
Плюс, или как я соцсеть делал
Простой
3 мин
Кейс

История о том, как я создал свою соцсеть. И у меня даже получилось что-то. Видеохостинг, мессенджер, короткие ролики, стена и многое другое
История о том, как я создал свою соцсеть. И у меня даже получилось что-то. Видеохостинг, мессенджер, короткие ролики, стена и многое другое
Всем привет! В этой статье расскажу про свои ошибки и новшества во время работы над проектом, а точнее его улучшением. Эта статья является продолжением серии статей про данный проект.
Речь пойдет о моем проекте edge-weather-forecast — лёгкой нейросетевой модели прогнозирования температуры, которую можно запускать прямо на метеостанции или на простом CPU-устройстве вроде Raspberry Pi.
Привет, Хабр!
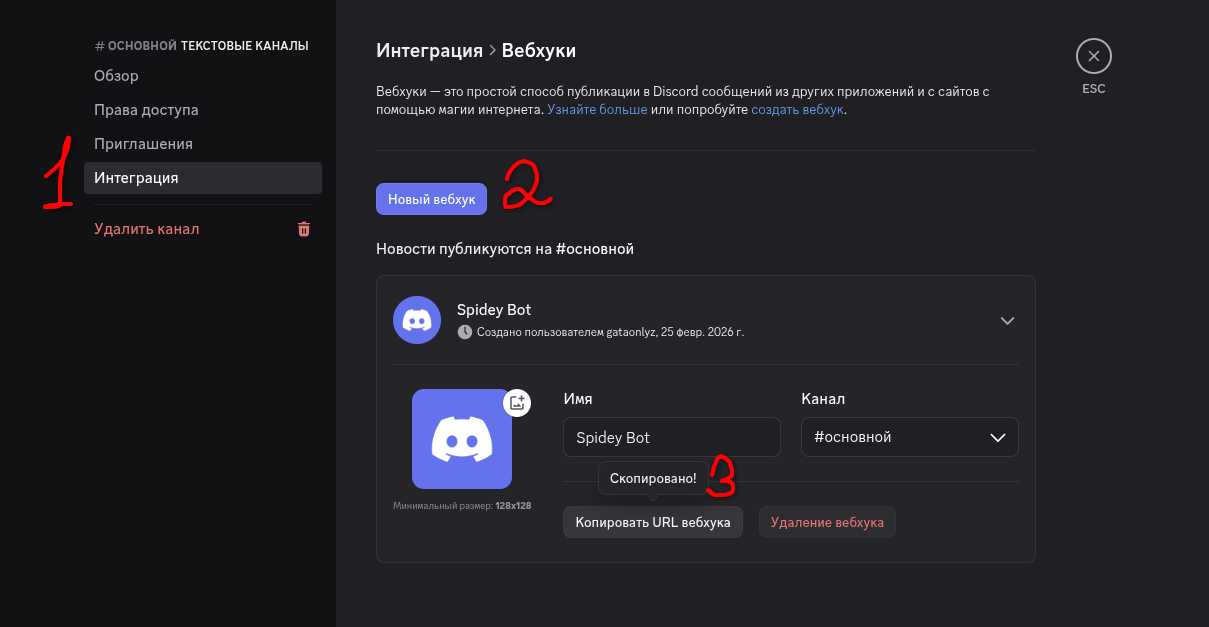
Если вас заинтересовал заголовок, то вы, скорее всего, уже знакомы с разработкой Telegram или Discord-ботов. И что также вероятно: для получения обновлений вы используете обычный polling. Сегодня же я вам предлагаю ознакомиться с другим способом получения обновлений - через webhook.

В «городском каньоне» GPS-сигнал подвержен эффектам многолучевого распространения и экранирования, что порождает аномалии в измерениях псевдодальности.
Классические фильтры Калмана, предполагающие аддитивный гауссовский шум, в таких условиях демонстрируют резкое падение точности оценки позиционирования.
В статье сравниваются два нелинейных фильтра Калмана:
 классический Fusion UKF (централизованный мультисенсорный UKF с фиксированной гауссовской моделью шума) мультисенсорный Variational Bayes Fusion UKF, в котором шум измерений моделируется распределением Стьюдента через вариационное байесовское приближение, а итеративная оценка скрытой масштабирующей переменной позволяет автоматически подавлять аномальные GPS-измерения.
классический Fusion UKF (централизованный мультисенсорный UKF с фиксированной гауссовской моделью шума) мультисенсорный Variational Bayes Fusion UKF, в котором шум измерений моделируется распределением Стьюдента через вариационное байесовское приближение, а итеративная оценка скрытой масштабирующей переменной позволяет автоматически подавлять аномальные GPS-измерения.
В сценариях с имитацией GPS-аномалий по типу городского каньона Variational Bayes Fusion UKF более чем вдвое превзошёл Fusion UKF по RMSE позиционирования.

Смотрю на вас как в зеркало... но в ответ не тронь, мы не для таких как ты, правда? Да мы не для таких, мы были созданы для настоящих мужиков. Когда одухотворяют неживые вещи для общения с ними это Антропоморфизм, а как называется когда человек с головой другого человека не разговаривает, но одушевляет части его тела, для общения с ними? Хм, ну да ладно от вымысла к реальности, а реальность у нас - 5ая статья в серии Шампур-Скребок выходит в публичное пространство. Route Load bot (телеграмм) для укладки груза.

Привет, Хабр. В перформанс-маркетинге обычно обучают кампании по начальным событиям в воронке вроде заявки. Для алгоритма это считается конверсией, но для бизнеса важнее сделка. В итоге до сделки и оплаты доходит только часть лидов, но для алгоритма они одинаковые, и автостратегия продолжает искать и тех, кто не конвертируется в оплату, и тех, кто оплачивает.
Чтобы алгоритм работал лучше и искал только тех, кто вероятнее готов к сделке, между собой связываются рекламное объявление, звонок и итоговая сделка. Для этого в Яндекс через офлайн-события возвращается звонок или уже факт сделки.
В этом гайде разберём MVP на Python: он добавляет номер на лендинге под yclid, хранит выдачу в SQLite, принимает вебхук звонка от МТС Exolve, создаёт конверсию и формирует CSV под импорт в Яндекс.Метрику. Получается повторяемый поток данных от рекламного клика до офлайн-цели без ручной склейки.
В конце статьи у вас будет рабочий сценарий запуска, тестовые запросы и список технических доработок для боевого контура.

Привет, сообществу Habr!
Хочу поделиться опытом с коллегами - как мы решили одну из наболевших проблем нашей команды разработки – отсутствие полноты данных для тестирования реализованного функционала в условиях ограниченного доступа к реальным данным компании. Если вы работаете с персональными данными, то наверняка сталкивались с такой проблемой.
Наша команда Neoflex работает на проектах заказчика. При старте работ мы всегда подписываем NDA, но все равно этого недостаточно, чтобы владелец доверил нам полный доступ к промышленным данным. Мы его прекрасно понимаем: данные - основа благополучия компании и видеть их должен ограниченный круг лиц, отвечающий за бизнес-результат.
Чтобы удовлетворить ожидания заказчика, выполнить вверенную нам работу и достичь высоких результатов при разработке функционала, нам нужны данные для тестирования, близкие к реальным. Тут возникает сложность – на тестовом контуре либо небольшой срез не консистентных промышленных данных, на которых нельзя протестировать полноценно функционал (например, витрину по операциям определенного сегмента клиентов с глубиной месяц, квартал), либо мы начинаем генерировать синтетику, не всегда попадая в нюансы вариативности данных, тратя на это дополнительные ресурсы.
Периодически наши члены команды на ретроспективе, разбирая проблемный кейс, обсуждали свою боль – нужен тестовый контур для тестирования с достаточным количеством данных, близких к бизнесовым, обновляемый по расписанию - иначе мы можем выкатить на прод слабо оттестированный функционал.

Когда строим бэкенд по DDD и CQRS, роуты и OpenAPI обычно собираем вручную. Urich делает иначе: описываешь ограниченный контекст одним объектом — маршруты и документация появляются сами. Обзор фреймворка на Starlette и примеры кода.

В работе с системами управления идентификацией, такими как ALD PRO (решение на базе FreeIPA), администраторы часто сталкиваются с рутинными операциями, которые в веб-интерфейсе выполняются долго и не поддаются автоматизации. Одна из таких задач — массовое создание и клонирование ролей с сохранением политик и привилегий.
Я хотел решить именно эту проблему: быстро копировать существующие роли в ALD PRO для новых организационных подразделений (OU), сохраняя все настройки и права. Веб-интерфейс не позволял делать это быстро, а главное — не давал возможности интегрироваться с системами автоматизации.
В этой статье я расскажу о четырёх этапах эволюции решения и базовых принципах для написания своих собственных плагинов для ваших решений.

В этой статье будет рассказано о популярных метриках оценки для задач генерации текста: BLEU, ROUGE, METEOR, BERTScore. Рассказ будет сопровождаться визуализацией, примерами и кодом на Python.

В области объяснимого искусственного интеллекта (Explainable AI, XAI) метод SHAP (SHapley Additive exPlanations), опирающийся на прочную теоретическую базу теории игр, стал ключевым методом оценки важности признаков. Для простых задач классификации сообщество располагает обширной документацией и учебными материалами, что позволяет разработчикам легко создавать графики-водопады (Waterfall Plot) или графики-пчелиный рой (Beeswarm Plot) для объяснения прогнозов модели.
Однако при работе с многоклассовой классификацией (Multi-class Classification) применение SHAP претерпевает изменения. Из-за изменения размерности выходных данных прямое использование стандартного кода часто приводит к ошибкам размерности или неверной интерпретации.
В данной статье рассматриваются технические трудности применения SHAP в задачах многоклассовой классификации и предлагается проверенное решение для визуализации на Python. Материал основан на новейшем исследовании, опубликованном в 2025 году в журнале Measurement (статья под названием Thermodynamic simulation-assisted random forest: Towards explainable fault diagnosis of combustion chamber components of marine diesel engines), в котором реализована визуализация объяснимой диагностики неисправностей для многоклассовой задачи (вычисление SHAP для 14 категорий в пяти состояниях неисправности).

Пятая статья цикла о построении CDC-пайплайна с нуля. HDFS и Hive работают, но управлять ими через консоль неудобно. Сегодня поднимаем веб-интерфейс Hue и разбираемся, почему в 2026 году сборка из исходников требует Python 2.7.

Рекомендация по КДПВ:
Практический гайд по созданию Telegram-бота для автоматизированного анализа сайта: broken links, базовый security-check, отчёты. Минимум теории — максимум рабочего кода.

Поиск аномалий под микроскопом: от базовой статистики до робастных моделей с нуля на NumPy В машинном обучении поиск аномалий (Anomaly Detection) часто остается в тени классического обучения с учителем. Однако именно эта «иммунная система» данных спасает миллионы долларов в финтехе, предотвращает катастрофы на производстве и находит критические ошибки в медицинских картах.
В этой статье мы не просто импортируем готовые методы из sklearn. Мы разберем математическую логику трех мощных подходов, напишем их «примитивные» реализации на NumPy/Pandas, чтобы понять механику работы «под капотом», и проверим их в деле на реальном кейсе.
Наш полигон: Credit Card Fraud Detection
Для тестов мы возьмем классический датасет Credit Card Fraud Detection. Это идеальный пример «иголки в стоге сена»: здесь всего 0.17% мошеннических транзакций среди почти 300 тысяч записей. Смогут ли наши рукотворные алгоритмы их найти?
Эволюция методов: от простого к сложному
Мы пройдем путь от элементарной статистики до продвинутого геометрического анализа:
IQR (Interquartile Range): Статистическая классика. Узнаем, как «усы» боксплота помогают находить грубые выбросы.
Isolation Forest: Оригинальный подход, основанный на идее, что аномалию проще всего «изолировать» случайными разрезами пространства.
Elliptic Envelope: Тяжелая артиллерия робастной статистики. Будем строить многомерный эллипс, который игнорирует попытки аномалий исказить его форму.

Тест LLM‑модели qwen3‑coder‑next:q8_0: модель успешно построила карту большого форума, собрала все сообщения в JSON и преобразовала их в готовый SQL‑дайджест, показав высокое качество генерации кода, но «залипла» при решении чисто логической задачи.

Много раз проскакивало желание у многих получить простой инструмент, позволяющий следить за истекающими сертификатами SSL. Ниже представляю инструмент для самостоятельного развертывания в среде docker.
Код написан для python14, но работать будет и на других версиях (12, 13, 14 и т.д.).
Что включает проект (все в одном):

Пролог: Почему бизнесу нужна эволюция, а не революция
Представьте сцену: Вы запускаете первый ИИ-агент для поддержки клиентов. Первые две недели — восторг. "Он отвечает! Он работает!" Месяц спустя — разочарование. "Он повторяет одни и те же ошибки. Не умеет работать со сложными запросами. Требует постоянного контроля".
Знакомо? Это классическая история "пилотного проекта, который не масштабируется".
Моя команда прошла этот путь. Мы потратили 18 месяцев на эволюцию от примитивного бота до системы, которая:
Самостоятельно обрабатывает 85% сложных запросов
Снизила операционные затраты на 40%
Еженедельно улучшает свои показатели на 3-5% без вмешательства разработчиков
В этой статье я покажу конкретные шаги этой эволюции с кодом, схемами и бизнес-обоснованиями. Вы узнаете не "как сделать крутого ИИ", а "как построить систему, которая сама становится круче".
Всем привет! Хочу рассказать не столько про свою модель, сколько про инженерные компромиссы, с которыми я столкнулся во время работы над проектом. Буду рад любой критике.
Речь пойдет о моем проекте edge-weather-forecast — лёгкой нейросетевой модели прогнозирования температуры, которую можно запускать прямо на метеостанции или на простом CPU-устройстве вроде Raspberry Pi.

Решил немного изучить рынок аренды жилья в городе Санкт-Петербург.
Что сейчас по ценам, где и какие квартиры дешевле или дороже?
Данные: ЦИАН, 7 038 объявлений (цены предложения, не сделки). База - медиана, чтобы не искажаться хвостом.
В итоге собрал вот такой PDF-отчет за январь 2026 (яндекс диск).

В момент выхода протокола MCP нас очень заинтересовали его возможности. Нам хотелось использовать этот протокол для того, чтобы внутренние пользователи могли обращаться к базе данных в свободной форме и получать данные в течение нескольких минут. MCP для этого выглядел очень хорошо: пользователь может сформировать запрос на удобном для него языке, а LLM поймет, что нужно сделать и сделает это.
На первый взгляд MCP в связке с LLM полностью закрывал данные проблемы, однако с ростом объема данных стало заметно, что LLM не удается обрабатывать их быстро и качественно, а написание SQL запросов для нее не всегда легкая задача (даже если примеры этих запросов у нее есть в промпте). В итоге мы получили потерю контроля над контекстом модели и непредсказуемый результат.
В этой части я расскажу про интеграцию с Open WebUI и какая архитектура модели позволила победить вышеуказанные проблемы. Следующие статьи расскажут о реализации MCP таким, каким он позволяет выполнять наши задачи (но не финальной версии). Эта статья может быть полезна всем, кто строит свои модели на основе Open WebUI или еще только выбирает фреймворк, на котором предстоит строить будущую модель