстов, причем этот корпус может быть непараллельным, как вышеописанный датасет RuToxic.
Модель BERT, которая способна решать задачу замены слов, отвечающих за один стиль в предложении на новый стиль, мы назвали condBERT. Преимущество condBERT по сравнению с методом на основе GPT заключается в том, что он не требует никаких параллельных данных для дообучения. Кроме того, предложение не переписывается полностью, что может быть лучшей стратегией с точки зрения сохранения содержания предложения.
Общая идея работы condBERT изображена на картинке:

Для модели condBERT мы также попробовали пару сценариев:
- zero-shot, где BERT был взят из коробки без дополнительного дообучения;
- fine-tuned, где BERT был дообучен на RuToxic датасете для запоминания отношения слов к тому или иному стилю, как было описано выше.
В качестве модели BERT для русского языка мы также попробовали два варианта:
- Conversational RuBERT от DeepPavlov;
- Уменьшенная версия мультиязычного BERT для русского языка от Geotrend.
Оценка переноса стиля
Как было сказано ранее, результат переноса стиля должен соответствовать трем критериям: 1) стиль действительно поменялся на требуемый; 2) основной смысл текста сохранен; 3) новое предложение звучит естественно и, в основном, грамматически корректно. Согласно этим критериям мы и подберем соответствующие метрики для оценки работы наших моделей.
Точность переноса стиля
Для того чтобы проверить, изменился ли стиль предложения, мы использовали классификатор токсичности. Для этого мы дообучили RuBERT модель на RuToxic датасете, получив F1 меру 0.83. Да, модель не идеальна, но ее точности достаточно для использования для оценки переноса стиля. Поскольку мы хотим выполнить задачу детоксификации, ожидаем, что результаты моделей будут нетоксичными. Мы вычисляли необходимую точность переноси стиля (Style Transfer Accuracy, STA) на основе этого предположения.
Сохранение контента
Мы подошли к оценке сохранения контента с двух сторон. Сначала мы оценили метрики, основанные на n-граммах:
1) униграмное перекрытие слов (Word Overlap, WO) между токенами исходного предложения Х и результатом Y: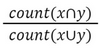 ;
;
2) BLEU, которая отображает точность по n-граммам для n от 1 до 4.
Кроме этого, мы посчитали косинусное расстояние (cosine similarity, CS) между векторными представлениями входного и выходного предложения. В качестве векторного представления предложения мы брали среднее значение векторных представлений его токенов, извлеченных с помощью модели fastText из RusVectores.
Качество языка
Для оценки качества языка сгенерированного предложения мы использовали перплексию (perplexity, PPL), полученную из модели ruGPT2Large, которая не участвовала в экспериментах.
Агрегирующая метрика
Чтобы иметь возможность сравнить все модели по какому-то одному числу, мы агрегировали все вышеперечисленные категории метрик в одну общую метрику, которая вычисляется как геометрическое среднее (geometric mean, GM) между STA, CS и 1/PPL:
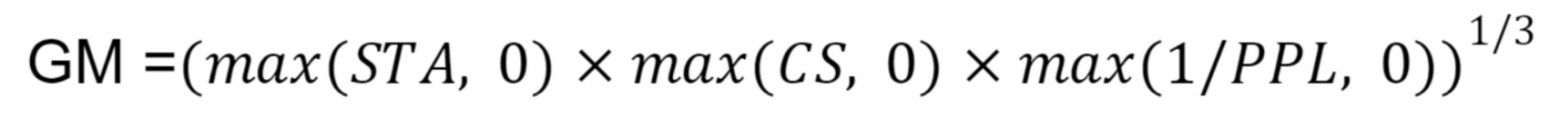
Результаты
Представляем таблицу с результатами экспериментов:

Здесь красным цветом выделены методы, которые выпали из соревнования из-за слишком плохого сохранения контента. Жирным цветом отмечены лучшие результаты, а жирным и подчеркнутым – самые лучшие в своей категории.
Некоторые результаты получились ожидаемыми. Метод Retrieve очень хорош в плане получения финального нетоксичного стиля в предложении, но по сохранению токенов в предложении он абсолютно провалился. Хотя бывают случаи, когда попадание в контент почти стопроцентное!

Хотя метод Delete далеко не всегда мог простым удалением ругательных слов сменить стиль, он изменяет исходное предложение незначительно, поэтому хорошо сохраняетстя контент. В итоге, результат детоксификации с использованием этого метода может быть вполне приемлемым.

Из detoxGPT модели не все сработали хорошо. Сценарии zero-shot и few-shot не выдавали адекватных результатов для всех моделей, так что из сравнения мы их исключили. Вывод, который здесь можно сделать: стоит дообучать такие большие языковые модели для своей задачи. И, действительно, fine-tuned модели сработали достаточно неплохо, а fine-tuned detoxGPT-large по агрегирующей метрике оказалась самой лучшей. Но так как GPT модели генерируют новое предложение с нуля, то они страдают по метрикам сохранения контента. Кроме того, они могут генерировать длинный хвост с какими-то повторяющимися фразами, не обрывая предложение в нужном месте. Но в тех случаях, когда предложение может быть детоксифицировано не просто удалением мата, а требует полного перефразирования, использование detoxGPT уместно.

Модели condBERT сработали неплохо. Проявилось их преимущество: они меняют токены локально, поэтому получили достаточно высокие метрики по сохранению контента. При этом не всегда замена получается удачной: модели меняют токсичное слово на такой же токсичный синоним, но он совершенно не подходит по контексту или вообще не является спец-символом [UNK].

Заключение
Задача переноса стиля, а тем более детоксификации текстов – это новая область в сфере NLP. До сих пор ученые не пришли к единому мнению о том, как более точно и корректно автоматически оценивать подходы для TST.
Мы провели первые эксперименты по детоксификации текстов для русского языка. Как показывает оценка и как видно из примеров, еще есть необходимость улучшать методы. Иногда достаточно удалить из текста нецензурные слова, а в других – заменить их нетоксичными синонимами. В некоторых случаях детоксификация текстов возможна, если полностью их переформулировать. Наиболее многообещающим направлением для развития можно считать объединение всех представленных стратегий и их применение в зависимости от характера токсичности в конкретных предложениях.
Код моделей detoxGPT, condBERT и код для оценки метрик доступен в нашем репозитории. И, как и обещали, предлагаем поиграться с нашими моделями – доступно демо, можно попытаться обругать бота в Телеграме, а если хотите более низкоуровневый взгляд, то можно запустить демку в колабе.
P.S. В конце хотелось бы выразить благодарность всем сооавторам статьи и коллегам из лаборатории MTS AI-Сколтех, без которых эта работа не была бы реализована. Благодарим Даниила Московского, Варвару Логачеву, Давида Дале, Ольгу Козлову, Никиту Семенова и Александра Панченко.



 ;
; 





