Начиналось всё с системника в общаге МГУ и обычного хостинга, на котором размещалось наше расписание электричек, которое многие из вас видели. И перекладывания файлов по ночам, чтобы уложиться в лимиты нагрузки. Потом появились первые сервера. Они получали тройной трафик на майские, отчего сразу ложились. Точнее, мы не знаем, какой трафик они получали, потому что ложились именно на тройном от обычного.

Оглядываясь назад, могу сказать, что все действия по размещению с тех пор — это вынужденные ходы. И вот только сейчас на пятнадцатый год мы можем настраивать инфраструктуру так, как нужно нам.
Сейчас мы стоим в 4 физически разных ЦОДах, соединённых кольцом тёмной оптики, размещая там 5 независимых пулов ресурсов. И так получилось, что если в одну из кроссовых попадёт метеорит, то у нас тут же отвалится 3 этих пула, а оставшиеся два не потянут нагрузку. Поэтому мы занялись полной ребалансировкой, чтобы навести порядок.




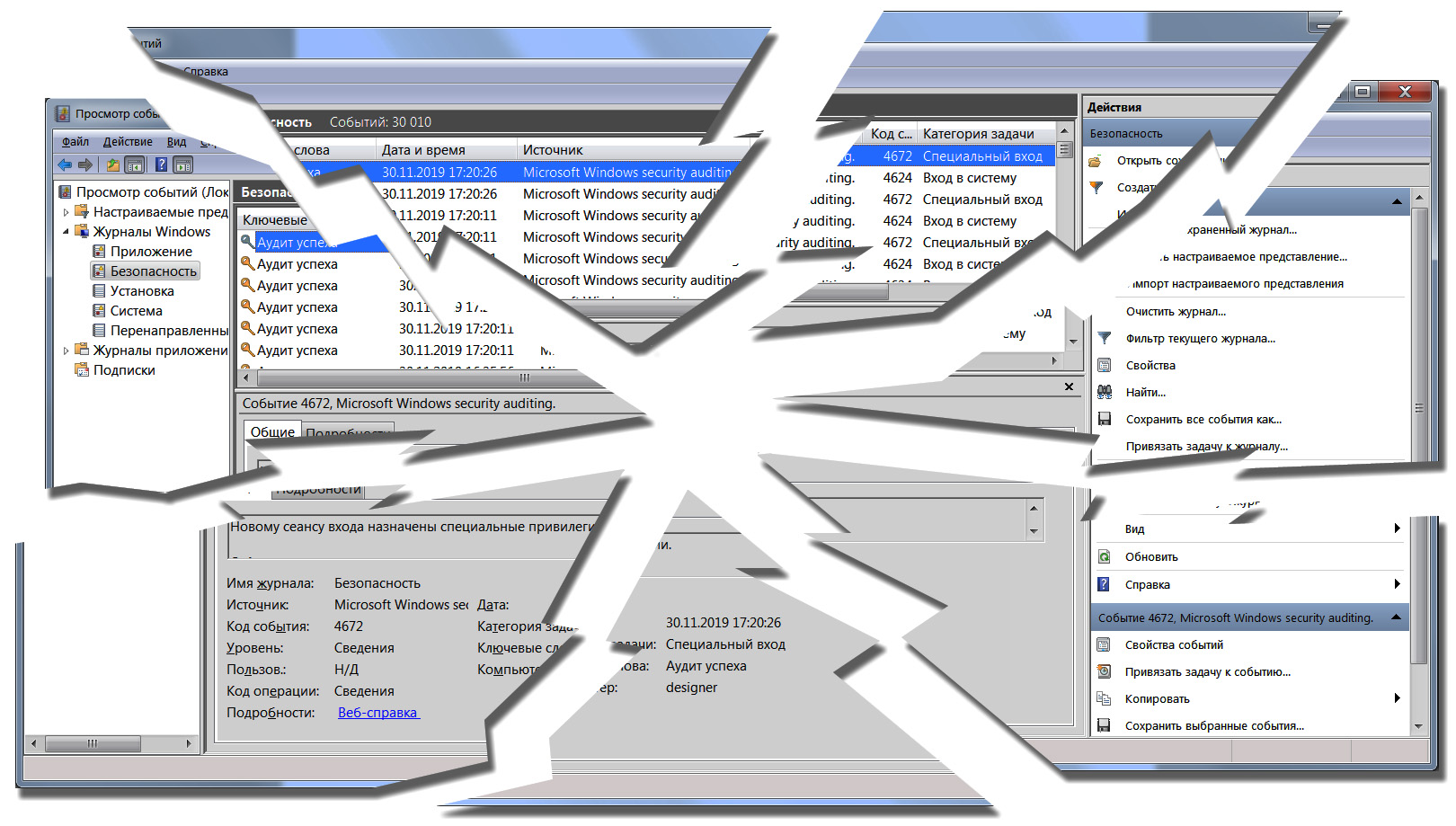
 Если Вам приходилось когда-нибудь пользоваться веб-интерфейсами для просмотра логов, то Вы наверняка замечали, насколько, как правило, эти интерфейсы громоздки и (зачастую) не слишком-то удобны и отзывчивы. К некоторым можно привыкнуть, некоторые совсем ужасны, но, как мне кажется, причина всех проблем заключается в том, что мы неправильно подходим к задаче просмотра логов: мы пытаемся создать веб-интерфейс там, где лучше работает CLI (интерфейс командной строки). Мне лично очень комфортно работать с tail, grep, awk и прочими, и поэтому для меня идеальным интерфейсом для работы с логами было бы что-то аналогичное tail и grep, но которое при этом можно было использовать для чтения логов, которые пришли с множества серверов. То есть, конечно же, читать их из ClickHouse!
Если Вам приходилось когда-нибудь пользоваться веб-интерфейсами для просмотра логов, то Вы наверняка замечали, насколько, как правило, эти интерфейсы громоздки и (зачастую) не слишком-то удобны и отзывчивы. К некоторым можно привыкнуть, некоторые совсем ужасны, но, как мне кажется, причина всех проблем заключается в том, что мы неправильно подходим к задаче просмотра логов: мы пытаемся создать веб-интерфейс там, где лучше работает CLI (интерфейс командной строки). Мне лично очень комфортно работать с tail, grep, awk и прочими, и поэтому для меня идеальным интерфейсом для работы с логами было бы что-то аналогичное tail и grep, но которое при этом можно было использовать для чтения логов, которые пришли с множества серверов. То есть, конечно же, читать их из ClickHouse!