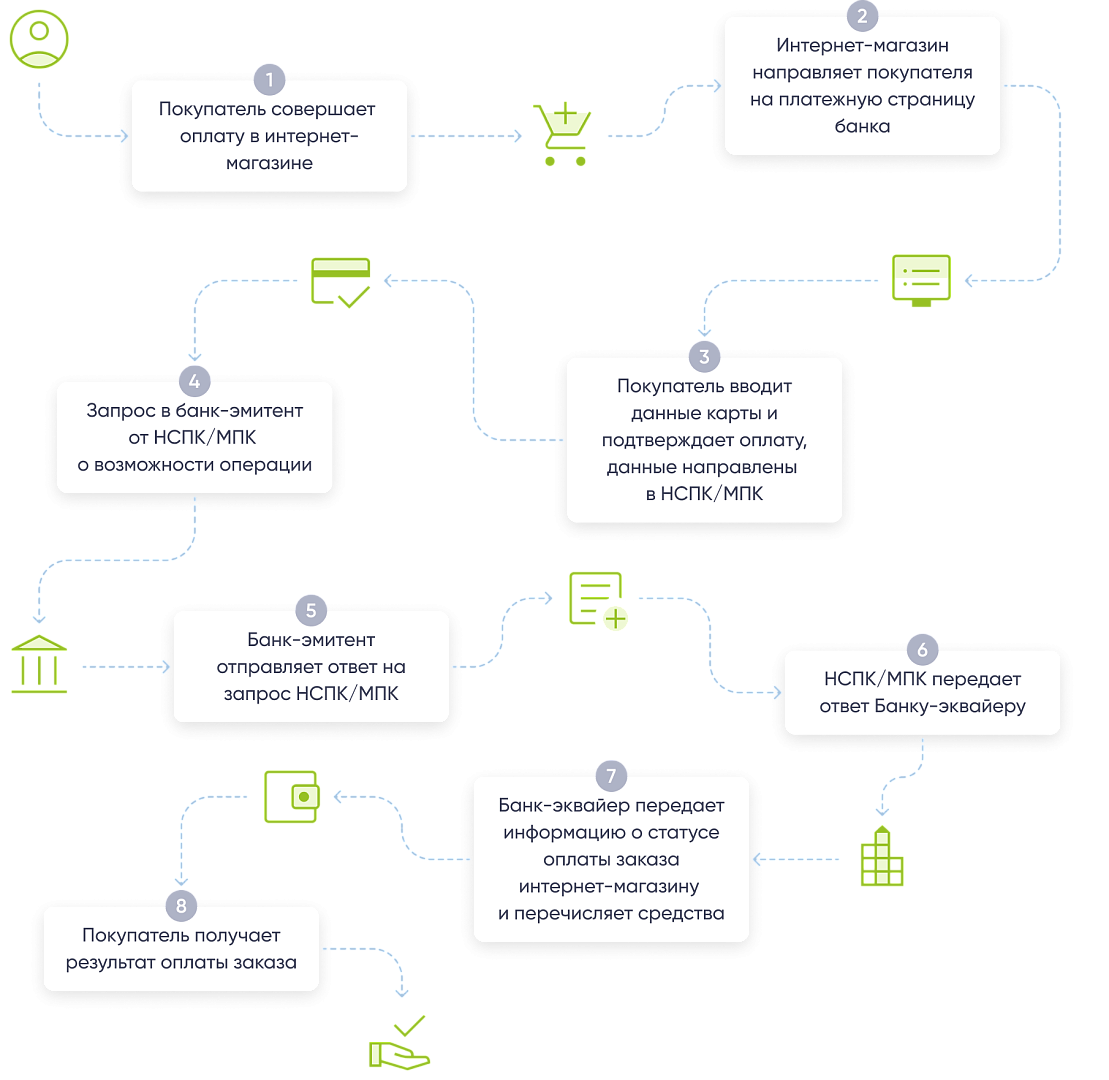
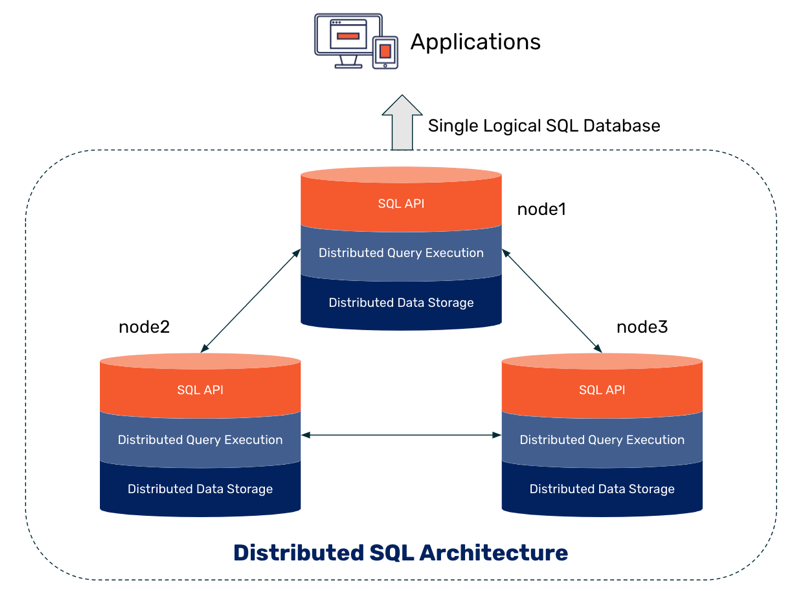
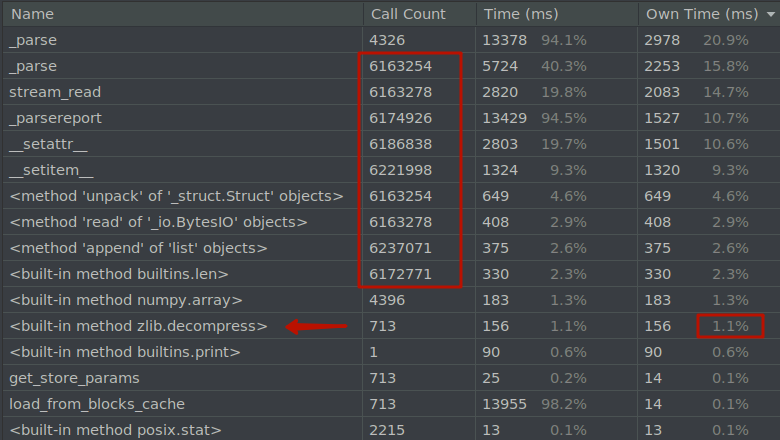
Всем добрый день.
В своей предыдущей статье я уже упомянул о разрабатываемой нами системе, которая решает, казалось бы, не решаемую задачу - а именно автодискавери сетевых элементов в сетях телеком операторов, построение топологий, поиск путей прохождения трафика на основе информации, полученной из самих сетевых элементов. При этом стоит уточнить, что система не нуждается в интеграции со сторонними системами управления, такими как NCE (бывший Huawei u2000 TN), SoEM (СУ Ericsson), Aviat Provision, NFM-P (Nokia), и любыми другими. Т.е. система самодостаточна и способна работать в полностью автономном режиме.
Начну с той проблемы, которая возникла много десятилетий тому назад - и название этой проблемы - актуальная информация о состоянии сетей в режиме он-лайн. Дело в том, что мультисервисные сети давно стали мультивендорными - т.е. в каком-то филиале N любого провайдера связи, с течением времени скопилось множество разновендорного оборудования - сети MEN построены на Cisco, Huawei, Nokia. РРЛ - NEC, Huawei, Nokia и т.д. до бесконечности и в разных последовательностях. И т.к. каждый вендор не стремится создать универсальную СУ, которая могла хотя бы нарисовать топологию мультивендорной сети, приходится изобретать велосипед раз за разом.
Чаще всего велосипеды получались не далеко едущими, одноколесными, неудобными, без сидения или колес. Даже в системах управления крупных вендоров, функциональность не блистала. Более менее вменяемое я увидел в СУ Huawei - NCE. Но опять таки - каждый домен типов оборудования на своих вкладках, и единую топологию не получить - т.е. нельзя отобразить единовременно и на одной подложке сеть MBH (MEN+RRL). Не говоря уже о единовременном отображении специфических проблем, за которыми следят операторы связи - высокая утилизация интерфейсов, BBE/ES/SES/UAS, FCS, RSL Low, QoS Drop по очередям и пр.