Строгое определение понятий: объект, состояние, событие, бизнес-операция и бизнес- функция
11 мин
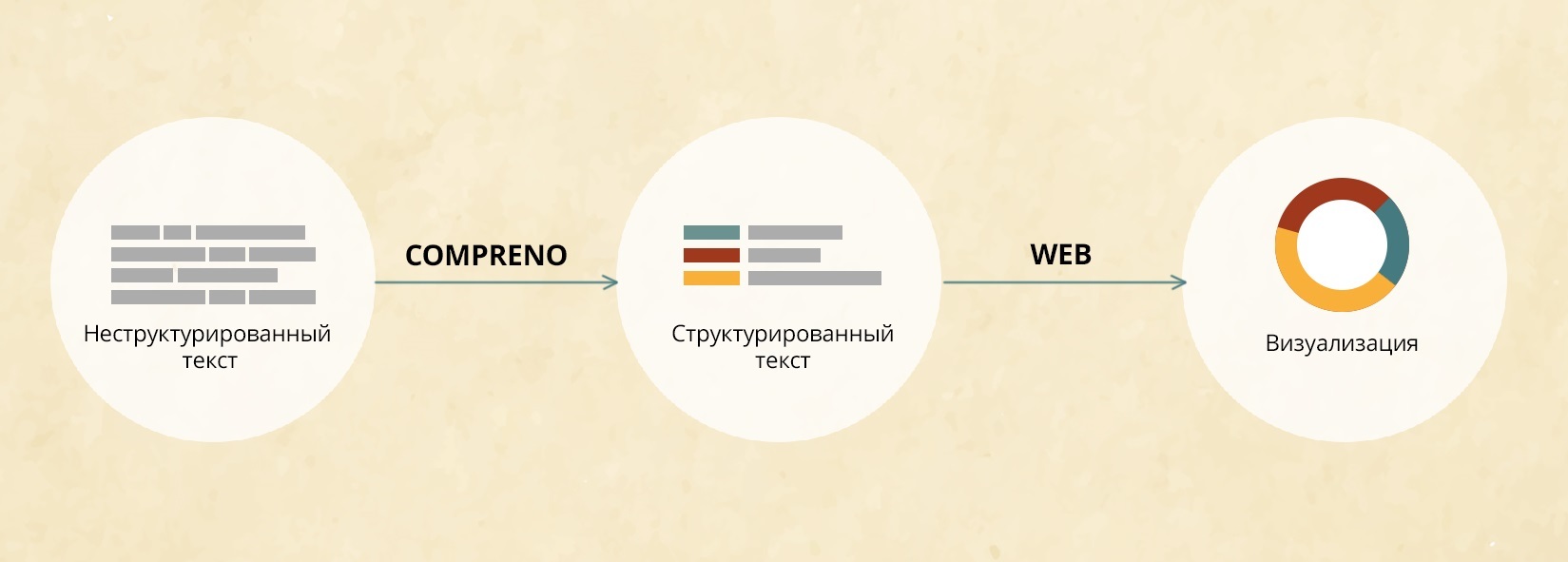
В текущей статье я определю следующие термины: объект, состояние, событие, операция, функция. Я расскажу о том, как можно представить себе их. В качестве мета-метамодели для моделирования мы возьмем теорию множеств, а не MOF. Почему именно ее? Потому что это единственный на сегодняшний день известный способ моделирования, который имеет математическую основу, границы применимости которого нам хорошо известны, достаточно широки и обоснованы.
Прошлые статьи вызвали оживленную дискуссию среди тех, кто использует для моделирования предметных областей инструменты ООП: языки ООП, нотацию UML. Несмотря на то, что я постоянно подчеркиваю, что объекты учета, о которых я веду речь, не моделируются средствами UML, и объясняю почему, тем не менее, вопрос об их моделировании методами ООП поднимается снова и снова. Наверно, мне надо еще раз рассказать, чем так плох ООП для моделирования предметных областей.
Прошлые статьи вызвали оживленную дискуссию среди тех, кто использует для моделирования предметных областей инструменты ООП: языки ООП, нотацию UML. Несмотря на то, что я постоянно подчеркиваю, что объекты учета, о которых я веду речь, не моделируются средствами UML, и объясняю почему, тем не менее, вопрос об их моделировании методами ООП поднимается снова и снова. Наверно, мне надо еще раз рассказать, чем так плох ООП для моделирования предметных областей.