Теперь наш синтез на 22 языках с кириллицей и ещё в 4 раза быстрее
Средний
4 мин
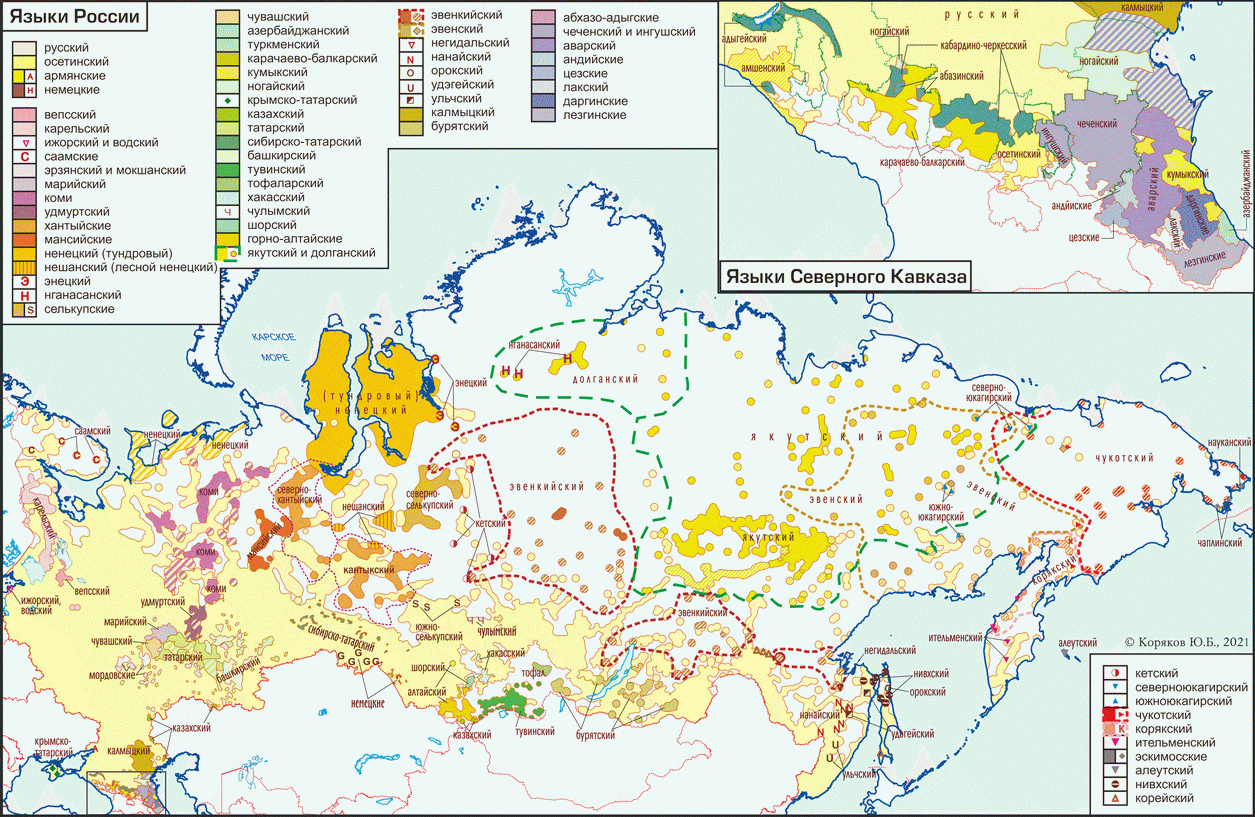
Источник карты — Проект «Языки России» Институт языкознания РАН, 2021 год
Давненько мы не выпускали новых статей про наш синтез речи! В прошлый раз мы добавили синтез на 9 языках народов Индии, существенно улучшили автоматическую простановку ударений, добавили 1 русский голос и "наследовали" SSML для всех моделей.
В этот раз мы сделали следующее:
- Ускорили все
v4модели в 3-4 раза; - Существенно повысили качество синтеза в 8 kHz;
- Обновили и пересобрали нашу модель для русского языка;
- Обновили модель для 9 языков народов Индии с 17 голосами;
- Добавили единую модель для 22 языков с кириллическим алфавитом с 31 голосом;
- Прекратили поддержку моделей романо-германских языков (старые модели будут доступны для скачивания без изменений);
- Обновили модели для языков народов СНГ: узбекского и украинского (татарский и калмыцкий были "поглощены" единой моделью);