Дело было на третьем курсе, появился у нас предмет ИИС (интеллектуальные информационные системы). Так как я давно интересовался распознаванием образов, удалось выпросить тему «распознавание рукописных цифр». Я решил не возиться с нейронными сетями и придумать что-то свое, простое, но достаточно эффективное.
Пожалуй, простейшим из алгоритмов распознавания символов является попиксельное сравнение рисунка с эталонными изображениями, вычисляется разница, тот образец, для которого она наименьшая считается верным ответом. При сравнении можно использовать различные ухищрения, например, применять для кластеризации потенциальные функции и расстояние Хэмминга. Недостатки данного метода: необходимость подготовки и хранения большого количества образцов (чем больше, тем лучше), плохая устойчивость к искажениям, сильная зависимость от используемого шрифта эталонных изображений.
Мне же пришла в голову мысль напрямую использовать статистику распределения закрашенных пикселей. Было решено использовать поле 20х30 пикселей, так как чем больше точек, тем меньше статистическая погрешность.
1. Определяются границы рисунка, вырезается прямоугольная область (чтобы отсечь пустые пиксели и уменьшить размерность рабочей матрицы).
2. Область делится крест накрест, на 4 части.
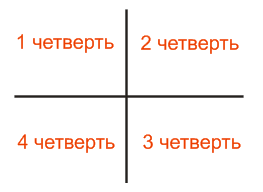
Для каждой четверти подсчитывается количество попавших в нее закрашенных пикселей, вычисляется доля относительно всего рисунка. Примерно как-то так:

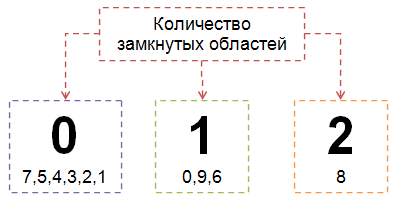
3. Для более высокой точности распознавания, исследуется топология. С помощью рекурсивной функции подсчитывается количество замкнутых областей. Если их две — это точно цифра 8. Если одна — 0, 6 или 9 (тут пойдет уточнение по четвертям). Если нет таких областей — это какая-то из остальных цифр.
4. Далее в дело вступает табличка, в которой заранее прописаны примерные распределения для каждой цифры, которые я рассчитал проведя небольшое исследование:
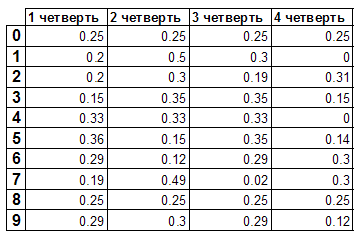
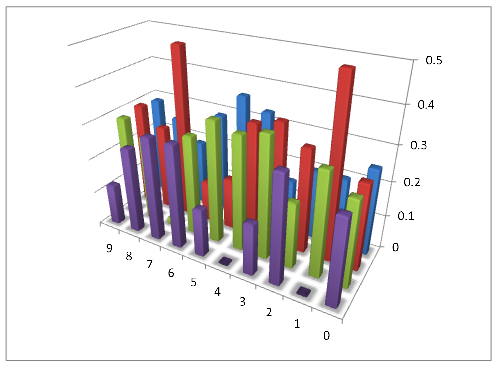
Для каждой цифры (строки) в таблице просчитывается суммарное отклонение, там, где оно минимально считаем, что эта цифра изображена на рисунке(конечно же учитывается топология, просчитанная на шаге 3, например, если обнаружена одна замкнутая область по таблице проверяются только 0, 6 и 9).
Вот, собственно, как выглядела программка в итоге:
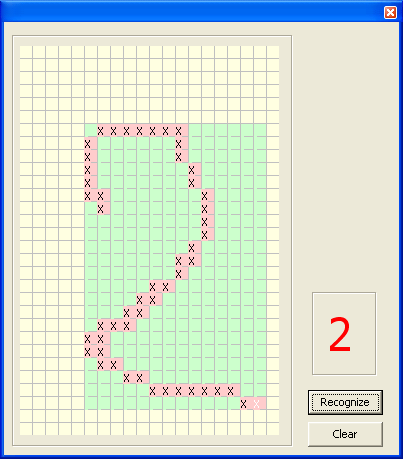
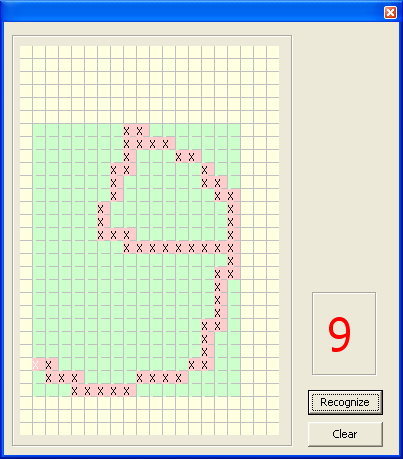
Метод может показаться слишком тупым, и тем не менее он работает! Если не стоит задачи обмануть алгоритм, процент верных распознаваний очень высок. В отличие от методов сравнения с эталоном, он более устойчив к вертикальному или горизонтальному растяжению, изменению толщины пера и не требует трансформации под размер эталонных изображений. Хотя при попытке сдать работу преподавателю, я был уничтожен его жутким почерком и желанием расколоть алгоритм, считаю, что для первого раза задача была решена (о чем намекает пятерка в зачетке:)
В дальнейшем лаба была переделана под нечеткую логику, потом под нейронные сети + ГА, но все это довольно сложно и не так элегантно.
Можете сами попробовать попробовать мое решение.
Пожалуй, простейшим из алгоритмов распознавания символов является попиксельное сравнение рисунка с эталонными изображениями, вычисляется разница, тот образец, для которого она наименьшая считается верным ответом. При сравнении можно использовать различные ухищрения, например, применять для кластеризации потенциальные функции и расстояние Хэмминга. Недостатки данного метода: необходимость подготовки и хранения большого количества образцов (чем больше, тем лучше), плохая устойчивость к искажениям, сильная зависимость от используемого шрифта эталонных изображений.
Мне же пришла в голову мысль напрямую использовать статистику распределения закрашенных пикселей. Было решено использовать поле 20х30 пикселей, так как чем больше точек, тем меньше статистическая погрешность.
Суть метода
1. Определяются границы рисунка, вырезается прямоугольная область (чтобы отсечь пустые пиксели и уменьшить размерность рабочей матрицы).
2. Область делится крест накрест, на 4 части.
Для каждой четверти подсчитывается количество попавших в нее закрашенных пикселей, вычисляется доля относительно всего рисунка. Примерно как-то так:
3. Для более высокой точности распознавания, исследуется топология. С помощью рекурсивной функции подсчитывается количество замкнутых областей. Если их две — это точно цифра 8. Если одна — 0, 6 или 9 (тут пойдет уточнение по четвертям). Если нет таких областей — это какая-то из остальных цифр.
4. Далее в дело вступает табличка, в которой заранее прописаны примерные распределения для каждой цифры, которые я рассчитал проведя небольшое исследование:
Для каждой цифры (строки) в таблице просчитывается суммарное отклонение, там, где оно минимально считаем, что эта цифра изображена на рисунке(конечно же учитывается топология, просчитанная на шаге 3, например, если обнаружена одна замкнутая область по таблице проверяются только 0, 6 и 9).
Программная реализация
Вот, собственно, как выглядела программка в итоге:
Выводы
Метод может показаться слишком тупым, и тем не менее он работает! Если не стоит задачи обмануть алгоритм, процент верных распознаваний очень высок. В отличие от методов сравнения с эталоном, он более устойчив к вертикальному или горизонтальному растяжению, изменению толщины пера и не требует трансформации под размер эталонных изображений. Хотя при попытке сдать работу преподавателю, я был уничтожен его жутким почерком и желанием расколоть алгоритм, считаю, что для первого раза задача была решена (о чем намекает пятерка в зачетке:)
В дальнейшем лаба была переделана под нечеткую логику, потом под нейронные сети + ГА, но все это довольно сложно и не так элегантно.
Можете сами попробовать попробовать мое решение.
