
Обзор примитивов синхронизации — Семафор и немного lockless-а
6 мин
В прошлой заметке мы обсудили самую известную пару из лагеря инструментов синхронизации тредов — mutex и cond. Сегодня встретимся с sema — примитивом, который умеет заменять предыдущие два в одиночку.
Но сначала — пара слов о случайных пробуждениях. (Спасибо xaizek, который мне об этом напомнил.) В принципе, строго реализованные механизмы синхронизации этим не страдают, но, тем не менее, опытный программист на это никогда не полагается.
Напомню фрагмент кода:
Здесь цикл вокруг wait_cond гарантирует нам, что даже если мы вернёмся из ожидания события случайно или по ошибке, ничего страшного не случится — проверка в while обеспечит нам уверенность, что нужное состояние проверяемого объекта достигнуто. Если нет — поспим ещё в ожидании.
Отметим ещё раз, что проверяем мы состояние объекта (total_free_mem <= 0) при запертом мьютексе, то есть никто не может его менять в то же самое время.
Но сначала — пара слов о случайных пробуждениях. (Спасибо xaizek, который мне об этом напомнил.) В принципе, строго реализованные механизмы синхронизации этим не страдают, но, тем не менее, опытный программист на это никогда не полагается.
Напомню фрагмент кода:
while(total_free_mem <= 0)
{
wait_cond(&got_free_mem, &allocator_mutex);
}
Здесь цикл вокруг wait_cond гарантирует нам, что даже если мы вернёмся из ожидания события случайно или по ошибке, ничего страшного не случится — проверка в while обеспечит нам уверенность, что нужное состояние проверяемого объекта достигнуто. Если нет — поспим ещё в ожидании.
Отметим ещё раз, что проверяем мы состояние объекта (total_free_mem <= 0) при запертом мьютексе, то есть никто не может его менять в то же самое время.


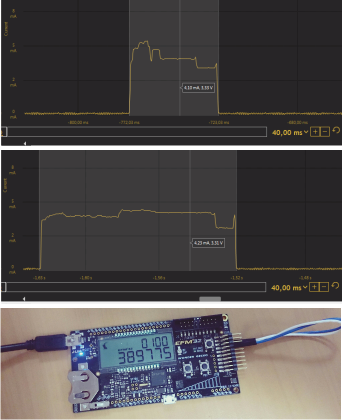 ARM Cortex-M3 — это, пожалуй, самое популярное на сегодняшний день 32-разрядное процессорное ядро для встраиваемых систем. Микроконтроллеры на его базе выпускают десятки производителей. Причина этому — универсальная, хорошо сбалансированная архитектура, а следствие — непрерывно растущая база готовых программных и аппаратных решений.
ARM Cortex-M3 — это, пожалуй, самое популярное на сегодняшний день 32-разрядное процессорное ядро для встраиваемых систем. Микроконтроллеры на его базе выпускают десятки производителей. Причина этому — универсальная, хорошо сбалансированная архитектура, а следствие — непрерывно растущая база готовых программных и аппаратных решений.




 2015 год был значительным годом для Rust: мы выпустили версию 1.0, стабилизировали большинство элементов языка и кучу библиотек, значительно выросли как сообщество, а также
2015 год был значительным годом для Rust: мы выпустили версию 1.0, стабилизировали большинство элементов языка и кучу библиотек, значительно выросли как сообщество, а также  Мы решили поздравить всех читателей блога с наступившим Новым годом и подвести итоги прошедшего. Конец 2015 года ознаменовался круглыми числами — 6000-й билд в SVN и 5000-й участник группы
Мы решили поздравить всех читателей блога с наступившим Новым годом и подвести итоги прошедшего. Конец 2015 года ознаменовался круглыми числами — 6000-й билд в SVN и 5000-й участник группы  Возможно, я скажу банальную вещь, но прошедший год был хорошим годом для С++!
Возможно, я скажу банальную вещь, но прошедший год был хорошим годом для С++! В прошлой
В прошлой