Возможно, это странно, но в первые дни на работе после новогодних каникул, когда все упавшее за праздники уже успешно возвращено к жизни, у многих возникает желание как-то упорядочить информацию в своей голове, дабы привести её к систематизированному виду. Хорошим катализатором для этого процесса является осознание факта, что вроде и обладаешь багажом знаний, но бабушке с улицы или шестилетнему ребёнку в простых словах этот багаж ну никак не получится объяснить. Ибо, как гласит народная мудрость, не смог объяснить ребёнку – значит, сам не знаешь. Да и вообще, дефрагментация информации ещё никому не вредила.
Но у нас не курс прикладной психологии, поэтому сегодня я просто изложу в систематизированном виде набора пикселей максимальное количество полезной информации о функции репликации виртуальных машин в среде гипервизора Hyper-V на примере текущей версии Windows Server 2012 R2.
Итак, на что я хочу потратить примерно час вашего времени:
Значение термина “репликация виртуальных машин” ничем не отличается от общепринятого в IT значения слова “репликация”: на стороннем хосте создаётся и поддерживается копия ВМ с основного хоста.
Давайте сразу договоримся: репликация — это не бекап! Как снапшоты не бекап, рейды не бекап, и вообще ничего не бекап кроме бекапа,ибо если бы дедушка был бабушкой…
Но лучше все же на всякий случай поясню, почему “не бекап”: в случае выхода из строя основной машины всегда можно без задержки включить реплику, но если выход из строя был спровоцирован не сиюминутной ошибкой, а комплексом накопленных проблем на уровне ОС или приложений, то все они будут успешно отражены на реплике, и ничего хорошего у вас не получится. Бесчисленно количество случаев, когда после включения реплицированной ВМ она работает несколько минут и умирает вслед за своим родителем с теми же симптомами.
Таким образом, репликация — это прекрасный инструмент для расширения вашего плана катастрофоустойчивости, позволяющий вернуть все ваши сервисы в боевое состояние с минимальной задержкой во времени, но нельзя на него перекладывать всю ответственность, т.к. ничто не совершенно и везде есть минусы.
Репликацию виртуальной машины Hyper-V как процесс возможно осуществить тремя путями:
Как было оговорено в самом начале, мы будем рассматривать только первый пункт — а именно репликацию Hyper-V машин встроенными средствами Windows Server 2012 R2. Позволю себе заметить, что именно R2 т.к. между первым и вторым релизом лежит функциональная пропасть, и использовать не R2 версию гипервизора в продакшн среде практически моветон.
Итак, что же нам предлагает Microsoft из коробки:
Считаю, что так же справедливо будет упомянуть инструмент от Microsoft, позволяющий с определённой долей погрешности подсчитать необходимые для репликации отдельно взятой виртуальной машины ресурсы. Называется он Capacity Planner for Hyper-V Replica Конечно, вы не получите точное количество IOPS, нагрузку на сеть и процессор, но как оценочный инструмент он весьма неплох и позволит проанализировать вашу инфраструктуру заранее.
При запуске вас попросят указать основной сервер, сервер для репликации, машины, которые предстоит обрабатывать и время проведения измерений. Рекомендую изменить установленные по умолчанию 30 минут в сторону увеличения до часа. И, конечно, оптимальное время для запуска — это самый разгар рабочего дня. Собранными данными можно очень здорово пугать начальство и просить денег на новыеигруш…железки.
И вот настал ответственный момент! Сертификаты есть, сеть настроена, везде работает Hyper-V роль, не забыты инструменты управления, и мы можем приступать.
Первым делом надо разрешить нашему хосту выступать в качестве сервера репликации и принимать машины на борт. Делается это через окно стандартных настроек Hyper-V:
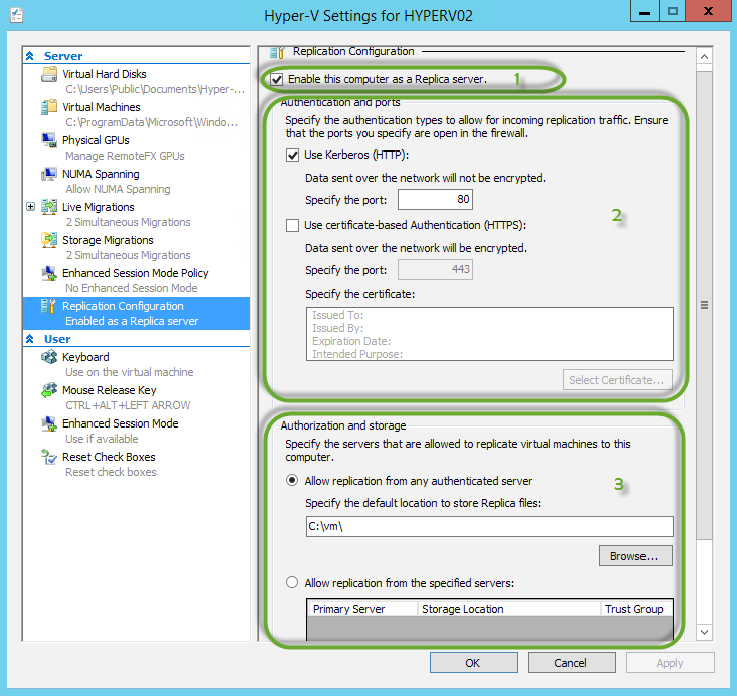
Все настройки прозрачные, но я хочу немного заострить внимание на нижней секции Authorization and storage. Это не критично, но очень рекомендую разрешать репликацию только с определёнными хостами или группами хостов. Не часто, но бывают случаи, когда по ошибке или от незнания запускается ошибочная репликация — и хорошо, если это запасной хост, а может случиться забивание хранилища боевого со всеми последующими развлечениями. Разрешать всё подряд — удел лабораторий для тестировщиков и разработчиков. Ну или просто смелых людей =)
Поскольку в самом начале мы договорились, что инфраструктура у нас как у взрослых (т.е. настроен и успешно работает кластер), то нам необходимо включить роль брокера реплик Hyper-V. Если же кластера у вас нет, то можете смело пропускать этот параграф.
Процедура активации проста и включает в себя 5 кнопок Next и одну Finish. Объяснять тут нечего, поэтому просто идём в мастер управления кластером, выбираем Configure Role и проходим мастера, не забыв дать NETBIOS совместимое имя и указать IP.
Небольшой хинт для тех, кто сначала читает документацию, а потом делает, хотя настоящие инженеры так не поступают, — всё описанное в предыдущем параграфе можно сделать непосредственно из брокера лишь с той разницей, что настройки будут применены сразу на весь кластер и не придётся вручную разрешать репликацию на каждом сервере. Как видите, выглядит всё точно так же:
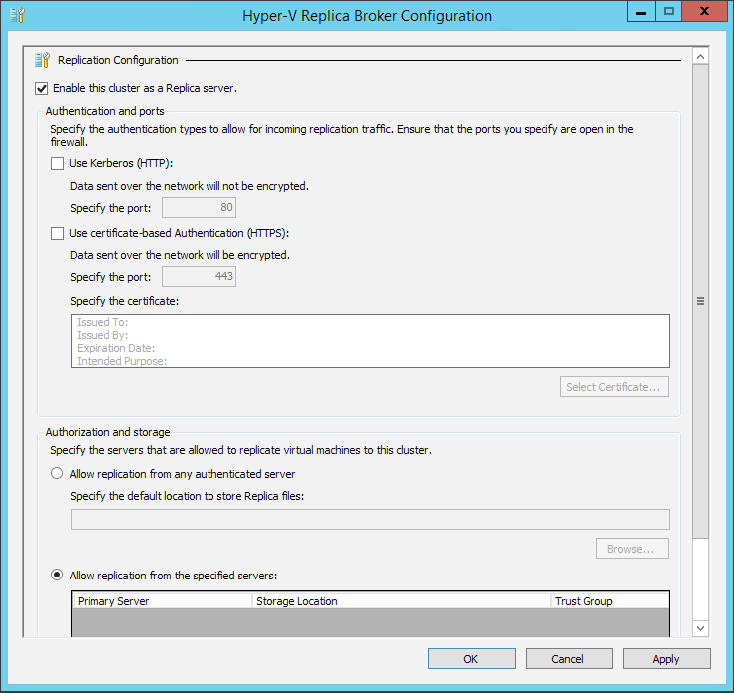
И небольшое пояснение о роли брокера в процессе репликации — при репликации машин, не участвующих в High Availability кластере, брокер никак не задействуется. Но когда речь заходит про кластеризованные машины, он полностью забирает на себя управление всеми процессами, связанными с репликацией и кластеризацией, не давая кластеру принять неверное решение о доступности машин. Поэтому золотое правило — с этого момента все действия вы должны делать только через консоль Failover Cluster Manager, иначе вы рискуете остаться без кластера. Даже если на боевой хост упадёт метеорит, худшее, что вы можете сделать в этой ситуации — это включить репличную машину через Hyper-V Manager.
Теперь наконец-то мы действительно готовы реплицировать нашу самую первую машину. Как и всё в Windows, делать это мы будем через правую кнопку мыши:
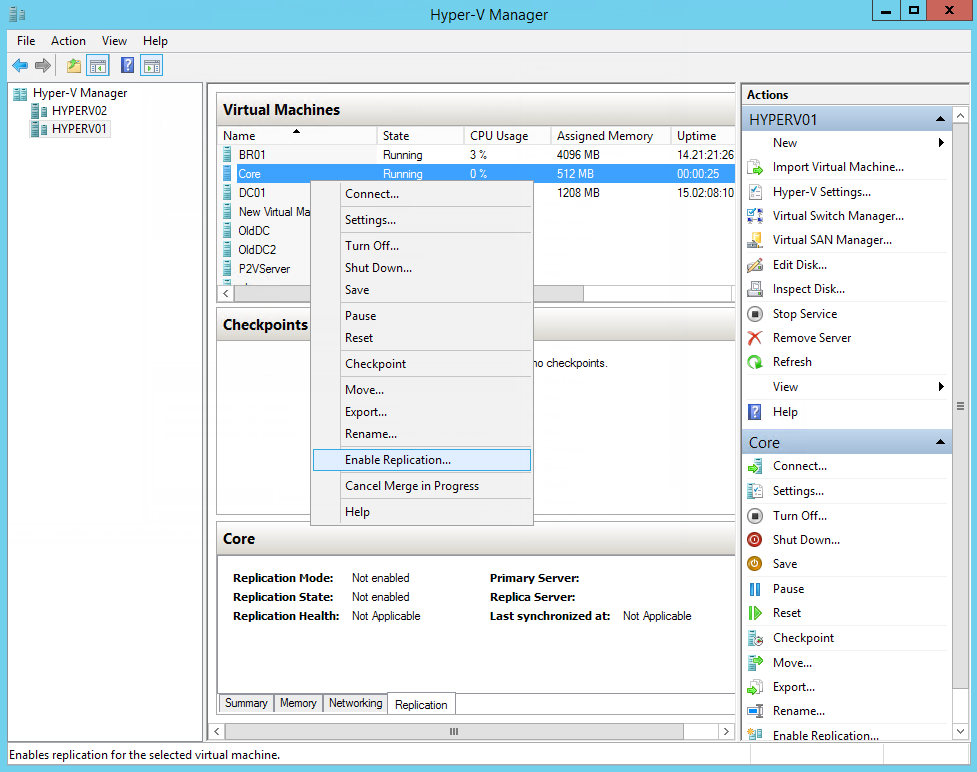
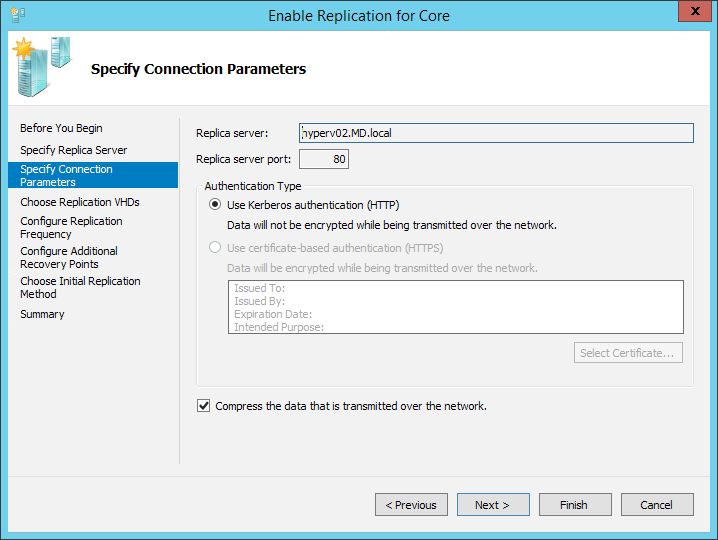
Дальше открывается довольно стандартный мастер настроек, где на первых шагах нас спрашивают имя сервера (куда будет реплицирована машина) и просят уточнить настройки подключения. Вернее, если хосты находятся в одном домене, то всё будет заполнено без нашего участия, а вот если сервера не знакомы, да ещё надо зашифровать трафик, то придётся все параметры указать вручную. Единственная галочка, заслуживающая внимания на этом шаге — “сжимать передаваемые данные”. Тут мы обращаемся к стадии планирования и смотрим, что нам важнее: сжимать информацию и скорее закончить передачу данных (что неизбежно вызовет дополнительную нагрузку на хосты), или нам не важен объём и длительность передачи, т.к. в приоритете производительность хоста. Два скучных скриншота:
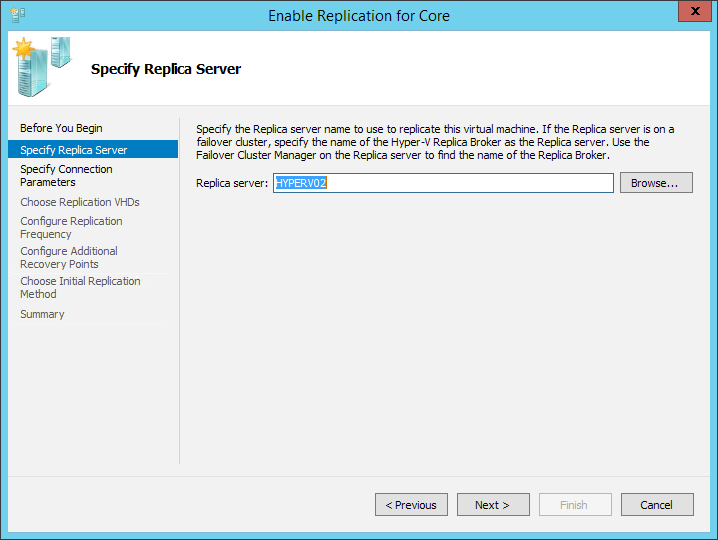
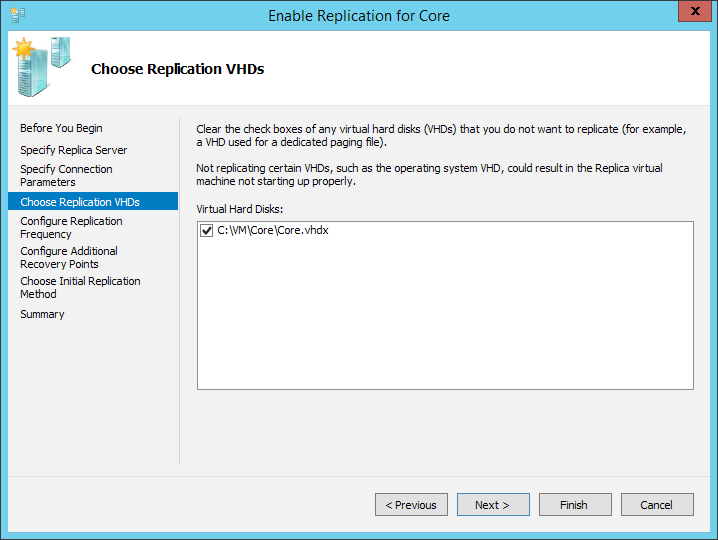
На следующем шаге необходимо выбрать диски, которые будут участвовать в репликации. В конце статьи, когда пойдёт речь про общую оптимизацию, я приведу несколько советов, а пока стоит запомнить одну деталь – диск, не отмеченный для репликации, будет полностью отсутствовать на принимающей стороне, т.е. он исключается из конфигурации виртуальной машины. Если без этого диска машина не может функционировать, но на нём хранится нечто неважное (вроде временных файлов), то просто создайте заново этот диск на реплицированной машине.
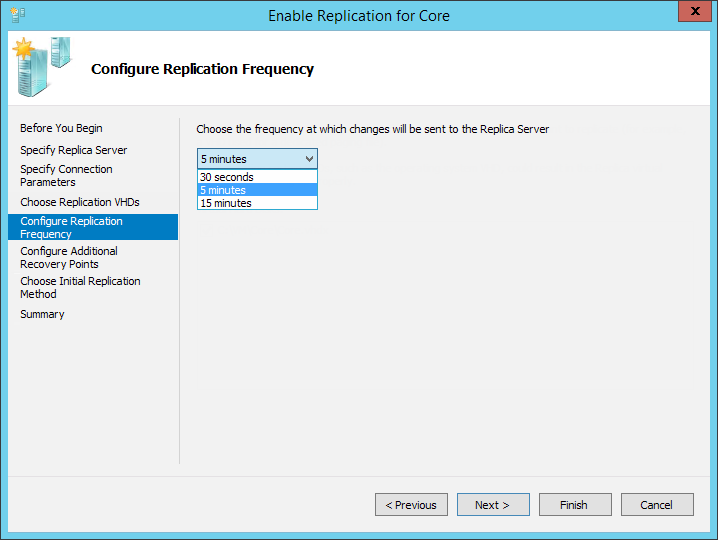
Затем снова обращаемся к этапу планирования и выставляем выбранный период репликации. Если по недоразумению вы всё ещё используете Server 2012, то вас даже не спросят, а просто выставят значение в 5 минут. Со временем Microsoft пришли к выводу, что такое поведение не совсем правильное, и в Server 2012 R2 добавили возможность выбора из 30 секунд, 5 и 15 минут. Не фонтан, конечно, но лучше, чем ничего.
И будьте очень осторожны, выбирая 30-ти секундный интервал — вам понадобится действительно очень сильный хост, с очень быстрой сетью и очень быстрым хранилищем.
Следующий ответственный шаг – указываем, сколько точек восстановления мы будем хранить. Здесь же указываем, с какой периодичностью будут создаваться VSS снапшоты. В принципе, можно прекрасно обходиться и без них, но тогда никто не сможет вам гарантировать консистентность данных со всеми вытекающим последствиями, особенно если речь идёт о приложениях, для которых она критична.
Пример на скриншоте можно интерпретировать на русский таким образом — нам необходимо создавать точку восстановления каждый час, хранить её 24 часа (это максимальное значение) и раз в 4 часа создавать VSS снапшот. Соглашусь с тем, что не самая прозрачная и удобная для понимания конструкция, но, что есть — с тем и работаем.

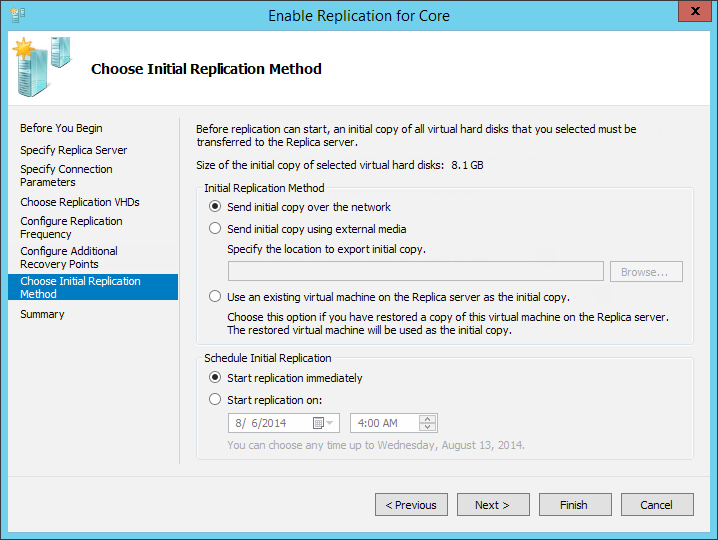
Следом идёт очень полезный пункт для тех, у кого ну очень большие машины или просто нет возможности передавать большие объёмы данных по сети. Как мы помним, при первом запуске с хоста на хост должен быть передан весь объём реплицируемой машины, и нам на выбор предлагается аж три варианта, как мы можем это сделать:
Затем нам предложат окинуть взглядом все введенные настройки и подтвердить своё желание кнопкой Finish. Нам скажут, что всё прошло хорошо, и предложат изменить сетевые настройки для реплик, т.к. по умолчанию они не подключены ни к одной сети (согласен, что это очень неожиданное место для такого предложения), но мне кажется, что лучше вопросы сети объяснить на практических примерах, которые будут дальше, а пока перейдём к расширенной репликации Hyper-V машин.
Как и многие другие интересные функции, расширенная репликация виртуальных машин появилась только в Windows Server 2012 R2. Расширенная репликация позволяет настраивать репликацию не только по принципу «точка-точка», но и выстраивать целые цепочки, когда после прохода репликации с главного сервера (назовём это основной репликой), запускается процесс репликации реплики (масло масляное, но лучше не скажешь) на третий хост.
И, если многим не совсем ясно, зачем вообще нужна репликация, то наличие возможности создания цепочки репликации, вероятно, способно окончательно запутать даже самых стойких. Однако предлагаю на ваш суд вот такой, не выдуманный пример. Предположим, что у вас достаточно большая компания, с несколькими серверными в одном здании, и вы настраиваете реплицирование каждые 30 секунд, чтобы в случае прорыва канализации и затопления серверов иметь возможность быстро включить копии ваших виртуальных машин с минимальными потерями данных. Это отличная схема, но, к сожалению, она никак не защищает от полного обесточивания здания или трактора, перегрызающего оптические каналы, подходящие к зданию. На такой случай очень хочется иметь копии машин где-то на стороне, обновляемые, пусть и не каждые 30 секунд, но хотя бы раз в 15 минут, чтобы не позволить вам упасть в грязь лицом.
Здесь стоит обозначить правила для проведения расширенной репликации виртуальных машин:
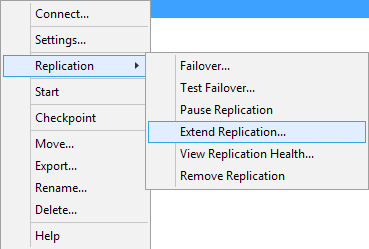
Мастер настройки расширенной репликации вызывается традиционно правым кликом по реплицированной машине и выбором пункта Extend Replication. Дальнейшая настройка происходит точь-в-точь как в случае с обычной, поэтому рассматривать её отдельно смысла нет.
И вот мы всё успешно настроили, запустили и проверили, поэтому предлагаю перейти к рассмотрению поведения в случае аварии сделав небольшую остановку около сетей.
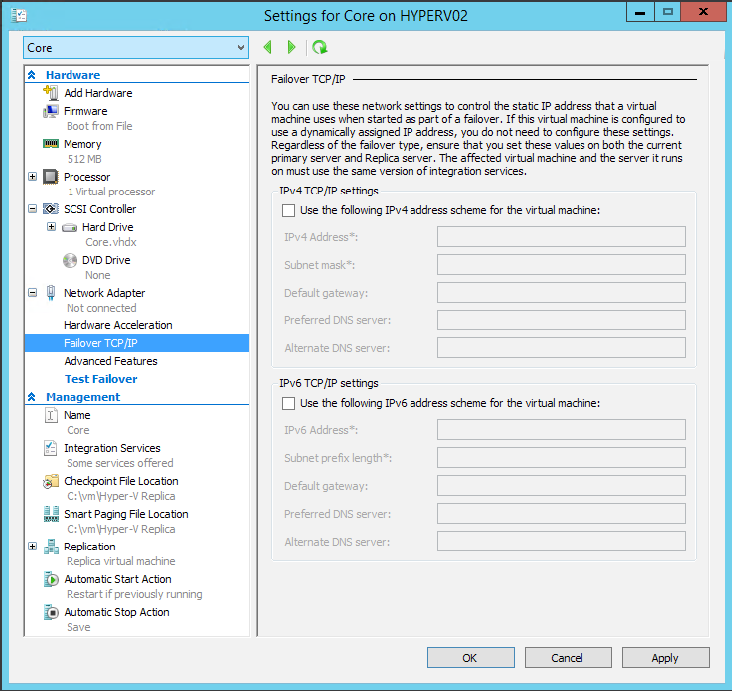
Доподлинно не известно, излишняя это паранойя или нет, но принято все реплики подключать к изолированной сети, которая никак не пересекается с производственной. А зачастую у администратора и вовсе нет выбора, т.к. в дата центре на принимающей стороне используются другие подсети, и у реплики должны быть абсолютно другие сетевые настройки.
И, как мы можем видеть на скриншоте ниже, Hyper-V предоставляет нам возможность указать точные настройки каждого сетевого адаптера на случай аварийного включения. Которое, кстати называется failover, и мы поговорим про него прямо сейчас.
Начну с объяснения термина Failover, т.к. адекватного перевода на язык Пушкина и Толстого ещё не придумали. Фейловером называется процесс правильного (читай управляемого) включения, оперирования и выключения реплицированной машины. Пример неправильного поведения: из панели управления хостом или кластером машина включается по кнопке Start. В этом случае мы получаем гарантированный крах репликации, с последующей настройкой заново, и весь набор весёлых проблем, свойственных наличию двух одинаковых машин в одной инфраструктуре.
Итак, фейловер бывает трёх видов:
Использование запланированного фейловера, подразумевает, что заранее известно о возможных проблемах с основным хостом. Например, будут проводиться работы с сетями питания, на вас движется ураган, необходимо выключить хост для обслуживания или рабочие поутру решили поковыряться в земле в опасной близости от подводящих кабельных трасс.
В данном варианте присутствует небольшой простой сервисов, равный времени выключения основной машины и загрузке реплики, но то, что переключение производится планово, дает возможность подобрать наиболее удобное для всех время.
Важный момент — репликация может быть продолжена в обратном режиме, т.е. все изменения, сделанные на стороне реплики, при её выключении будут переданы на основную машину. Это позволяет полностью исключить потерю данных.
Итак, как происходит запланированный фейловер:
Запускаем процесс фейловера и проверяем сетевую доступность поднятой машины для пользователей. Здесь самые частые ошибки — это неверно указанный VLAN и отсутствие соответствующей DNS записи. Ни то, ни другое мастер фейловера не проверяет, оставляя это на откуп администратору.
Самое забавное в этой ситуации — это то, как происходит обратное переключение: нам надо повторить фейловер, но на этот раз со стороны второго хоста, т.е. надо выключить на нём реплику и произвести её плановый фейловер. Решение более чем странное, но что есть — то есть.
Именно тот случай, когда название соответствует функционалу. Реплики, как и бекапы, хочется проверять, чтобы спать чуть более спокойно. А лучший способ проверить реплику — это включить её. На первый взгляд может показаться, что это другое название запланированного фейловера, однако это не так.
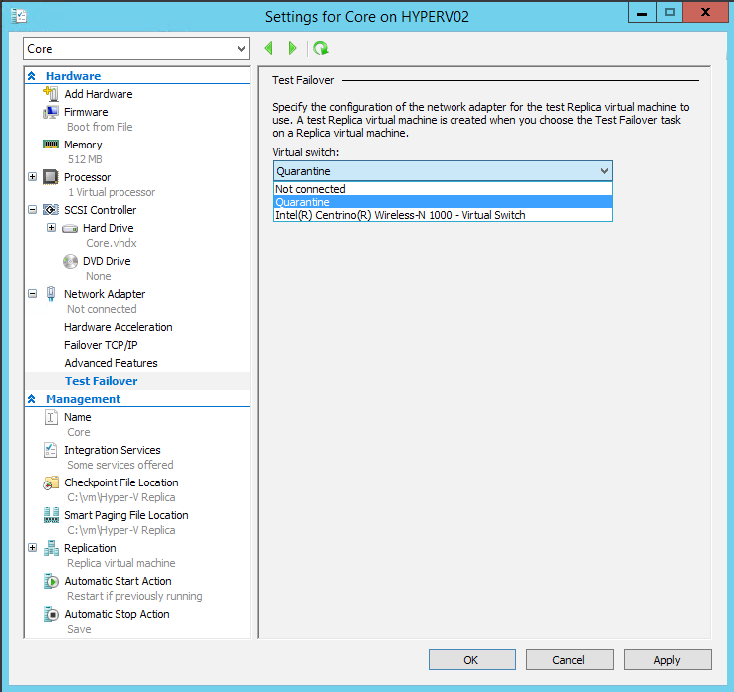
При выполнении тестового фейловера на стороне реплики создаётся временная машина, на которой можно выполнять разнообразные тесты. Например, проверить телнетом набор портов, и в случае утвердительного ответа быть уверенным, что сервисы на этих портах запущены успешно. Один нюанс — по умолчанию виртуальная машина в тестовом фейловере запускается не подключенной к сети. Поэтому первым шагом указываем общие сетевые настройки на случай фейловера, пере-открываем мастер и видим новый пункт меню:
Или более интересный вариант: посмотреть, как поведёт себя критичное для бизнес процессов приложение после установки нового патча, не забыв вывести машину в специально подготовленную изолированную сеть.
Само собой, тестовый фейловер надо запускать на стороне реплики. Процесс полностью повторяет плановый фейловер, с той лишь разницей, что после выполнения всех необходимых процедур его необходимо остановить. Иначе машина так и будет работать, пока рано или поздно не разрастётся на весь диск.
Здесь есть только одно золотое правило — никогда не запускать этот фейловер, кроме тех случаев, когда это действительно необходимо, т.е. если нет аварийной ситуации — пользуйтесь исключительно тестовым и плановым вариантами. Если необходимо просто посмотреть, как это работает, написать документацию для инженеров и т.п., то проделайте все шаги исключительно в тестовой среде.
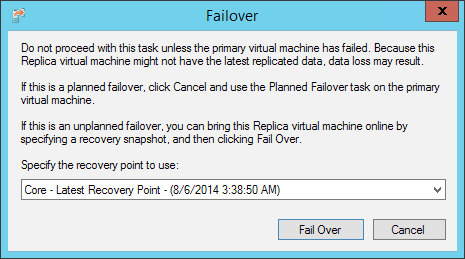
При выполнении фейловера единственная опция, которая будет вам доступна — это выбор необходимой точки восстановления. Дальше машина будет запущена несмотря ни на что. Если при выполнении планового фейловера мастер не даст вам выстрелить в ногу и включить две одинаковых машины (т.е. он будет ждать момента полного выключения основной машины), то в этом случае вы получите всего лишь очень чёткое, но ненавязчивое предупреждение.
В качестве последнего барьера перед точкой невозврата вам необходимо будет подтвердить завершение фейловера с помощью Complete-VMFailover командлета PowerShell. Все дополнительные точки восстановления будут удалены, а процесс фейловера логически завершён.
Прежде чем перейти к общим советам, я хочу затронуть тему частной оптимизации для конкретной инфраструктуры. Единственным источником информации, на основе которой можно будет делать далеко идущие выводы, само собой, служит всеобъемлющий мониторинг. Можно спорить, лучшим или нет является Operation Manager из пакета System Center. Но, поскольку в начале мы договорились не рассматривать сторонний софт, да ещё за немалые деньги, этот инструмент мы пропустим.
Итак, первое средство из коробки, которое встречает нас при каждой загрузке Windows Server, носит невзрачное название Best Practice Analyzer (оно находится в самом низу Server Manager консоли).
Запуская время от времени BPA, можно получить действительно ценные советы относительно настроек хоста, которые делаются на основе накопленных событий и мониторинга производительности различных подсистем вашего конкретного хоста и информации накопленной самой Microsoft.
По неизвестным мне причинам события для Hyper-V Replica не вынесены в отдельную подгруппу и, хотя и имеют свои уникальные номера, но идут под грифом Hyper-V. Правила, относящиеся к репликам, идут под номерами от 37 до 54 включительно.
Следующим по порядку идёт непосредственно консоль Hyper-V Manager. Стоит добавить в стандартное окно со списком машин дополнительную колонку Replication Health. Как нетрудно догадаться, в этой колонке будет отображено текущее состояние репликации.
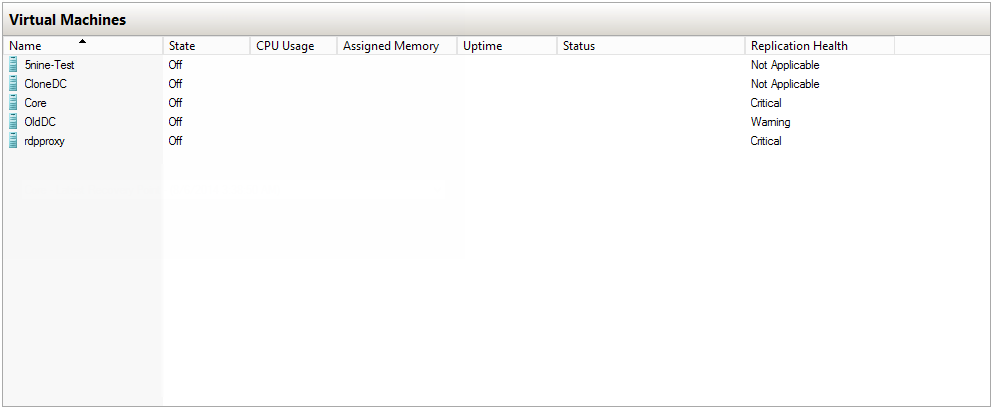
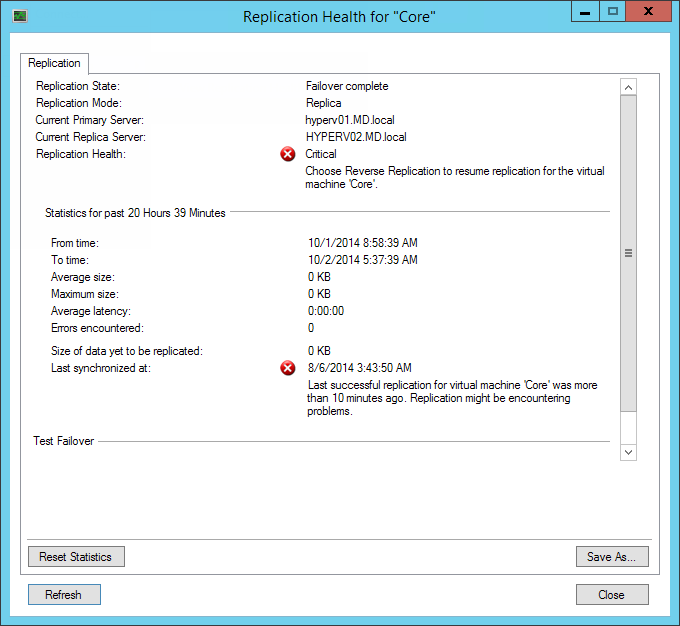
И через меню Replication можно вызвать весьма подробную справку о состоянии машины:
А теперь перейдём к общим советам:
Но у нас не курс прикладной психологии, поэтому сегодня я просто изложу в систематизированном виде набора пикселей максимальное количество полезной информации о функции репликации виртуальных машин в среде гипервизора Hyper-V на примере текущей версии Windows Server 2012 R2.
Итак, на что я хочу потратить примерно час вашего времени:
- Надо понять, зачем вообще нужна репликация в условиях современного мира
- Составить чек лист из очевидных и не очень пунктов, предшествующих настройке серверов
- Как правильно и быстро настроить репликацию встроенными средствами. Достаточно подробно, но без воды
- Несколько советов по оптимизации процесса репликации.
- Ни слова про продукты Veeam или других вендоров.
Акт первый. Обзорный.
Значение термина “репликация виртуальных машин” ничем не отличается от общепринятого в IT значения слова “репликация”: на стороннем хосте создаётся и поддерживается копия ВМ с основного хоста.
Давайте сразу договоримся: репликация — это не бекап! Как снапшоты не бекап, рейды не бекап, и вообще ничего не бекап кроме бекапа,
Но лучше все же на всякий случай поясню, почему “не бекап”: в случае выхода из строя основной машины всегда можно без задержки включить реплику, но если выход из строя был спровоцирован не сиюминутной ошибкой, а комплексом накопленных проблем на уровне ОС или приложений, то все они будут успешно отражены на реплике, и ничего хорошего у вас не получится. Бесчисленно количество случаев, когда после включения реплицированной ВМ она работает несколько минут и умирает вслед за своим родителем с теми же симптомами.
Таким образом, репликация — это прекрасный инструмент для расширения вашего плана катастрофоустойчивости, позволяющий вернуть все ваши сервисы в боевое состояние с минимальной задержкой во времени, но нельзя на него перекладывать всю ответственность, т.к. ничто не совершенно и везде есть минусы.
Репликацию виртуальной машины Hyper-V как процесс возможно осуществить тремя путями:
- Встроенными средствами гипервизора.
- С помощью стороннего софта. Тут интересный факт заключен в игнорировании этой функции некоторыми вендорами без видимых причин.
- С помощью средств SAN. Несомненно, метод самый интересный, быстрый и прочая…, но крайне дорогой.
Как было оговорено в самом начале, мы будем рассматривать только первый пункт — а именно репликацию Hyper-V машин встроенными средствами Windows Server 2012 R2. Позволю себе заметить, что именно R2 т.к. между первым и вторым релизом лежит функциональная пропасть, и использовать не R2 версию гипервизора в продакшн среде практически моветон.
Итак, что же нам предлагает Microsoft из коробки:
- Репликация с помощью асинхронного копирования изменённых данных с родительской машины на реплицированную. Асинхронное – значит, данные передаются не немедленно после изменения оригинальных данных, а через некоторые промежутки времени, что позволяет не “перенапрягать” машину-источник и канал передачи. В данный момент минимальный период репликации равен 30 секундам.
- Для репликации Hyper-V машин не надо иметь каких-то специальных разделяемых хранилищ или соблюдать единообразие оборудования для хранения на источнике и приёмнике
- Всё, что может быть виртуализовано, можно реплицировать.
- Репликация происходит по обычным IP сетям и, в случае необходимости, трафик может быть зашифрован.
- В Hyper-V репликация возможна как между отдельными хостами, так и между кластерами. И даже смешанный вариант возможен без ограничений.
- Хосты, между которыми происходит репликация, могут находиться где угодно, в каких угодно сетях и принадлежать разным доменам.
Чек-лист, пока не стало поздно
- Пункт первый и очевидный, но часто упускаемый: удостоверьтесь, что сервер, на который пойдёт репликация, имеет Hyper-V-совместимое железо. Инженерам свойственно запускать всё, что угодно, на чём угодно, но поверьте, что это не тот случай. Абсолютно не тот. Аппаратная поддержка виртуализации строго должна быть в обязательном порядке.
- Второй очевидный пункт: рассчитайте, сколько вам понадобится места на принимающем хранилище, и проверьте скорость его работы. Снимая с далёкой полки хранилку эпохи динозавров, вы рискуете увидеть общую скорость передачи данных на уровне той же эпохи, несмотря на все ваши сетевые гигабиты.
- Следствие предыдущего пункта: на основании периода репликации усреднённой виртуальной машины прикиньте, сколько будет весить каждая точка репликации и сколько таких точек вы можете себе позволить. Максимальное количество, доступное на данный момент — это 24 точки отката.
- Если планируется реплицировать машины, являющиеся частью Hyper-V кластера, то надо установить и настроить роль Replica Broker в кластере. Если на принимающей стороне есть кластер – надо повторить.
- Проверьте настройки фаерволов и роутинг на всем маршруте между хостами. Если за сеть отвечаете не вы, то найдите вашего сетевика и пытайте его калёным железом, пока он не выстроит кратчайший и быстрейших маршрут между хостами. С фаерволами всё проще: нам нужен 80 порт для Kerberos over HTTP и 443 для certificate-based over HTTPS. Само собой, порты можно поменять в процессе настройки.
- Если вы планируете шифровать трафик между хостами, то вам понадобятся сертификаты, и нужно заранее разложить их по всем заинтересованным серверам. И не побрезгуйте проверить сертификаты на срок годности, а центры сертификации внести в доверенные, если используете самоподписные.
- Проинспектируйте все ваши виртуальные машины на предмет используемых VHD. Имеете все шансы обнаружить диски, которые совершенно не надо реплицировать, что сэкономит вам время и деньги.
- Составьте список приложений, для которых важна консистентность данных. Проверьте здоровье VSS системы как на хостах, так и внутри гостевых ОС. Если ваши приложения не используют VSS (например, не самые старые версии Oracle), им придётся уделить отдельное внимание.
- Продумайте время для первого прохода репликации. При первом прогоне через сеть будет передана вся машина, — и, естественно, хочется это сделать вне рабочего времени. Если принимающий хост находится за границами локальной сети, вы рискуете не успеть закончить передачу за ночь или выходные и утром получить сильно загруженный канал связи и очень загруженный хост. Как избежать такой ситуации, будет написано чуть ниже.
- Учтите, что репликация в Hyper-V возможна не только между двумя хостами, но и с использованием промежуточных серверов. Этакая многоходовая репликация.
- Проанализируйте ваш текущий план резервного копирования на предмет совместимости с планом репликации. Думаю, никому не понравится ситуация, когда во время бекапа запустится ещё и репликация. Ваш хост вполне может не простить вам такую нагрузку. Так же стоит ответить на вопрос, что будет если вы восстановите машину из бекапа: нужна ли вам реплика в виде машины до аварии, или надо скорее привести её к консистентному виду.
Считаю, что так же справедливо будет упомянуть инструмент от Microsoft, позволяющий с определённой долей погрешности подсчитать необходимые для репликации отдельно взятой виртуальной машины ресурсы. Называется он Capacity Planner for Hyper-V Replica Конечно, вы не получите точное количество IOPS, нагрузку на сеть и процессор, но как оценочный инструмент он весьма неплох и позволит проанализировать вашу инфраструктуру заранее.
При запуске вас попросят указать основной сервер, сервер для репликации, машины, которые предстоит обрабатывать и время проведения измерений. Рекомендую изменить установленные по умолчанию 30 минут в сторону увеличения до часа. И, конечно, оптимальное время для запуска — это самый разгар рабочего дня. Собранными данными можно очень здорово пугать начальство и просить денег на новые
Акт второй. Настроечный.
И вот настал ответственный момент! Сертификаты есть, сеть настроена, везде работает Hyper-V роль, не забыты инструменты управления, и мы можем приступать.
Первым делом надо разрешить нашему хосту выступать в качестве сервера репликации и принимать машины на борт. Делается это через окно стандартных настроек Hyper-V:

Все настройки прозрачные, но я хочу немного заострить внимание на нижней секции Authorization and storage. Это не критично, но очень рекомендую разрешать репликацию только с определёнными хостами или группами хостов. Не часто, но бывают случаи, когда по ошибке или от незнания запускается ошибочная репликация — и хорошо, если это запасной хост, а может случиться забивание хранилища боевого со всеми последующими развлечениями. Разрешать всё подряд — удел лабораторий для тестировщиков и разработчиков. Ну или просто смелых людей =)
Зовём брокера
Поскольку в самом начале мы договорились, что инфраструктура у нас как у взрослых (т.е. настроен и успешно работает кластер), то нам необходимо включить роль брокера реплик Hyper-V. Если же кластера у вас нет, то можете смело пропускать этот параграф.
Процедура активации проста и включает в себя 5 кнопок Next и одну Finish. Объяснять тут нечего, поэтому просто идём в мастер управления кластером, выбираем Configure Role и проходим мастера, не забыв дать NETBIOS совместимое имя и указать IP.
Небольшой хинт для тех, кто сначала читает документацию, а потом делает, хотя настоящие инженеры так не поступают, — всё описанное в предыдущем параграфе можно сделать непосредственно из брокера лишь с той разницей, что настройки будут применены сразу на весь кластер и не придётся вручную разрешать репликацию на каждом сервере. Как видите, выглядит всё точно так же:

И небольшое пояснение о роли брокера в процессе репликации — при репликации машин, не участвующих в High Availability кластере, брокер никак не задействуется. Но когда речь заходит про кластеризованные машины, он полностью забирает на себя управление всеми процессами, связанными с репликацией и кластеризацией, не давая кластеру принять неверное решение о доступности машин. Поэтому золотое правило — с этого момента все действия вы должны делать только через консоль Failover Cluster Manager, иначе вы рискуете остаться без кластера. Даже если на боевой хост упадёт метеорит, худшее, что вы можете сделать в этой ситуации — это включить репличную машину через Hyper-V Manager.
Первый пошёл
Теперь наконец-то мы действительно готовы реплицировать нашу самую первую машину. Как и всё в Windows, делать это мы будем через правую кнопку мыши:

Дальше открывается довольно стандартный мастер настроек, где на первых шагах нас спрашивают имя сервера (куда будет реплицирована машина) и просят уточнить настройки подключения. Вернее, если хосты находятся в одном домене, то всё будет заполнено без нашего участия, а вот если сервера не знакомы, да ещё надо зашифровать трафик, то придётся все параметры указать вручную. Единственная галочка, заслуживающая внимания на этом шаге — “сжимать передаваемые данные”. Тут мы обращаемся к стадии планирования и смотрим, что нам важнее: сжимать информацию и скорее закончить передачу данных (что неизбежно вызовет дополнительную нагрузку на хосты), или нам не важен объём и длительность передачи, т.к. в приоритете производительность хоста. Два скучных скриншота:


На следующем шаге необходимо выбрать диски, которые будут участвовать в репликации. В конце статьи, когда пойдёт речь про общую оптимизацию, я приведу несколько советов, а пока стоит запомнить одну деталь – диск, не отмеченный для репликации, будет полностью отсутствовать на принимающей стороне, т.е. он исключается из конфигурации виртуальной машины. Если без этого диска машина не может функционировать, но на нём хранится нечто неважное (вроде временных файлов), то просто создайте заново этот диск на реплицированной машине.

Затем снова обращаемся к этапу планирования и выставляем выбранный период репликации. Если по недоразумению вы всё ещё используете Server 2012, то вас даже не спросят, а просто выставят значение в 5 минут. Со временем Microsoft пришли к выводу, что такое поведение не совсем правильное, и в Server 2012 R2 добавили возможность выбора из 30 секунд, 5 и 15 минут. Не фонтан, конечно, но лучше, чем ничего.
И будьте очень осторожны, выбирая 30-ти секундный интервал — вам понадобится действительно очень сильный хост, с очень быстрой сетью и очень быстрым хранилищем.

Следующий ответственный шаг – указываем, сколько точек восстановления мы будем хранить. Здесь же указываем, с какой периодичностью будут создаваться VSS снапшоты. В принципе, можно прекрасно обходиться и без них, но тогда никто не сможет вам гарантировать консистентность данных со всеми вытекающим последствиями, особенно если речь идёт о приложениях, для которых она критична.
Пример на скриншоте можно интерпретировать на русский таким образом — нам необходимо создавать точку восстановления каждый час, хранить её 24 часа (это максимальное значение) и раз в 4 часа создавать VSS снапшот. Соглашусь с тем, что не самая прозрачная и удобная для понимания конструкция, но, что есть — с тем и работаем.

Следом идёт очень полезный пункт для тех, у кого ну очень большие машины или просто нет возможности передавать большие объёмы данных по сети. Как мы помним, при первом запуске с хоста на хост должен быть передан весь объём реплицируемой машины, и нам на выбор предлагается аж три варианта, как мы можем это сделать:
- Непосредственно по сети с указанием времени старта процесса. Вариант по умолчанию, дополнительных комментариев не требующий.
- Самый интересный, на мой взгляд, вариант. Если его выбрать, в первый момент времени на передающем хосте будет создана и сохранена в отдельную папку машина-клон. Папка будет наименована по шаблону <VMname_GUID>. Эта же машина будет реплицирована в виде пустышки на принимающей стороне. Далее папку с фейковой машиной можно и нужно скопировать на внешний носитель и перенести ближе ко второму хосту. На втором хосте у машины-пустышки появится новый пункт в меню: Import Initial Replica, т.е. машина будет находиться в ожидании настоящих данных. Нас попросят указать путь к папке с данными, они будут скопированы на место постоянной службы, запустятся внутренние процессы согласования, и на этом проход первой реплики можно считать завершённым. Несомненно, чем дольше диск с данными будет путешествовать между хостами, тем больше будет разница между машинами, поэтому не стоит затягивать это путешествие.
- И третий вариант: когда на принимающей стороне уже есть копия виртуальной машины. Вы просто указываете эту машину, и дальше она будет использована как опорная. Как такое может быть? Например, она была восстановлена из бекапа. Или осталась от предыдущей репликации. Не важно, главное, что эта машина может быть использована как опорная, и по сети будут переданы только несовпадающие данные.

Затем нам предложат окинуть взглядом все введенные настройки и подтвердить своё желание кнопкой Finish. Нам скажут, что всё прошло хорошо, и предложат изменить сетевые настройки для реплик, т.к. по умолчанию они не подключены ни к одной сети (согласен, что это очень неожиданное место для такого предложения), но мне кажется, что лучше вопросы сети объяснить на практических примерах, которые будут дальше, а пока перейдём к расширенной репликации Hyper-V машин.
Расширяем широту наших глубин
Как и многие другие интересные функции, расширенная репликация виртуальных машин появилась только в Windows Server 2012 R2. Расширенная репликация позволяет настраивать репликацию не только по принципу «точка-точка», но и выстраивать целые цепочки, когда после прохода репликации с главного сервера (назовём это основной репликой), запускается процесс репликации реплики (масло масляное, но лучше не скажешь) на третий хост.
И, если многим не совсем ясно, зачем вообще нужна репликация, то наличие возможности создания цепочки репликации, вероятно, способно окончательно запутать даже самых стойких. Однако предлагаю на ваш суд вот такой, не выдуманный пример. Предположим, что у вас достаточно большая компания, с несколькими серверными в одном здании, и вы настраиваете реплицирование каждые 30 секунд, чтобы в случае прорыва канализации и затопления серверов иметь возможность быстро включить копии ваших виртуальных машин с минимальными потерями данных. Это отличная схема, но, к сожалению, она никак не защищает от полного обесточивания здания или трактора, перегрызающего оптические каналы, подходящие к зданию. На такой случай очень хочется иметь копии машин где-то на стороне, обновляемые, пусть и не каждые 30 секунд, но хотя бы раз в 15 минут, чтобы не позволить вам упасть в грязь лицом.
Здесь стоит обозначить правила для проведения расширенной репликации виртуальных машин:
- Частота расширенной репликации не может быть меньше основной т.е. если основная происходит раз в 5 минут, расширенная не может происходить каждые 30 секунд
- Частота создания VSS снепшотов не может быть изменена
- Нельзя поменять список дисков участвующих в репликации
- Однако можно изменить методы аутентификации и способ прохода первой реплики
Мастер настройки расширенной репликации вызывается традиционно правым кликом по реплицированной машине и выбором пункта Extend Replication. Дальнейшая настройка происходит точь-в-точь как в случае с обычной, поэтому рассматривать её отдельно смысла нет.

И вот мы всё успешно настроили, запустили и проверили, поэтому предлагаю перейти к рассмотрению поведения в случае аварии сделав небольшую остановку около сетей.
Немного о сетях
Доподлинно не известно, излишняя это паранойя или нет, но принято все реплики подключать к изолированной сети, которая никак не пересекается с производственной. А зачастую у администратора и вовсе нет выбора, т.к. в дата центре на принимающей стороне используются другие подсети, и у реплики должны быть абсолютно другие сетевые настройки.
И, как мы можем видеть на скриншоте ниже, Hyper-V предоставляет нам возможность указать точные настройки каждого сетевого адаптера на случай аварийного включения. Которое, кстати называется failover, и мы поговорим про него прямо сейчас.

Страшное слово Фейловер
Начну с объяснения термина Failover, т.к. адекватного перевода на язык Пушкина и Толстого ещё не придумали. Фейловером называется процесс правильного (читай управляемого) включения, оперирования и выключения реплицированной машины. Пример неправильного поведения: из панели управления хостом или кластером машина включается по кнопке Start. В этом случае мы получаем гарантированный крах репликации, с последующей настройкой заново, и весь набор весёлых проблем, свойственных наличию двух одинаковых машин в одной инфраструктуре.
Итак, фейловер бывает трёх видов:
- Запланированный
- Тестовый
- Аварийный (или просто фейловер, без приписок)
Плановый фелойвер
Использование запланированного фейловера, подразумевает, что заранее известно о возможных проблемах с основным хостом. Например, будут проводиться работы с сетями питания, на вас движется ураган, необходимо выключить хост для обслуживания или рабочие поутру решили поковыряться в земле в опасной близости от подводящих кабельных трасс.
В данном варианте присутствует небольшой простой сервисов, равный времени выключения основной машины и загрузке реплики, но то, что переключение производится планово, дает возможность подобрать наиболее удобное для всех время.
Важный момент — репликация может быть продолжена в обратном режиме, т.е. все изменения, сделанные на стороне реплики, при её выключении будут переданы на основную машину. Это позволяет полностью исключить потерю данных.
Итак, как происходит запланированный фейловер:
- Выключаем основную виртуальную машину. Сделать это можно только вручную, чтобы избежать ошибочного выключения. Пока машина не будет полностью выключена, мастер фейловера будет показывать соответствующую ошибку.
- Там же, на основном хосте, кликаем по выключенной машине и выбираем Planned Failover
-
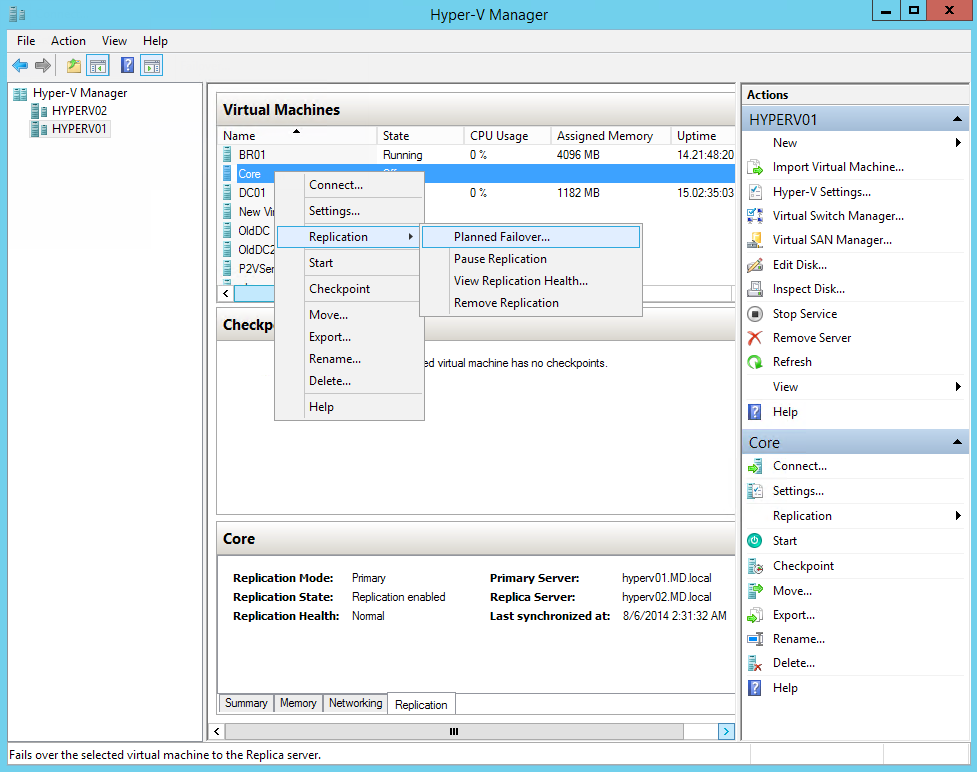
- По умолчанию пункт Reverse the replication direction after failover, обеспечивающий обратную репликацию, не отмечен, и, если вам не хочется терять данные, накопленные за время работы машины в режиме фейловера, стоит отметить этот пункт. Важное замечание — на основном хосте должно быть установлено разрешение о принятии реплик, о чём говорилось в самом начале, иначе данные просто не будут приняты.
-



Запускаем процесс фейловера и проверяем сетевую доступность поднятой машины для пользователей. Здесь самые частые ошибки — это неверно указанный VLAN и отсутствие соответствующей DNS записи. Ни то, ни другое мастер фейловера не проверяет, оставляя это на откуп администратору.
Самое забавное в этой ситуации — это то, как происходит обратное переключение: нам надо повторить фейловер, но на этот раз со стороны второго хоста, т.е. надо выключить на нём реплику и произвести её плановый фейловер. Решение более чем странное, но что есть — то есть.
Тестовый фейловер
Именно тот случай, когда название соответствует функционалу. Реплики, как и бекапы, хочется проверять, чтобы спать чуть более спокойно. А лучший способ проверить реплику — это включить её. На первый взгляд может показаться, что это другое название запланированного фейловера, однако это не так.
При выполнении тестового фейловера на стороне реплики создаётся временная машина, на которой можно выполнять разнообразные тесты. Например, проверить телнетом набор портов, и в случае утвердительного ответа быть уверенным, что сервисы на этих портах запущены успешно. Один нюанс — по умолчанию виртуальная машина в тестовом фейловере запускается не подключенной к сети. Поэтому первым шагом указываем общие сетевые настройки на случай фейловера, пере-открываем мастер и видим новый пункт меню:

Или более интересный вариант: посмотреть, как поведёт себя критичное для бизнес процессов приложение после установки нового патча, не забыв вывести машину в специально подготовленную изолированную сеть.
Само собой, тестовый фейловер надо запускать на стороне реплики. Процесс полностью повторяет плановый фейловер, с той лишь разницей, что после выполнения всех необходимых процедур его необходимо остановить. Иначе машина так и будет работать, пока рано или поздно не разрастётся на весь диск.
Аварийный фейловер
Здесь есть только одно золотое правило — никогда не запускать этот фейловер, кроме тех случаев, когда это действительно необходимо, т.е. если нет аварийной ситуации — пользуйтесь исключительно тестовым и плановым вариантами. Если необходимо просто посмотреть, как это работает, написать документацию для инженеров и т.п., то проделайте все шаги исключительно в тестовой среде.
При выполнении фейловера единственная опция, которая будет вам доступна — это выбор необходимой точки восстановления. Дальше машина будет запущена несмотря ни на что. Если при выполнении планового фейловера мастер не даст вам выстрелить в ногу и включить две одинаковых машины (т.е. он будет ждать момента полного выключения основной машины), то в этом случае вы получите всего лишь очень чёткое, но ненавязчивое предупреждение.

В качестве последнего барьера перед точкой невозврата вам необходимо будет подтвердить завершение фейловера с помощью Complete-VMFailover командлета PowerShell. Все дополнительные точки восстановления будут удалены, а процесс фейловера логически завершён.
Best Practice
Прежде чем перейти к общим советам, я хочу затронуть тему частной оптимизации для конкретной инфраструктуры. Единственным источником информации, на основе которой можно будет делать далеко идущие выводы, само собой, служит всеобъемлющий мониторинг. Можно спорить, лучшим или нет является Operation Manager из пакета System Center. Но, поскольку в начале мы договорились не рассматривать сторонний софт, да ещё за немалые деньги, этот инструмент мы пропустим.
Итак, первое средство из коробки, которое встречает нас при каждой загрузке Windows Server, носит невзрачное название Best Practice Analyzer (оно находится в самом низу Server Manager консоли).
Запуская время от времени BPA, можно получить действительно ценные советы относительно настроек хоста, которые делаются на основе накопленных событий и мониторинга производительности различных подсистем вашего конкретного хоста и информации накопленной самой Microsoft.
По неизвестным мне причинам события для Hyper-V Replica не вынесены в отдельную подгруппу и, хотя и имеют свои уникальные номера, но идут под грифом Hyper-V. Правила, относящиеся к репликам, идут под номерами от 37 до 54 включительно.
Следующим по порядку идёт непосредственно консоль Hyper-V Manager. Стоит добавить в стандартное окно со списком машин дополнительную колонку Replication Health. Как нетрудно догадаться, в этой колонке будет отображено текущее состояние репликации.

И через меню Replication можно вызвать весьма подробную справку о состоянии машины:


А теперь перейдём к общим советам:
- Не бойтесь провести за планированием и тестами лишний день
- По возможности выносите файл подкачки виртуальной машины на отдельный VHDX и исключайте его из репликации. Нет абсолютно никакого резона для его передачи.
- Если вы решили провести апгрейд серверов до 2012 R2, то сначала нужно выполнить апгрейд реплики, а затем основного сервера — и никогда наоборот. Репликация не поддерживает обратную совместимость.
- Если вы изменили размер диска у машины источника (стало возможным в Server 2012 R2), необходимо так же изменить диск у реплики. Автоматически это не происходит.
- Используйте Network Throttling, если нет возможности использовать выделенную сеть для репликации, т.к. процесс репликации способен полностью захватить всю полосу пропускания канала связи. В таких случаях QoS наше всё. На мой взгляд, проще всего настроить ограничения для процесса vmms.exe или для указанных портов
