
Архивная репликация в PostgreSQL: пошаговая инструкция
9 мин

Разбираем c Григорием Тарасенко, инженером команды SQL на примере, как реплицировать базы без использования слотов репликации.
Разбираем c Григорием Тарасенко, инженером команды SQL на примере, как реплицировать базы без использования слотов репликации.
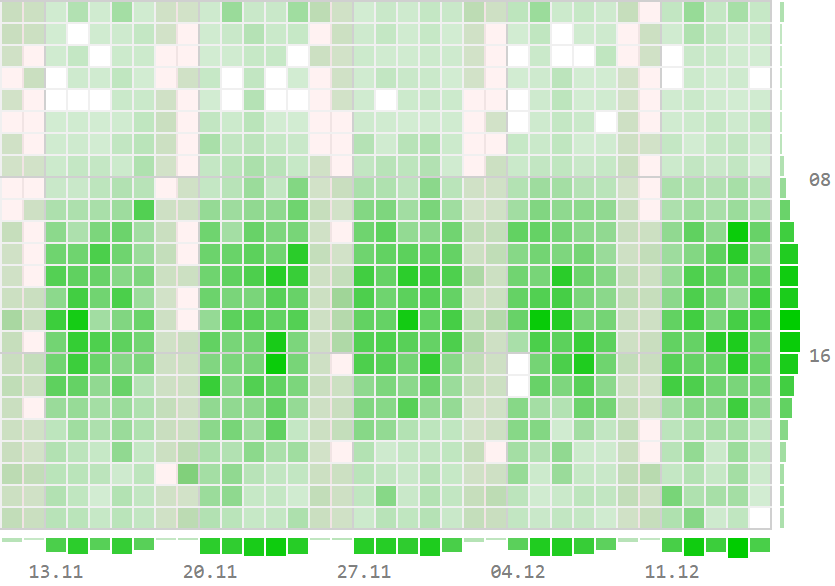
Немного отвлечемся от простых SELECT и посмотрим на реальной бизнес-задаче построения различных "тепловых карт" и "шахматок", как знание возможностей SQL может облегчить жизнь и разработчику, и его базе.

За несколько лет Whoosh в несколько раз вырос по числу самокатов, пользователей и локаций, а данных по ним накопилось на 30 терабайт. Прежней архитектуры уже не хватало для работы. К тому же платить за I/O (input/output)-операции на Aurora (PostgreSQL) выходило дорого (тогда еще не было I/O‑optimized версии, однако с ее появлением, актуальность не исчезла). Другое дело — Redshift: расходы постоянны (n$/час), а работает он быстрее, благодаря колоночному формату хранения данных. В этом году мы переехали с одного хранилища на базе PostgreSQL — того, где вся отчётность для бизнеса и модели dbt — на рельсы Data Lake в AWS.
Меня зовут Никита Зеленский, я главный по данным в Whoosh. Эту статью я написал вместе с другими участниками переезда — Пашей Сивохиным, ГИС-аналитиком, и Костей Малыхиным, руководителем группы анализа данных. Надеюсь, наш опыт будет полезен всем, кому предстоит миграция данных, особенно если вы работаете с геоаналитикой.

Продолжаю публикацию расширенных транскриптов лекционного курса "PostgreSQL для начинающих", подготовленного мной в рамках "Школы backend-разработчика" в "Тензоре".
Сегодня поговорим о самых простых, но важных, возможностях команды SELECT, наиболее часто используемой при работе с базами данных - формировании выборок (VALUES), их ограничении (LIMIT/OFFSET/FETCH), фильтрации (WHERE/HAVING), сортировке (ORDER BY), уникализации (DISTINCT) и группировке (GROUP BY).
Как обычно, для предпочитающих смотреть и слушать, а не читать - доступна видеозапись и слайды.

Этим постом я запускаю публикацию расширенных транскриптов лекционного курса "PostgreSQL для начинающих", подготовленного мной в рамках "Школы backend-разработчика" в "Тензоре".
В программе: рассказ об основах SQL, возможностях простых и сложных SELECT, анализ производительности запросов, разбор [не]эффективного применения индексов и особенностей работы транзакций и блокировок в этой СУБД.
Курс не претендует на лавры "войти в айти", поэтому подразумевает наличие у слушателя опыта программирования или работы с другими СУБД, и, главное, желания самостоятельно изучать тему работы с PostgreSQL глубже.
Для тех, кому комфортнее смотреть и слушать, а не читать - доступна видеозапись и слайды.
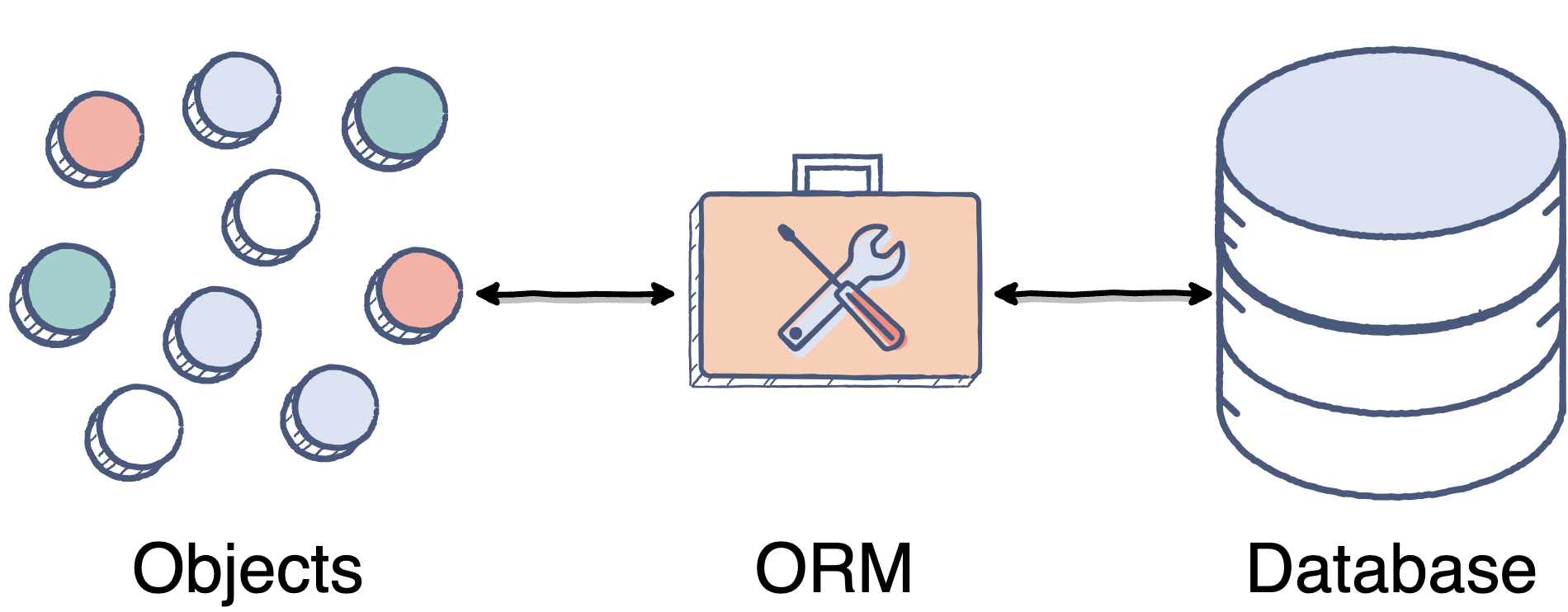
Идея упростить или абстрагировать код с помощью ORM, возможно, имеет очень ограниченный контекст применимости. По сути ORM хорош для приложений уровня простого CRUD, а дальше начинает только мешать. А CRUD-приложений в реальной жизни очень мало.
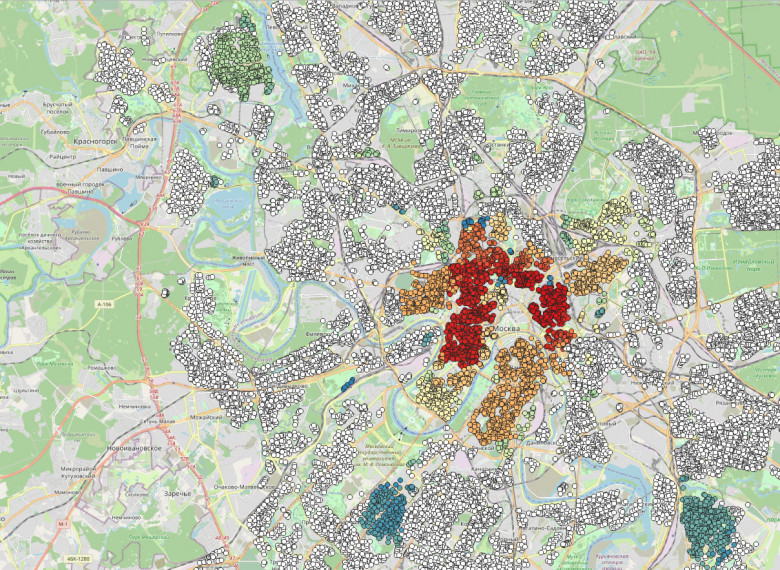
На Хабре было много упоминаний pgvector в обзорах Postgresso. И каждый раз новость была про место которое где-то за границей и далеко. Многие коммерческие решения для хранения и поиска векторов в базе данных нынче не доступны, а pgvector доступен любому, тем более в самой популярной базе в России. Применим pgvector для задачи поиска похожих домов по инфраструктуре для детей в Москве.
В этой статье покажу на этом практическом примере как хранить, кластеризовать алгоритмом DBSCANвекторы и искать по ним в базе данных. В примере задача с векторами на грани типичного хранения и обработки результатов работы нейросетевых моделей в базе данных.

Периодически сталкиваюсь с однотипными задачами вида "показать TOP-N позиций на каждом из вложенных интервалов некоторого периода".
Это может быть "5 лучших по успеваемости студентов в каждом семестре за последний учебный год", или "помесячная динамика позиции 10 наиболее продающихся товаров", или, как у нас в сервисе визуализации PostgreSQL-планов explain.tensor.ru, "3 наиболее активных страны за каждый день":

Когда выбираешь дом с учетом благополучия ребенка и жизни семьи с ним ближайшие 20 лет, лучше жить в пешеходной доступности от детсада, школы, коледжа и университета. Было бы хорошо чтобы поблизости были кружки детского творчества, спортцентры, школы иностранных языков. Ну и отлично, когда рядом есть игровые площадки и поликлиники - жилье ведь выбирают не на пару лет.
Мой рейтинг домов будет основан только на количественных метриках пешеходной доступности. Все расчеты основаны на данных проекта OpenStreetMap для жилых домов, которые ближе 2км пешком от входа в метрополитен или МЦК, а это значит что у этих домов нет проблем с транспортной доступностью. Рассчитаем самые удобные дома для жизни с детьми в районах Москвы.

Чтобы система долго работала без сбоев и перерывов, нужно поработать над отказоустойчивостью. В статье дадим несколько способов её построить и покажем готовое решение.
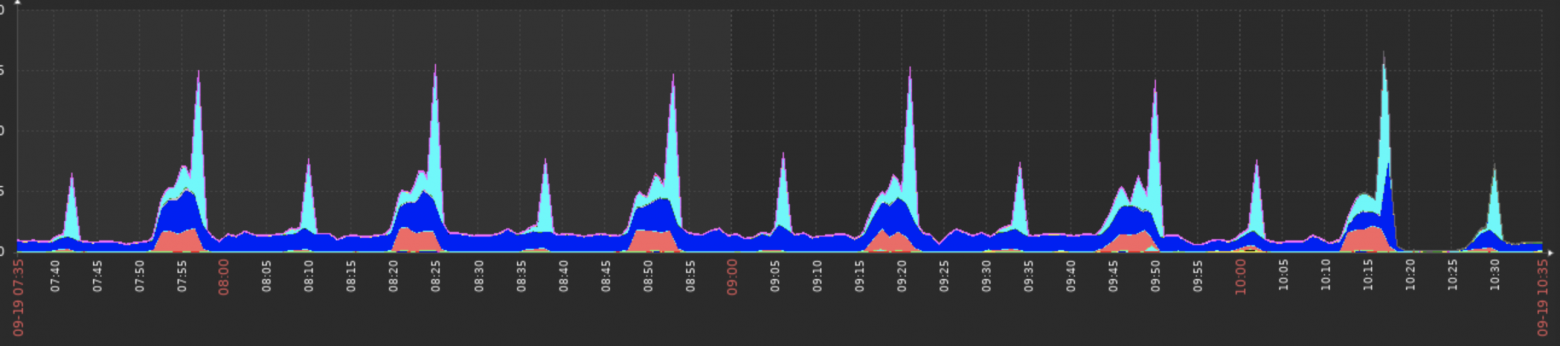
Я хочу поделиться своим опытом использования Zabbix для анализа проблем с производительностью PostgreSQL, используя расширение pg_stat_statements.
Исходя из того, что предыдущую статью не заминусовали и даже не сильно критиковали, попробую продолжить серию и поделиться с проблемами некоторых различий типов данных в MS SQL и PostgreSQL.

Привет, Habr! Меня зовут Оля Плюта, я продуктовый аналитик маркетплейса Uzum Market. В этой статье я расскажу об иерархических деревьях ltree в PostgreSQL. Статья вводная, поэтому я постаралась сделать её максимально понятной и наглядной.

- а также PostgreSQL 15.5, 14.10, 13.13, 12.17 и 11.22 (эта версия последняя, которая будет поддерживаться в линейке 11). Обновление закрывает 3 проблемы безопасности:
CVE-2023-5868: показ содержимого памяти в вызовах функций с агрегацией (memory disclosure in aggregate function calls) - может произойти, когда в качестве аргумента передаётся тип unknown;
CVE-2023-5869: переписывание буфера от его переполнения целыми при модификации массивов (buffer overrun from integer overflow in array modification) - недостаточные проверки переполнения позволяют аутентифицированным пользователям и читать в памяти и записывать в неё, чтобы исполнить вредоносный код;
CVE-2023-5870: роль pg_cancel_backend может рассылать сигналы некоторым процессам суперпользователей (role pg_cancel_backend can signal certain superuser processes) - а по документации не должна; роль может, например, посылать сигналы процессу, запускающему логическую репликацию.
Кроме того были ликвидированы баги - 55 штук. А теперь перейдём конференциям, по ним накопилась информация.
PostgreSQL 17: Часть 2 или Коммитфест 2023-09
Если новости о 16-й версии у кого-то уже не вбрасывают адреналин в кровь, то вот очередная статья-обзор Павла Лузанова, небольшое путешествие в будущее (а об июльском коммитфесте в предыдущей статье этой серии: 2023-07). Павел рассматривает 18 пунктов. Например:

Не секрет, что работа с часовыми поясами — боль, и многие разработчики объяснимо стараются ее избегать. Тем более что в каждом языке программирования / СУБД работа с часовыми поясами реализована по-разному.
Среди тех, кто работает с PostgreSQL, есть очень распространенное заблуждение про типы данных timestamp (который также именуется timestamp without time zone) и timestamptz (или timestamp with time zone). Вкратце его можно сформулировать так:
Мне не нужен тип timestamp with time zone, т.к. у меня все находится в одном часовом поясе — и сервер, и клиенты.
В статье я постараюсь объяснить, почему даже в таком довольно простом сценарии можно запросто напороться на проблемы. А в более сложных (которые на самом деле чаще встречаются на практике, чем может показаться) баги при использовании timestamp практически гарантированы.

Привет, Хабр! Меня зовут Евгений Кузьмин, я Java‑разработчик в CDEK. Надеюсь, все знают, что это за компания и чем занимается. Давайте представим, что вам нужно отправить посылку с гостинцами родственнику в Москву из Новосибирска. Вы приходите в ближайший пункт приёма посылок и оформляете услугу доставки. Что же происходит дальше? Казалось бы, всё очевидно: посылка сразу летит или едет из Новосибирска в Москву. Но всё не так просто...
Думаю, все согласятся, что не рационально гнать отдельную фуру с одной коробочкой для каждого заказа. Наша задача выстроить логистику таким образом, чтобы по пути загрузить и выгрузить как можно больше посылок и поехать дальше. В этой статье я поделюсь с своим опытом оптимизации задачи по редактированию и поддержке в актуальном состоянии огромного количества данных типа «куда направить товар». Классическая задача программирования на практике логистики. При этом мы не будем выходить за рамки стандартного стека Java Springboot и Postgres. Статья будет полезна разработчикам (от джуна до сеньора), которым интересно погрузиться в трудовые будни разработчика в сфере транспортной логистики.
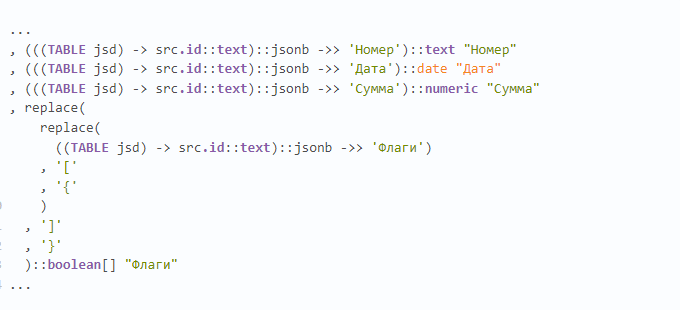
Недавно попался на глаза примерно такой кусок запроса, и тут прекрасно примерно все:
• множество чтений из CTE (хоть и единственной записи, но все же);
• извлечение по каждому ключу текста с раскастовкой в jsonb;
• извлечение каждого отдельного json-ключа в каждое отдельное одноименное поле;
• "ручное" преобразование текстового представления массива в json в текстовое представление PostgreSQL.
А как - правильно?

Приятно когда живешь там где у тебя вход в метро в 15 минутах ходьбы и с комфортом жизни неплохо. Но кушать хочется всегда, а на рабочей неделе уж совсем нет времени и желания ехать в супермаркет чтобы сварить гречневую кашу и взять что-нибудь на завтрак. Магазины шаговой доступности есть везде, но мне хотелось бы чтобы это было что-нибудь более привычное, типа Пятёрочки, Дикси, Магнита, Перекрёстка, Магнолии, Атак или Ленты.

Мне подавать заявку на Премию Highload++ не пришлось. Тогда организаторы и сообщество сами выбирали наиболее влиятельных в сообществе людей. Мне просто сообщили, что наградят и позвали на церемонию.
Я горжусь тем, что у нас в России очень хорошее Postgres сообщество, и что сам активно участвовал в его создании. Люди это отметили и это очень приятно.
