Нейронные сети все прочнее входят в нашу жизнь. В последнее время особую значимость приобретают исследования, связанные с обучением искусственных нейронных сетей в сфере анализа естественного языка (NLP, NLU) для создания реалистичных, человечных разговорных «скиллов». Одним из первых примеров «человечных» диалоговых решений стала Xiaoice от Microsoft, которая обладала навыками дружелюбности. Позже такие компании как Яндекс, Google [1], Mail.ru и другие выпустили на рынок своих голосовых помощников. Однако все они столкнулись с фундаментальной проблемой: их решения хорошо выполняют запросы пользователей, связанные с четкими командами («расскажи новости»), но совершенно не обладают человечными способностями, качествами характера, эмуляцией чувств, эмпатией и поэтому не способны поддерживать человеческий разговор на различные темы. При этом «видимость человечности» часто обеспечивается набором шаблонных фраз и шуток, подходящих практически в любой ситуации (неспецифичных контексту разговора).
В этой статье мы покажем, как устроен и как работает разработанный нами умный Ранжировщик ответов для нейросеток Трансформер и какой эффект он оказывает на качество разговора любых генеративных чатботов.
Для того, чтобы решить проблему «человечности» чатботов и голосовых помощников необходимо разработать инфраструктуру базовых навыков (скиллов и стилей) цифровой личности на основе современных архитектур нейронных сетей с возможностью правдоподобного генерирования ответов на запросы пользователей. При этом данная инфраструктура должна обладать возможностью бесшовной интеграции различных архитектур нейронных сетей, что является ключевым элементом, обеспечивающим качество когерентного разговора при переключении скиллов.
Мы в Аватар Машина считаем, что важность данного исследования обусловлена его центральным местом в науке и исследовании работы мозга и, как следствие, работы нейросетевых архитектур, которые, как известно, во многом калькированно повторяют архитектуру некоторых его отделов.
Например, директор Научно-координационного совета Центра науки и технологий искусственного интеллекта МФТИ Сергей Шумский в своей книге «Машинный интеллект. Очерки по теории машинного обучения и искусственного интеллекта» [2] отмечает важность повторения, или, более верно «воссоздания» биологической архитектуры различных отделов мозга в искусственных нейронных сетях. В книге он предлагает подход к созданию «сильного» искусственного интеллекта с использованием принципов работы человеческого мозга. Благодаря правильной архитектуре исследователи смогли бы добиться и аналогичных когнитивных свойств искусственных систем. Пока же уровень развития когнитивных свойств в сфере Conversational Ai (разговорного искусственного интеллекта) является довольно низким: слабая память в нейросетях LSTM, простые seq2seq модели, даже эмерджентный феномен «внимания» (attention) в самых современных нейросетях трансформер довольно ограниченно моделирует то, как человек в реальности работает с объектами, обращает внимание и запоминает важные факты в потоке событий.
Доктор Alan D. Thompson, являющийся экспертом в ИИ на семинаре «Новая нерелевантность интеллекта» [3] в августе 2021го года представил свой взгляд на разрозненность моделей нейросетей и то, как они соответствуют современным представлениям о работе мозга. На рисунке ниже представлена таблица соответствия различных когнитивных способностей человека и тех отделов мозга, которые за них отвечают. В частности за разговор в данном сравнении представлены ответственными чатботы от Facebook Ai – BlenderBot (первой версии) [4] и система разговорного ИИ с интерактивом от Google – LaMDa [5]. Однако данные системы, несмотря на всю свою сложную структуру обладают существенным недостатком – они работают, используя раздельные пайплайны из разных нейросетей, в результате чего достигнуть эмерджентного эффекта невозможно, ведь в таких системах модули и компоненты являются отдельными не архитектурно, как в нейросетях, а структурно – то есть они объединены программно, через API и вызовы функций, что хорошо работает инженерно, но не позволяет появиться в такой системе новым свойствам.

В этой разработке мы учитывали недостатки существующих, лучших на сегодняшний день разговорных систем, в том числе и команды разработки бота ChirpyCardinal [6] (2е место в конкурсе от компании Amazon Alexa Prize), проекта AliceMind [7] от китайской компании Alibaba. Очень хорош также и чатбот от Сбера [статья] - и все же в некоторых сеттингах мы замечали разрывы в логике поддержания разговора, при том, что в целом ответы на каждую реплику у него очень разумные.
Итак, постановка исследовательской задачи такая: разработать систему ранжирования реплик, генерируемых чатботом так, чтобы она работала когнитивно близко к тому, как человек выбирает ту или иную реплику в контексте разговора – как правило, человек рассматривает несколько вариантов ответных реплик, учитывая всю историю общения, важные факты и согласованность по тематике. Именно так и должна работать система ранжирования – ведь сейчас генераторы в нейросетях трансформер устроены куда более просто.
На данный момент очень актуальна проблема генерации текста в нейросетевых генеративных ботах, в частности, построенных на базе GPT(Generative Pre-trained Transformer)[8]. Генерация ведется на уровне токенов, а выбирать следующий токен в последовательности можно разными способами, например, при помощи генератора случайных чисел, где нейросеть задает для него распределение вероятностей на каждом шаге. Также существует стратегия выбирать на каждом шаге токен, которому соответствует наибольшая вероятность, или использовать алгоритмы на вроде метода поиска по лучу (beam search). [9] Этими методами возможно сгенерировать несколько версий ответов на один вопрос или реплику. Ранжирование версий ответов позволяет улучшать качество генерации, делая выход модели более согласованным по смыслу(тематике) с вопросом или контекстом. Предложенный в этой работе алгоритм ранжирования работает по следующему принципу: текст вопроса заменяется на вектор признаков, аналогично векторизуется каждая версия ответа, рассчитываются расстояния между вектором вопроса или контекста и каждым вектором ответа, таким образом, чтобы ответ с нулевым индексом был наиболее подходящим по тематике к вопросу.
В нашей разработке мы предлагаем алгоритм векторизации текста на базе нейронной сети с тремя функциями ошибки, такими как ошибка классификации, ошибка моделирования распределения (дивергенция Кульбака-Лейблера) и ошибка дисперсии (отклонение логарифма дисперсии от вектора нулей), что позволяет преобразовывать тексты в вектора без разрывов в пространстве признаков.
Далее рассмотрим основные шаги исследования: набор данных, алгоритм, векторизацию.
Описание набора данных
Для исследования было выбрано 2 набора данных:
Первый набор данных использовался для предварительной оценки модели, включает в себя девять тем: игры, программное обеспечение, искусство, технологии, отношения, хобби, психология, облачные технологии, языки программирования.
Второй набор данных представлял собой 139 тысяч сэмплов текстов, разделенных на 66 классов (тем), которые чаще всего использовались в общении с ботом, основные темы: игры, книги, программное обеспечение, вселенная, футбол, единоборства, искусство, технологии, отношения и т.п.
Данный датасет, его распределение тематик и объем был использован потому, что по нашим наблюдениям именно эти темы наиболее часто встречаются в живом разговоре, они достаточно полно представлены в Интернете и датасет относительно легко собрать из открытых источников в нужно объеме.
Описание алгоритма
Алгоритм ранжирования представлен на рисунке 23. Текст поступает в блок предварительной обработки, который преобразует слова текста в токены. Нейронная сеть блока векторизации формирует вектор фиксированной размерности из последовательности токенов. Все тексты, которые должны быть ранжированы векторизуются вышеописанным способом и добавляются в массив структур вектор-текст. После чего алгоритм ранжирования сортирует векторы по неубыванию расстояния и текст, соотнесенный с вектором с нулевым индексом является с точки зрения модели наиболее подходящим по тематике к тексту вопроса.
Основное требование к пространству признаков следующее: близкие по смыслу тексты должны быть преобразованы в близкие по некоторой метрике точки (векторы).

Предварительная обработка текста
На первом этапе текст стандартизируется, т.е. из него удаляются все знаки препинания и специальные символы, множественные пробелы заменяются на одинарные, также удаляются стоп-слова, слова заменяются на соответствующие им леммы. Мы рассмотрели две стратегии токенизации:
а) токенизация на уровне лемм, и
б) токенизация при помощи предварительно обученного токенизатора BPE[10], используемого в GPT2[11].
Во втором случае возможна работа с текстами, содержащими неизвестные слова и с опечатками. В случае работы с леммами составляется словарь из 30 тыс. наиболее часто встречающихся лемм. Блок-схема модуля предварительной обработки текстов показана на рисунке.

Векторизация
Мы разработали две стратегии векторизации: выход предпоследнего слоя нейросетевого классификатора и выход предсказания математического ожидания в вариационном классификаторе, он описан ниже.
Входной слой — это слой встраивания, он ставит вектор в соответствие каждому индексу. Последовательность индексов заменяется на матрицу. Изначально векторы либо выбираются случайными, либо задаются предварительно обученные, а далее, во время обучения сети могут обучаться вместе со всей сетью при помощи обратного распространения ошибки (backpropagation).
В данной работе в качестве классификаторов были исследованы следующие сети:
одномерная сверточная,
полносвязная,
рекуррентная,
гибридная: содержащая как сверточные, так и рекуррентные слои.
Одномерные сверточные и рекуррентные нейронные сети хорошо зарекомендовали себя для работы с последовательностями[12], в том числе и с текстами. [13, 14] Исследование проводилось на данных из первого датасета содержащего 9 классов (тем), описанного выше в подразделе Описание набора данных.
Результаты исследования
Ниже, на рисунке 4, представлены графики обучения некоторых архитектур нейронных сетей из этого исследования, без предварительно обученных векторов встраивания. А именно, одномерной сверточной сети, полносвязной, LSTM, и гибридной, содержащей, как одномерные сверточные слои, так и LSTM ячейки.

На рисунке 5 показаны графики обучения следующих архитектур (одномерной сверточной сети с 3мя сверточными слоями, одномерной сверточной сети с одним сверточным слоем и LSTM сети) с предварительно обученными векторами встраивания.

Результаты тестирования нейронных сетей сведены в таблицу 1, все замеры выполнены на валидационной выборке.
Номер эксперимента | Вероятность правильного распознавания (Accuracy) | Ошибка на валидационных данных (Перекрестная энтропия) |
Вектора встраивания инициализированы случайными числами | ||
Сверточная сеть №1 | 71.05% | 0.8898 |
Полносвязная | 74.57% | 0.767 |
Сверточная сеть №2 | 74.44% | 0.7862 |
LSTM | 73.52% | 0.8146 |
GRU | 73.19% | 0.8177 |
CNN+LSTM | 71.46% | 0.8886 |
Пред. обученные вектора встраивания (Word2Vec) | ||
Сверточная сеть №1 | 69.38% | 0.8714 |
Сверточная сеть №2 | 75.11% | 0.7357 |
LSTM | 73.77% | 0.8293 |
Таблица 1. Результаты тестирования различных архитектур
В конечном итоге наилучший результат показывает Сверточная сеть №2, вероятность правильного распознавания у нее составила 75.11%.
В результате описанного в данном разделе исследования была разработана модель ранжировщика реплик(ответов) генеративной модели. Данная модель является прототипом модели выбора логичного ответа у человека, однако, как мы рассмотрим далее в следующем разделе есть несколько вопросов, касающихся эффективности ее срабатывания в различных контекстах разговора – плавности переключения тематик и их согласованности внутри самих сгенерированных реплик.
Обучение на новой выборке
Для дальнейшего обучения на втором наборе данных в 139 тыс. реплик, разделенных на 66 классов, была выбрана одномерная сверточная сеть с одним сверточным и одним полносвязным слоем, т.к. она обеспечивала наивысшую вероятность правильного распознавания. График обучения сверточной сети для распознавания 66 классов представлен на рисунке 27.

Вероятность правильного распознавания на валидационных данных составила 64.01%
Ниже представлена визуализация векторов, получаемых из текстов, на скрытом слое: на рисунке изображены все 139 тысяч текстовых реплик, одна текстовая реплика — одна точка, цветом отмечены классы. На рисунке 7 слева сделана проекция векторного пространства на 2 оси, на рисунке 7 справа — визуализация в 3х мерном пространстве. Если рассмотреть распределение векторов после векторизации текстов, то можно заметить, что их распределение имеет довольно сложный вид и не обеспечивает плавного перехода между темами.
Пример. Представьте, что вы говорите с собеседником на тему отношений, и постепенно тема меняется на политику. На какую тему должна быть реплика после смены темы разговора? Про отношения, так как контекст содержит много реплик с этим классом или про политику, так как это новая актуальная тема, а может быть нужна смесь? Здесь нет однозначного ответа. Если темы различаются между собой сильно, то они попадут в разные «лучи салюта» - чатбот не сможет сгенерировать реплику, которая бы соответствовала обеим тематикам. Правда, это мы наблюдаем в комментариях почти к любому социальному ролику или статье - разброс тем даже внутри одной отрасли колоссальный и поэтому часто комментарии людей выглядят оторванными от контекста.

Для реализации более плавного перехода между темами была введена дополнительная функция потерь, известная как дивергенция Кульбака – Лейблера [14], используемая в вариационных автокодировщиках [15]. Также была введена составляющая функции потерь, отвечающая за форму и размер области в пространстве признаков, ошибка которой увеличивается с ростом отклонения логарифма дисперсии от вектора, состоящего из нулей.
Дивергенция Кульбака – Лейблера показывает отклонение полученного распределения от ожидаемого. В данной задаче мы хотим получить гауссово распределение, т.е. чтобы наше признаковое пространство было в виде гиперсферы.
Таким образом, мы ожидаем получить гиперсферы без разрывов, а получаем что-то другое — так вот этот лосс показывает насколько сильно мы отклонились. А производная от него по параметрам модели позволяет настраивать модель так, чтобы она «выдавала» именно гиперсферы.
Ошибка Кульбака-Лейблера рассчитывается по следующей формуле: в данной формуле расписан след и определитель диагональной ковариационной матрицы,
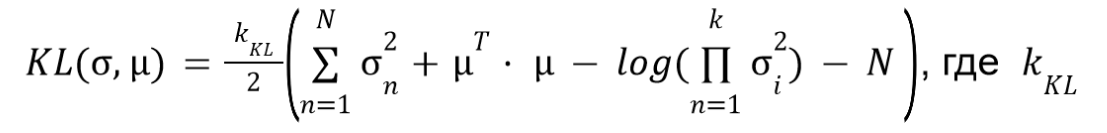
— коэффициент вклада ошибки Кульбака – Лейблера в общую функцию потерь.
Ошибка дисперсии рассчитывается по формуле:

В качестве ошибки классификации была использована категориальная перекрестная энтропия,

Коэффициенты kKL, kVar, kH введены для настройки модели. В данной работе они соответственно равны 7, 2, 1.
На рисунке 8 показана блок-схема классификатора, для векторизации используется выход предсказывающий вектор математического ожидания генератора случайных чисел с гауссовым распределением.

На рисунке 9 показана зависимость различных составляющих функции ошибки от эпохи обучения. По причине того, что масштаб изменений других составляющих функции потерь сильно отличается от масштаба изменений отклонения логарифма дисперсии, ошибка дисперсии вынесена в другом масштабе на рисунок 10.

Ниже представлена визуализация пространства признаков, на рисунке слева — проекция на две оси, на рисунке справа — на три.

Рассмотрим далее параметры при использовании в качестве токенизатора предварительно обученного токенизатора BPE. На рисунке 12 показана зависимость различных составляющих функции ошибки от эпохи обучения, также на рисунке 13, продемонстрированы проекция пространства признаков на две и три оси соответственно, параметры функции ошибки следующие,
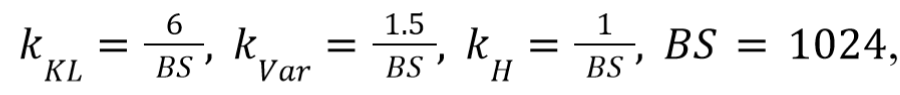
где BS размер мини-пакета.


Ключевым элементом данного исследования является выбор метрики и архитектуры для алгоритма ранжирования.
Наилучшая метрика должна обеспечивать лучшую точность при ее использовании в методе ближайшего соседа в задаче классификации, т.к. это означает, что при ранжировании в самом верху списка (с нулевым индексом) окажется текст той же темы, что и текст на входе. Результаты тестирования различных метрик, на двух последних архитектурах с токенизацией на уровне лемм сведены в таблицу 2.
Метрика | Без использования дивергенции Кульбака-Лейблера и ошибки дисперсии | С использованием дивергенции Кульбака-Лейблера и ошибки дисперсии | ||
F1 микро усреднение | F1 макро усреднение | F1 микро усреднение | F1 макро усреднение | |
Евклидова | 78.2% | 67.74% | 90.2% | 82.26% |
Манхэттена | 78.1% | 66.04% | 89.7% | 80.67% |
Чебышёва | 74.3% | 60.86% | 88.6% | 79.83% |
Минковского p=3 | 78% | 66.9% | 89.9% | 81.53% |
Минковского p=4 | 77.3% | 65.56% | 89.8% | 81.23% |
Минковского p=5 | 76.4% | 63.97% | 89.7% | 80.9% |
Минковского p=6 | 77% | 64.65% | 89.4% | 80.25% |
Минковского p=7 | 76.7% | 64.48% | 89.2% | 80.01% |
Минковского p=8 | 76.4% | 64.18% | 89.1% | 80.02% |
Минковского p=9 | 76.3% | 63.79% | 89.1% | 80.02% |
Канберры | 76.5% | 64.54% | 83.3% | 72.25% |
Стандартизированная Евклидова метрика | 77.0% | 64.65% | 87.0% | 78.8% |
Несходство Брея-Кертиса | 79.1% | 67.02% | 89.3% | 80.66% |
Таблица 2. Результат тестирования метрик, токенизация на уровне лемм
Сравнение различных режимов обучения, а также сравнение с векторизацией при помощи многоязычного BERT’а, без дообучения на нашем наборе данных, с использованием предварительно обученного токенизатора BPE, сведены в таблицу 3, максимальное число токенов в последовательности составляет 85, вероятность правильного распознавания оценивалась, как усредненная по 66 классам.
Обучено на лемматизированных | Обучено на не лемматизированных | Bert | ||
Датасет без лемматизации | Датасет с лемматизацией | |||
Евклидова | 50.6% | 82.9% | 62.42% | 26.4% |
Манхэттен | 49.9% | 82.3% | 62.23% | 26.0% |
Чебышёва | 46.5% | 80.1% | 61.74% | 20.3% |
Несходство Брея-Кертиса | 51.3% | 82.3% | 62.74% | 28.6% |
Таблица 3. Результат тестирования метрик, токенизация на уровне байт
Ниже на рисунке представлены фрагменты программного кода реализации Ранжировщика, в качестве скилла в экосистеме скиллов и стилей: на рисунке 14 класс Ranker и его методы подгрузки параметров модели, удаление стоп-слов. Полностью код мы не раскрываем.

Результаты диалоговой модели и тестирование на разумность
Как видно из таблицы 2, наилучшее качества ранжировщика обеспечивается использованием в качестве модуля векторизации классификатора с использованием моделирования распределения посредством введения дивергенции Кульбака — Лейблера и контроля дисперсии.
Евклидова метрика обеспечивает наилучшее качество ранжирования, при использовании токенизации на уровне лемм, а при токенизации на уровне байт, наилучшее качество было получено при использовании «несходства Брея-Кертиса». Объем памяти занимаемой нашей моделью составляет всего 10 Мб.
Ранжирование версий ответов позволяет улучшать качество генерации, делая выход модели более согласованным по смыслу(тематике) с вопросом или контекстом. Важно отметить, что согласование работает с учетом всего контекста разговора, а не только последней реплики пользователя.
Поскольку бенчмаркинг (benchmarking) диалоговых моделей является сейчас активной исследовательской темой и на сегодняшний день еще не существует индустриального стандарта сравнения общения чатботов – мы оценивали:
метрику SSA от Google [1] (Sensibleness and Specificity Average – среднее между специфичностью и релевантностью ответа в данном контексте) и
общий показатель вовлеченности и интереса общения, выражающийся в количестве пар реплик общения одного пользователя за сессию (промежуток времени между репликами не более 1 минуты) усреднённый по всем пользователям.
Мы расскажем о сеттинге тестирования позже. Рассмотрим сначала диалоговую модель без ранжировщика и оценим в целом логику его ответов на рисунке ниже:

В сеттинге выше модель выбирает ответ используя beam search, однако какое бы число лучей ни было использовано, это все равно не позволяет работать с логикой ответа на уровне целого предложения – ведь генерация происходит по токенам.
Ответы при этой похожи на ответы Яндекс Алисы: они иногда смешные, но их основное свойство это неспецифичность, то есть, как правило, такие ответы подходят под многие контексты сразу и именно поэтому кажутся пользователям, общающимся с ботом слишком общими, не содержащими новой полезной информации и отсылок к предыдущим репликам.
Еще одно свойство ответов: они в целом следуют теме разговора, но сами темы имеют часто нечеткие границы и поэтому часто вместо ответа на вопрос или исполнения просьбы (разные модальности) модель генерирует ответ по теме, но полностью противоречивый по содержанию.
Наша диалоговая модель

Диалог с моделью, имеющей ранжировщик и личность(мы опишем ее в другой статье) существенно отличается в лучшую сторону по следующим характеристическим параметрам:
Ответы специфичные: они относятся к данной конкретной ситуации, возникшей в контексте разговора.
Ответы релевантные: они разумны и логичны, семантически согласованы и грамматически верны: если пользователь задавал вопрос, то модель дает ответ.
У бота есть личность, он отыгрывает девушку и это прослеживается в глаголах и местоимениях женского рода(«люблю ходить одна»)
Бот вежливый и обладает знаниями (хотя боту и не обязательно быть вежливым) и поддерживает более качественное общение на темы о психологии, сексе, отношениях, потому что для обучения использовался преимущественно такой датасет.
В процессе ранжировщик рассматривал в том числе и такие варианты генерации:
«И мне» (слишком короткий и неспецифичный)
«А мне холодно» (нерелевантный теме разговора)Однако выбран был наиболее согласованный по контексту и тематике вариант:
«У меня такая же проблема, только еще зима не закончилась. Так хочется тепла и солнца..»
Ниже представлены тематически другие разговоры с разработанной моделью и скиллами ранжировщика и личности.


")
Разработанная модель Ранжировщика является в целом хорошим научным результатом и развитием идеи выбора логичного и разумного ответа в зависимости от контекста разговора.
Модель является прототипом скилла когнитивной способности человека к выбору логичного продолжения разговора в соответствии с целью, состоянием, эмоциями и другими параметрами, которые являются внешними, но которые проявлены в разговоре. Модель имеет малый размер (10мб.), легко обучается и не требует огромных массивов датасетов для обучения на новые тематики. Наилучшее качества ранжировщика обеспечивается использованием в качестве модуля векторизации классификатора с использованием моделирования распределения посредством введение дивергенции Кульбака — Лейблера и контроля дисперсии. Евклидова метрика обеспечивает наилучшее качество ранжирования, при использовании токенизации на уровне лемм, при токенизации на уровне байт, наилучшее качество было получено при использовании «несходства Брея-Кертиса».
Наш бот полностью готов к коммерческому внедрению и уже продается на рынке. Результаты разработки мы уже докладывали на конференции по искусственному интеллекту Ai-men. Подроднее о боте можно узнать на сайте.
Список литературы
Towards a Human-like Open-Domain Chatbot [Электронный ресурс] Режим доступа https://arxiv.org/abs/2001.09977 свободный. - Загл. с экрана (дата обращения: 1.02.2021).
Сергей Шумский. Машинный интеллект. Очерки по теории машинного обучения и искусственного интеллекта. — изд. первое, — М.: Наука, 2020. — 335 с. https://www.litres.ru/sergey-shumskiy/mashinnyy-intellekt-ocherki-po-teorii-mashinnogo-48958628/
Alan D. Thompson. AI + the human brain. The new irrelevance of intelligence [Электронный ресурс] https://lifearchitect.ai/brain/ - Загл. с экрана (дата обращения: 10.08.2021)
Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston // Recipes for building an open-domain chatbot // April 7, 2020 // URL https://arxiv.org/abs/2004.13637
LaMDA: our breakthrough conversation technology. [Электронный ресурс] https://blog.google/technology/ai/lamda/ - Загл. с экрана (дата обращения: 10.08.2021)
Welcome to Chirpy Cardinal. [Электронный ресурс] https://stanfordnlp.github.io/chirpycardinal/ - Загл. с экрана (дата обращения: 10.08.2021)
AliceMind: ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab. [Электронный ресурс] https://github.com/alibaba/AliceMind - Загл. с экрана (дата обращения: 10.08.2021)
Jianfeng Gao, Baolin Peng, Chunyuan Li, Jinchao Li, Shahin Shayandeh, Lars Liden, Heung-Yeung Shum // Robust Conversational AI with Grounded Text Generation // September 7, 2020 // URL https://arxiv.org/pdf/2009.03457.pdf
Luca Massarelli, Fabio Petroni, Aleksandra Piktus, Myle Ott, Tim Rocktaschel, Vassilis Plachouras, Fabrizio Silvestri, Sebastian Riedel // How Decoding Strategies Affect the Verifiability of Generated Text // 29 Sep 2020// URL https://arxiv.org/pdf/1911.03587.pdf
Serkan Kiranyaz, Onur Avci, Osama Abdeljaber, Turker Ince, Moncef Gabbouj, Daniel J. Inman // 1D Convolutional Neural Networks and Applications – A Survey// URL: https://arxiv.org/ftp/arxiv/papers/1905/1905.03554.pdf
Marc Moreno Lopez, Jugal Kalita // Deep Learning applied to NLP // 9 Mar 2017// URL https://arxiv.org/pdf/1703.03091.pdf
Wenpeng Yin, Katharina Kann, Mo Yu, Hinrich Schütze // Comparative Study of CNN and RNN for Natural Language Processing // 7 Feb 2017 // URL https://arxiv.org/abs/1702.01923
Raphael Shu, Hideki Nakayama // COMPRESSING WORD EMBEDDINGS VIA DEEP COMPOSITIONAL CODE LEARNING // 17 Nov 2017 // URL https://arxiv.org/pdf/1711.01068.pdf
Kullback S. Information Theory and Statistics. — John Wiley & Sons, 1959
Diederik P. Kingma, Max Welling // An Introduction to Variational Autoencoders // 6 Jun 2019 // URL https://arxiv.org/abs/1906.02691
Работа выполнена при поддержке Фонда содействия инновациям.

