
ApexSQL — это комплексный набор инструментов, который оптимизирует и автоматизирует процессы управления базами данных SQL Server и разработки, а также обеспечивает безопасность и соответствие требованиям. В одной из прошлых статей мы описывали бесплатные и платные инструменты ApexSQL (там и правда есть из чего выбрать).
Приглашаем вас зарегистрироваться на вебинар, который состоится 19 мая в 11 часов утра по московскому времени. Вы узнаете о линейке решений ApexSQL, бесплатных и платных возможностях продуктов, подходе к лицензированию, а также сможете задать вопросы.
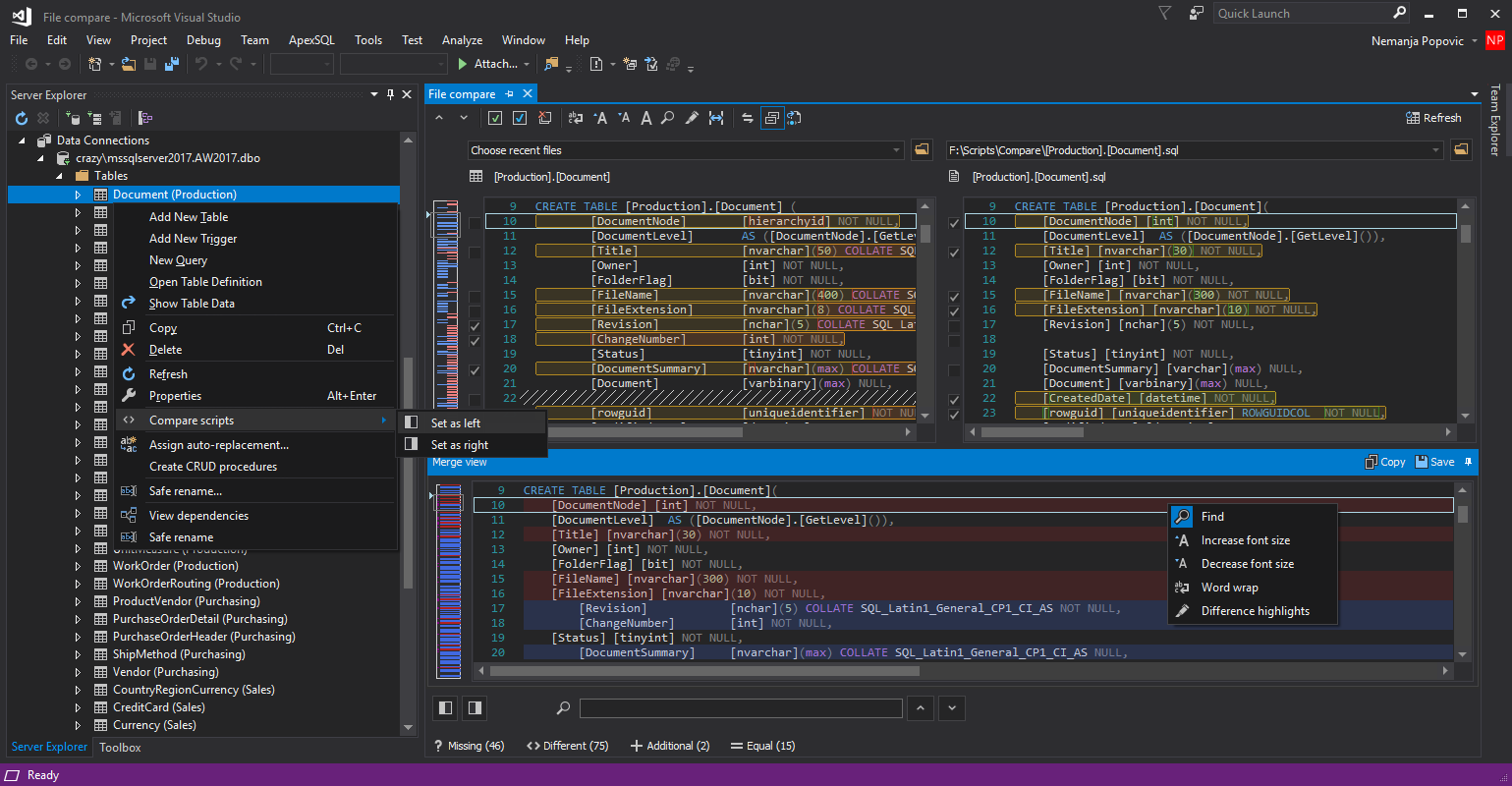
Под катом список решений ApexSQL с кратким описанием и ссылками на соответствующие страницы на сайте вендора.
Приглашаем вас зарегистрироваться на вебинар, который состоится 19 мая в 11 часов утра по московскому времени. Вы узнаете о линейке решений ApexSQL, бесплатных и платных возможностях продуктов, подходе к лицензированию, а также сможете задать вопросы.
Под катом список решений ApexSQL с кратким описанием и ссылками на соответствующие страницы на сайте вендора.



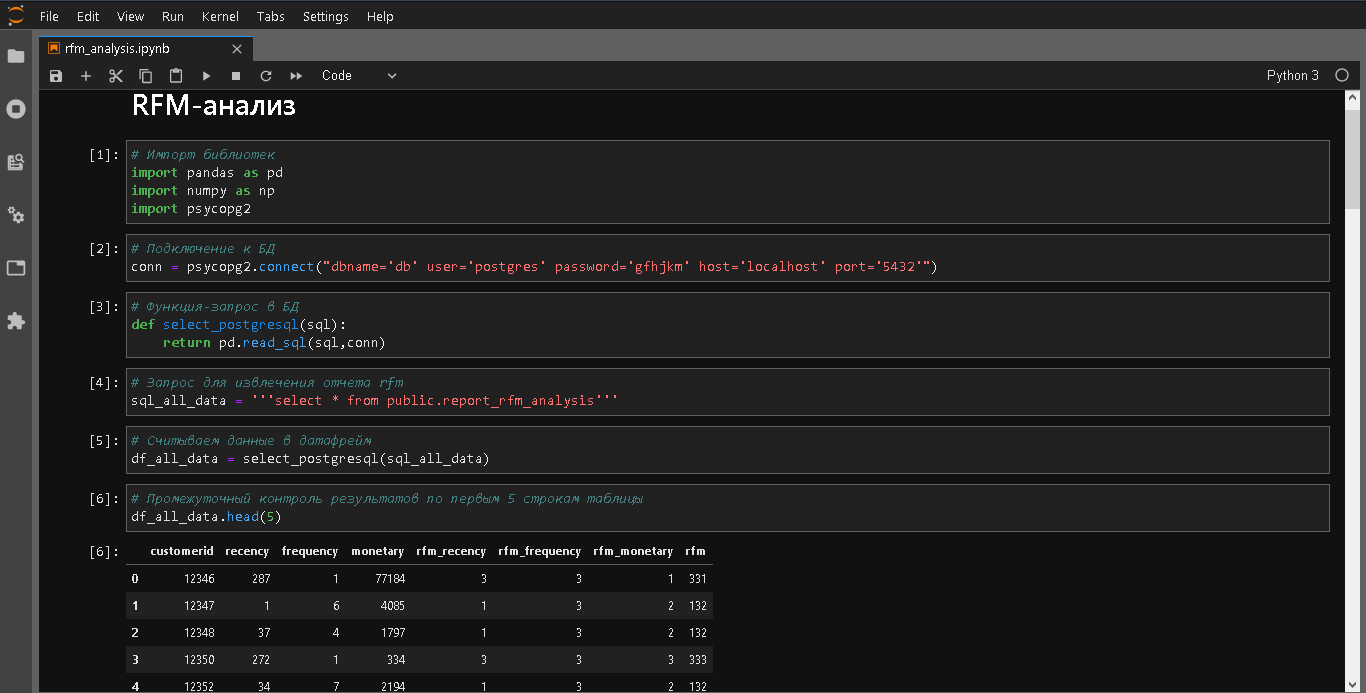




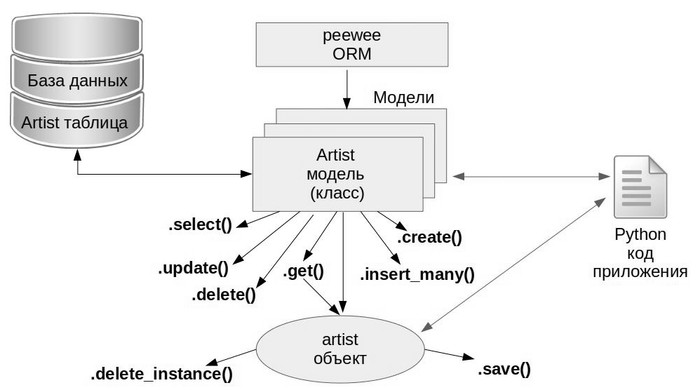
 Язык структурированных запросов (SQL) является незаменимым навыком в индустрии информатики, и вообще говоря, изучение этого навыка относительно просто. Однако большинство забывают, что SQL — это не только написание запросов, это всего лишь первый шаг дальше по дороге. Обеспечение производительности запросов или их соответствия контексту, в котором вы работаете, — это совсем другая вещь.
Язык структурированных запросов (SQL) является незаменимым навыком в индустрии информатики, и вообще говоря, изучение этого навыка относительно просто. Однако большинство забывают, что SQL — это не только написание запросов, это всего лишь первый шаг дальше по дороге. Обеспечение производительности запросов или их соответствия контексту, в котором вы работаете, — это совсем другая вещь. Добрый день, статья написана в качестве некоего продолжения
Добрый день, статья написана в качестве некоего продолжения 