Потоки — это Goto параллельного программирования
6 мин
Сразу раскрою мысль, вынесенную в заголовок. Использование потоков (также именуемых нити, треды, англ. threads) и средств прямой манипуляции ими (создание, уничтожение, синхронизация) для написания параллельных приложений оказывает столь же пагубное влияние на сложность алгоритмов, качество кода и скорость его отладки, какое вносило использование оператора Goto в последовательных программах.
Как когда-то программисты отказались от неструктурированных переходов, нам необходимо отказаться от прямого использования потоков сейчас и в будущем. И так же, как каждый из нас использует структурные блоки вместо Goto, вместо потоков должны использоваться структуры, построенные поверх них. Благо, все инструменты для этого появились во вполне традиционных языках.
 Автор фото: Rainer Zenz
Автор фото: Rainer Zenz
Как когда-то программисты отказались от неструктурированных переходов, нам необходимо отказаться от прямого использования потоков сейчас и в будущем. И так же, как каждый из нас использует структурные блоки вместо Goto, вместо потоков должны использоваться структуры, построенные поверх них. Благо, все инструменты для этого появились во вполне традиционных языках.


 Эта статья посвящена
Эта статья посвящена 

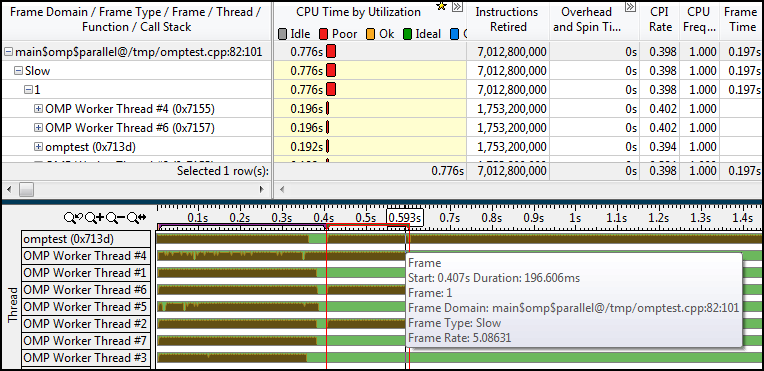
 C января этого года Билл Макклоски вместе с Дэвидом Андерсоном работали над тем, чтобы сделать «Файерфокс» мультипроцессовым, в этом им помогали Том Шустер (evilpie), Фелипе Гомез и Марк Хаммонд. И теперь настал момент, когда они
C января этого года Билл Макклоски вместе с Дэвидом Андерсоном работали над тем, чтобы сделать «Файерфокс» мультипроцессовым, в этом им помогали Том Шустер (evilpie), Фелипе Гомез и Марк Хаммонд. И теперь настал момент, когда они 

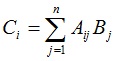 . Алгоритм вычисления вектора C (m × 1 элементов) легко распараллеливается, так как значение i-го элемента вектора не зависит от значений других его элементов. Перед запуском примера из исходников рекомендуется установить Microsoft Robotics.
. Алгоритм вычисления вектора C (m × 1 элементов) легко распараллеливается, так как значение i-го элемента вектора не зависит от значений других его элементов. Перед запуском примера из исходников рекомендуется установить Microsoft Robotics.