DISCLAIMER: вы попались на clickbait. Очевидно, что TDD нельзя назвать ошибочным, но… Всегда есть какое-то но.
Содержание
Вступление
Первые шесть лет своей карьеры я фрилансил и участвовал в начальных этапах жизни мелких стартапов. В этих проектах не было тестов… Реально, ни единого.
В этих условиях ты обязан реализовать фичи на вчера. Поскольку требования рынка постоянно меняются, тесты устаревают ещё до того, как ты их заканчиваешь. И даже эти тесты можно создать только, если ты уверен в том, что именно ты хочешь создать, а это не всегда так. Занимаясь R&D ты вполне можешь не знать каков должен быть конечный результат. И даже достигая определённых успехов, ты не можешь быть уверен, что завтра рынок (а с ним и требования) не изменятся. В целом, существуют бизнес причины для экономии времени на тестировании.
Согласен, наша отрасль — это не только стартапы.
Около двух лет назад я устроился в достаточно большую аутсорсинг компанию, которая обслуживает клиентов любых размеров.
Во время разговоров на кухне/курилке, я обнаружил, что практически все согласны с тем, что юнит-тестирование и TDD это своего рода best practice. Но во всех проектах этой компании, в которых я участвовал, не было тестов. И нет, не я принимал такое решение. Конечно же, у нас есть проекты с отличным покрытием тестами, но они ещё и довольно сильно бюрократизированы.
Так в чём же проблема?
Почему все соглашаются, что TDD это хорошо, но никто не хочет его применять?
Может TDD ошибочно? – Нет!
Возможно, в нём нет никакой выгоды для бизнеса? – И опять, нет!
Может просто разработчики ленивы? – Да! Но это не причина.
Проблема в самих тестах!
Я понимаю, что звучит это странно, но я попытаюсь это доказать.
Тесты и есть проблема!
Исходя из этого исследования наименьшая общая удовлетворённость во всей экосистеме принадлежит именно инструментам для тестирования. Так было в 2016 и 2017 годах. Я не нашёл более ранних исследований, но это уже не очень важно.
Немного истории
В 2008 году вышел один из первых JS фреймворков для тестирования (QUnit).
В 2010 появился Jasmine.
В 2011 – Mocha.
Первый релиз Jest, который я нашёл, был в 2014.

Для сравнения.
В 2010 зарелизился angular.js.
Ember появился в 2011.
React — 2013.
И так далее…
Во время написания этой статьи не был создан ни один JS фреймворк...
Во всяком случае, мной.

За этот же период времени мы увидели взлёт и падение grunt, потом gulp, после чего осознали всю мощь npm scripts и вышел в свет стабильный релиз webpack.

Всё поменялось за последние 10 лет. Всё кроме тестирования.
Небольшая викторина
Давайте проверим ваши знания. Что это за библиотеки/фреймворки?
1:
var hiddenBox = $("#banner-message"); $("#button-container button").on("click", function(event) { hiddenBox.show(); });
2:
@Component({ selector: 'app-heroes', templateUrl: './heroes.component.html', styleUrls: ['./heroes.component.css'] }) export class HeroesComponent{ hero: Hero = { id: 1, name: 'Windstorm' }; constructor() { } }
3:
function Avatar(props) { return ( <img className="Avatar" src={props.user.avatarUrl} alt={props.user.name} /> ); }
Ответы:
Хорошо. Я уверен, что все ваши ответы были верны. Но что на счёт этих фреймворков для тестирования?
1:
var assert = require('assert'); describe('Array', function() { describe('#indexOf()', function() { it('should return -1 when the value is not present', function() { assert.equal([1,2,3].indexOf(4), -1); }); }); });
2:
const sum = require('./sum'); test('adds 1 + 2 to equal 3', () => { expect(sum(1, 2)).toBe(3); });
3:
test('timing test', function (t) { t.plan(2); t.equal(typeof Date.now, 'function'); var start = Date.now(); setTimeout(function () { t.equal(Date.now() - start, 100); }, 100); });
4:
let When2IsAddedTo2Expect4 = Assert.AreEqual(4, 2+2)
Ответы:
Вы могли угадать некоторые из них, но, в целом, они все очень похожи. Заметьте, что даже при смене языка, мало что меняется.
У нас есть, как минимум, 8 лет опыта юнит-тестирования в мире JavaScript'а.
Но мы ведь просто адаптировали уже существующее на тот момент. Юнит-тестирование, как мы его знаем, появилось намного раньше. Если взять релиз Test Anything Protocol (1987) как точку отсчёта, то мы используем текущие подходы дольше, чем я живу.
TDD ненамного моложе, если не старше. Всё это приводит нас к тому, что мы уже можем объективно оценить все плюсы и минусы.
Обзор TDD
Давайте вспомним, что такое TDD.
Разработка через тестирование (англ. test-driven development, TDD) — техника разработки программного обеспечения, которая основывается на повторении очень коротких циклов разработки: сначала пишется тест, покрывающий желаемое изменение, затем пишется код, который позволит пройти тест, и под конец проводится рефакторинг нового кода к соответствующим стандартам. (с) википедия

Но что это нам даёт?
Тесты — это формализованные требования
Это правда только частично.
TDD как практика была "переизобретена" Кентом Беком в 1999 году, в то время как Agile Manifesto был принят только 2 года спустя (в 2001). Я должен это подчеркнуть, что бы вы поняли, что TDD родился в "Золотой век" каскадной модели и этот факт определяет наиболее благоприятные условия и процессы, для которых он и был спроектирован. Очевидно, что TDD будет лучше всего работать именно в таких условиях.
Так что, если вы работаете в проекте, где:
- Требования ясны;
- Вы полностью их понимаете;
- Они стабильны и не будут часто меняться.
Вы можете создавать тесты, как формализацию требований.
Но что бы использовать существующие тесты таким же образом, необходимо выполнение и следующих пунктов тоже:
- В тестах нет ошибок;
- Они актуальны;
- И они покрывают почти все сценарии использования (не путать с покрытием кода).
Так что "Тесты — это формализованные требования" — правда только тогда, когда эти требования существуют до начала самой разработки, как в "модели Водопад" или проектах NASA, где "клиенты" это ученые и инженеры.
В определённых условиях это будет работать и с "Agile" процессами. Особенно, если что-нибудь по типу BDD будет использовано, но это уже совсем другая история.
TDD поощряет хорошую архитектуру
И опять это правда только частично.
TDD поощряет модульность, что необходимо, но недостаточно для хорошей архитектуры.
Качество архитектуры зависит от разработчиков. Опытные разработчики способны создавать отличный код, несмотря на использование или неиспользование юнит-тестирования.
С другой стороны, слабые разработчики будут создавать низкокачественный код, покрытый низкокачественными тестами, потому что создание хороших тестов — это своего рода искусство, как и само программирование.
Конечно, тесты как секс: "лучшие плохой, чем никакого вовсе". Но...
Этот тест никак не продвинет вас на пути к хорошему дизайну системы:
import { inject, TestBed } from '@angular/core/testing'; import { UploaderService } from './uploader.service'; describe('UploaderService', () => { beforeEach(() => { TestBed.configureTestingModule({ providers: [UploaderService], }); }); it('should be created', inject([UploaderService], (service: UploaderService) => { expect(service).toBeTruthy(); })); });
Потому, что он ничего не тестирует.
Обратите внимание, мы использовали 15 строк кода, чтобы ничего не протестировать.
Но и этот тест не сделает дизайн вашей системы лучше:
var IotSimulation = artifacts.require("./IotSimulation.sol"); var SmartAsset = artifacts.require("./SmartAsset.sol"); var BuySmartAsset = artifacts.require("./BuySmartAsset.sol"); var BigInt = require('big-integer'); contract('BuySmartAsset', function (accounts) { it("Should sell asset", async () => { var deliveryCity = "Lublin"; var extra = 1000; // var gasPrice = 100000000000; const smartAsset = await SmartAsset.deployed(); const iotSimulation = await IotSimulation.deployed(); const buySmartAsset = await BuySmartAsset.deployed() const result = await smartAsset.createAsset(Date.now(), 200, "docUrl", 1, "email@email1.com", "Audi A8", "VIN02", "black", "2500", "car"); const smartAssetGeneratedId = result.logs[0].args.id.c[0]; await iotSimulation.generateIotOutput(smartAssetGeneratedId, 0); await iotSimulation.generateIotAvailability(smartAssetGeneratedId, true); await smartAsset.calculateAssetPrice(smartAssetGeneratedId); const assetObjPrice = await smartAsset.getSmartAssetPrice(smartAssetGeneratedId); assert.isAbove(parseInt(assetObjPrice), 0, 'price should be bigger than 0'); await smartAsset.makeOnSale(smartAssetGeneratedId); var assetObj = await smartAsset.getAssetById.call(smartAssetGeneratedId); assert.equal(assetObj[9], 3, 'state should be OnSale = position 3 in State enum list'); await smartAsset.makeOffSale(smartAssetGeneratedId); assetObj = await smartAsset.getAssetById.call(smartAssetGeneratedId); assert.equal(assetObj[9], 2, 'state should be PriceCalculated = position 2 in State enum list'); await smartAsset.makeOnSale(smartAssetGeneratedId); const calculatedTotalPrice = await buySmartAsset.getTotalPrice.call(smartAssetGeneratedId, '112', '223'); await buySmartAsset.buyAsset(smartAssetGeneratedId, '112', '223', { from: accounts[1], value: BigInt(calculatedTotalPrice.toString()).add(BigInt(extra)) }); assetObj = await smartAsset.getAssetById.call(smartAssetGeneratedId); assert.equal(assetObj[9], 0, 'state should be ManualDataAreEntered = position 0 in State enum list'); assert.equal(assetObj[10], accounts[1]); const balanceBeforeWithdrawal = await web3.eth.getBalance(accounts[1]); const gas = await buySmartAsset.withdrawPayments.estimateGas({ from: accounts[1] }); await buySmartAsset.withdrawPayments({ from: accounts[1], gasPrice: gasPrice }); const balanceAfterWithdrawal = await web3.eth.getBalance(accounts[1]); var totalGas = gas * gasPrice; assert.isOk((BigInt(balanceAfterWithdrawal.toString()).add(BigInt(totalGas))).eq(BigInt(balanceBeforeWithdrawal.toString()).add(BigInt(extra)))); }) })
Наибольшая проблема этого теста — это изначальная кодовая база, но даже в таком случае его можно было существенно улучшить, даже без рефакторинга уже работающего проекта.
Вообще, влияние TDD на итоговую архитектуру приблизительно на том же уровне, что и влияние выбранной библиотеки/фреймворка, если не меньше (например, Nest, RxJs и MobX, по моему личному мнению, влияют существенно сильнее).
Но ни TDD, ни фреймворки не спасут от плохого кода и неудачных архитектурных решений.
Не существует серебряной пули.
TDD экономит время
А это уже зависит от многих факторов...
Давайте предположим, что:
- Все в проекте достаточно хорошо владеют выбранным тестовым инструментом, методологией TDD и лучшими практиками юнит-тестирования;
- И все понимают всё вышеперечисленное одинаково;
- А требования прозрачны и стабильны;
- К тому же, команда разработчиков понимает их точно так же, как и "Product Owner";
- А менеджмент готов решать все организационные проблемы, вызванные TDD (например, более длинный процесс ввода новых разработчиков в команду).
Даже в этом случае, вам необходимо сначала инвестировать время и усилия, что удлинит начальную фазу разработки и только спустя какое-то время вы получите выгоду, сократив необходимое время на исправление ошибок и поддержку продукта.
Конечно, второе может быть больше чем стартовая инвестиция и в этом случае выгода от TDD очевидна.
Так же в некоторых случаях вы сможете сэкономить время и на внедрении новой функциональности, поскольку тесты будут сразу выявлять непреднамеренные изменения.
Но в реальном мире, который очень динамичен, требования могут измениться и то, что было корректным поведением раньше, станет некорректным. В этом случае вам необходимо переписать тесты в связи с новыми реалиями. И, очевидно, приложить новые усилия, которые не окупятся сразу же.
Вы даже можете попасть в цикл подобного типа:
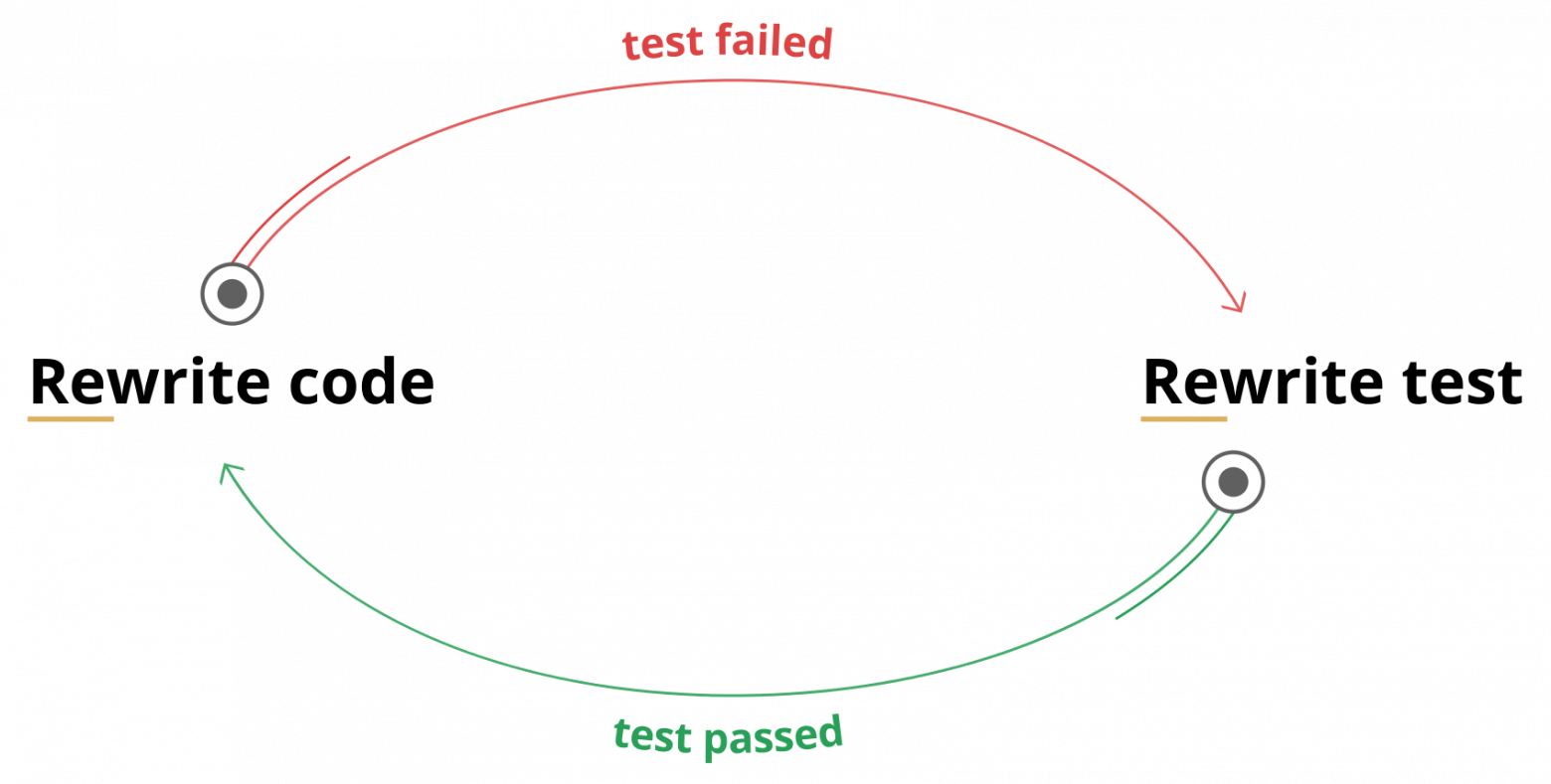
Ладно, этот цикл противоречит принципам TDD. Но следующий уже нет:

Попробуйте найти в них значимые различия.
Тесты — это лучшая документация
Нет. Они хороши в этом, но однозначно не лучшие.
Давайте взглянем на документацию angular:
Или react:

Как вы думаете, что в них общего? — Они обе построены на примерах кода. И даже более того. Все эти примеры можно легко запустить (angular использует StackBlitz, а react — CodePen), так что вы можете увидеть, что оно даёт на выходе и что произойдёт, если вы что-то измените.
Конечно же, там так же есть и простой текст, но это как комментарии в коде — они вам нужны только если вы что-то не поняли из самого кода.
Исполняемые примеры кода — вот лучшая документация!
Тесты близки к этому, но недостаточно.
describe('ReactTypeScriptClass', function() { beforeEach(function() { container = document.createElement('div'); attachedListener = null; renderedName = null; }); it('preserves the name of the class for use in error messages', function() { expect(Empty.name).toBe('Empty'); }); it('throws if no render function is defined', function() { expect(() => expect(() => ReactDOM.render(React.createElement(Empty), container) ).toThrow() ).toWarnDev([ // A failed component renders twice in DEV 'Warning: Empty(...): No `render` method found on the returned ' + 'component instance: you may have forgotten to define `render`.', 'Warning: Empty(...): No `render` method found on the returned ' + 'component instance: you may have forgotten to define `render`.', ]); });
Это небольшой кусочек из реального теста в react. Мы можем выделить примеры кода из него:
container = document.createElement('div'); Empty.name;
container = document.createElement('div'); ReactDOM.render(React.createElement(Empty), container);
Всё остальное это вручную написанный инфраструктурный код.
Давайте будем честными, пример теста выше намного менее читабельный чем настоящая документация. И проблема не в этом конкретном тесте — я уверен, что ребят из facebook знают, как писать хороший код и хорошие тесты :) Весь этот мусор из инструментов тестирования и assertion библиотек, как it, describe, test, to.be.true просто захламляет ваши тесты.
Кстати, есть библиотека, которая называется tape с минималистичным API, потому что любой тест можно переписать, используя толькоequal/deepEqual, а думать в этих терминах это в целом хорошая практика для юнит-тестирования. Но даже тестам дляtapeещё очень далеко до просто исполняемых примеров кода.
Но стоит заметить, что тесты всё ещё вполне пригодны для использования в качестве документации. У них действительно ниже вероятность быть устаревшими, а наше сознание просто выкидывает лишнее, когда мы их читаем. Если мы попробуем визуализировать то, во что превращается тест в нашей голове, то это будет выглядеть приблизительно так:

Как вы видите, это уже намного ближе к реальной доке, чем изначальный тест.
Немного выводов
- Тесты — это формализованные требования если они стабильны;
- TDD поощряет хорошую архитектуру если разработчики достаточно квалифицированы;
- TDD экономит время если вы его вложите сначала;
- Тесты — это лучшая документация если нет других исполняемых примеров кода.
Значит TDD всё-таки ошибочно? — Нет, TDD не ошибочно.
Оно указывает правильно направление и поднимает важные вопросы. Мы просто должны переосмыслить и изменить способ его применения.
В чём же решение?
Не воспринимайте TDD как "серебряную пулю".
Не воспринимайте его даже как процесс по типу Agile, например.
Вместо этого сфокусируйтесь на его реальных сильных сторонах:
- Предотвращение непреднамеренных изменений, другими словами фиксирование существующего поведения как своего рода 'базовой линии' (англ. термин 'baseline' нам ещё пригодится);
- Использование примеров из документации, как тестов.
Думайте о юнит-тестировании как о инструменте разработчика. Как линтер или компилятор, например.
Вы не будете спрашивать у Product Owner'а разрешения на использование линтера — вы просто будете его использовать.
Когда-нибудь это станет реальностью и для юнит-тестирования. Когда необходимые для TDD усилия будут на уровне использования тайпчекера или бандлера. Но до этого момента, просто минимизируйте свои затраты, создавая тесты максимально похожими на исполняемые примеры и используйте их как текущий baseline состояния вашего проекта.
Я понимаю, что это будет сложно, особенно учитывая тот факт, что большинство популярных инструментов спроектированы для других целей.
Правда, я создал один такой, беря во внимание все вышеописанные проблемы. Он называется

Базовая концепция очень проста. Пишите код:
export function sampleFn(a: any, b: any) { return a + b + b + a; }
И просто используйте его в вашем тесте:
import { sampleFn } from './index'; export = { values: [ sampleFn(1, 1), sampleFn(1000000, 1000000), sampleFn('abc', 'cba'), sampleFn(1, 'abc'), sampleFn('abc', 1), new Promise(resolve => resolve(sampleFn('async value', 1))), ], };
NOTE: тест, конечно же, очень синтетический — просто для демонстрации.
Потом выполняете команду baset test и получаете временный baseline:
{ "values": [ 4, 4000000, "abccbacbaabc", "1abcabc1", "abc11abc", "async value11async value" ] }
Если значения верны, выполняете baset accept и коммитите созданный baseline в ваш репозиторий.
Все последующие прогонки тестов буду сравнивать существующий baseline со значениями, экспортированными из ваших тестов. Если они отличаются, тест провален, иначе — пройден.
Если требования изменились, просто измените код, прогоните тесты и примите новый baseline.
Этот инструмент всё ещё оберегает вас от непреднамеренных изменений, при этом требует минимальных усилий. Всё что вам нужно, это просто написать исполняемый пример кода, который, к тому же, является основой хорошей документации.
Несколько примеров
Использование с react. Вот этот тест:
import * as React from 'react'; import { jsxFn } from './index'; export const value = ( <div> {jsxFn('s', 's')} {jsxFn('abc', 'cba')} {jsxFn('s', 'abc')} {jsxFn('abc', 's')} </div> );
создаст такой .md файл как baseline:
exports.value:
<div data-reactroot=""> <div class="cssCalss"> ss </div> <div class="cssCalss"> abccba </div> <div class="cssCalss"> sabc </div> <div class="cssCalss"> abcs </div> </div>
Или с pixi.js:
import 'pixi.js'; interface IResourceDictionary { [index: string]: PIXI.loaders.Resource; } const ASSETS = './assets/assets.json'; const RADAR_GREEN = 'Light_green'; const getSprite = async () => { await new Promise(resolve => PIXI.loader .add(ASSETS) .load(resolve)); return new PIXI.Sprite(PIXI.utils.TextureCache[RADAR_GREEN]); }; export const sprite = getSprite();
Этот тест создаст такой baseline:
exports.sprite:

Немного про планы
Я обязан сказать, что этот инструмент ещё на очень ранней стадии разработки и впереди ещё очень много нововведений, например:
- Watch/Workflow mode
- TAP compatibility
- Git acceptance strategy
- VS Code extension
- … и, как минимум, 24 других.
Только около 40% от запланированного было реализовано. Но вся базовая функциональность уже работает, так что можете попробовать поиграться с ней. Может быть вам даже понравится, кто знает?

