Прим. перев.: Статья написана Javier Salmeron — инженером из хорошо известной в Kubernetes-сообществе компании Bitnami — и была опубликована в блоге CNCF в начале августа. Автор рассказывает о самых основах механизма RBAC (управление доступом на основе ролей), появившегося в Kubernetes полтора года назад. Материал будет особенно полезным для тех, кто знакомится с устройством ключевых компонентов K8s (ссылки на другие подобные статьи см. в конце).
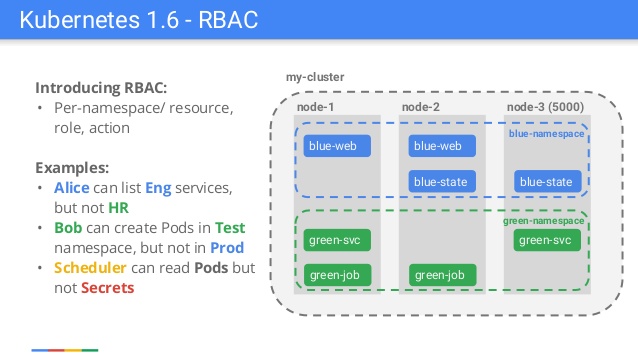
Слайд из презентации, сделанной сотрудником Google по случаю релиза Kubernetes 1.6
Многие опытные пользователи Kubernetes могут вспомнить релиз Kubernetes 1.6, когда авторизация на основе Role-Based Access Control (RBAC) получила статус бета-версии. Так появился альтернативный механизм аутентификации, который дополнил уже существующий, но трудный в управлении и понимании, — Attribute-Based Access Control (ABAC). Все с восторгом приветствовали новую фичу, однако в то же время бесчисленное число пользователей были разочарованы. StackOverflow и GitHub изобиловали сообщениями об ограничениях RBAC, потому что большая часть документации и примеров не учитывали RBAC (но сейчас уже всё в порядке). Эталонным примером стал Helm: простой запуск
Слайд из презентации, сделанной сотрудником Google по случаю релиза Kubernetes 1.6
Многие опытные пользователи Kubernetes могут вспомнить релиз Kubernetes 1.6, когда авторизация на основе Role-Based Access Control (RBAC) получила статус бета-версии. Так появился альтернативный механизм аутентификации, который дополнил уже существующий, но трудный в управлении и понимании, — Attribute-Based Access Control (ABAC). Все с восторгом приветствовали новую фичу, однако в то же время бесчисленное число пользователей были разочарованы. StackOverflow и GitHub изобиловали сообщениями об ограничениях RBAC, потому что большая часть документации и примеров не учитывали RBAC (но сейчас уже всё в порядке). Эталонным примером стал Helm: простой запуск
helm init + helm install больше не работал. Внезапно нам потребовалось добавлять «странные» элементы вроде ServiceAccounts или RoleBindings ещё до того, как разворачивать чарт с WordPress или Redis (подробнее об этом см. в инструкции).