Хотелось бы рассказать один интересный механизм работы с конфигурацией распределённой системы. Конфигурация представлена напрямую в компилируемом языке (Scala) с использованием безопасных типов. В этом посте разобран пример такой конфигурации и рассмотрены различные аспекты внедрения компилируемой конфигурации в общий процесс разработки.
(english)
Введение
Построение надёжной распределённой системы подразумевает, что на всех узлах используется корректная конфигурация, синхронизированная с другими узлами. Обычно используется технологии DevOps (terraform, ansible или что-то наподобие) для автоматической генерации конфигурационных файлов (зачастую своих для каждого узла). Нам также хотелось бы быть уверенными в том, что на всех взаимодействующих узлах используются идентичные протоколы (в том числе, одинаковой версии). В противном случае в нашей распределённой системе будет заложена несовместимость. В мире JVM одним из следствий такого требования является необходимость использования везде одной и той же версии библиотеки, содержащей сообщения протокола.
Что насчёт тестирования распределённой системы? Разумеется, мы предполагаем, что для всех компонентов предусмотрены unit-тесты, прежде, чем мы перейдём к интеграционному тестированию. (Чтобы мы могли экстраполировать результаты тестирования на runtime, мы также должны обеспечить идентичный набор библиотек на этапе тестирования и в runtime'е.)
При работе с интеграционными тестами зачастую проще везде использовать единых classpath на всех узлах. Нам останется только обеспечить, чтобы тот же самый classpath был задействован и в runtime. (Несмотря на то, что вполне возможно запускать разные узлы с разными classpath'ами, это приводит к усложнению всей конфигурации и трудностям с развёртыванием и интеграционными тестами.) В рамках этого поста мы исходим из того, что на всех узлах будет использоваться одинаковый classpath.
Конфигурация развивается вместе с приложением. Для идентификации различных стадий эволюции программ мы используем версии. По-видимому, логично также идентифицировать и разные версии конфигураций. А саму конфигурацию поместить в систему контроля версий. Если в production'е существует единственная конфигурация, то мы можем использовать просто номер версии. Если же используется множество экземпляров production, то нам потребуется несколько
веток конфигурации и дополнительная метка помимо версии (например, название ветки). Тем самым мы сможем однозначно идентифицировать точную конфигурацию. Каждый идентификатор конфигурации однозначно соответствует определённой комбинации распределённых узлов, портов, внешних ресурсов, версий библиотек. В рамках этого поста мы будем исходить из того, что имеется только одна ветка, и мы можем идентифицировать конфигурацию обычным образом с использованием трёх чисел, разделённых точкой (1.2.3).
В современных окружениях конфигурационные файлы вручную создаются довольно редко. Чаще они генерируются в ходе развёртывания и больше их уже не трогают (чтобы ничего не сломать). Возникает закономерный вопрос, почему мы всё ещё используем текстовый формат для хранения конфигурации? Вполне жизнеспособной альтернативой выглядит возможность использовать обычный код для конфигурации и получить преимущества за счёт проверок во время компиляции.
В настоящем посте мы как раз исследуем идею представления конфигурации внутри компилированного артефакта.
Компилируемая конфигурация
В этом разделе рассмотрен пример статической компилируемой конфигурации. Реализуются два простых сервиса — эхо сервис и клиент эхо сервиса. На основе этих двух сервисов собираются два варианта системы. В одном варианте оба сервиса располагаются на одном узле, в другом варианте — на разных узлах.
Обычно распределённая система содержит несколько узлов. Можно идентифицировать узлы с помощью значений некоторого типа NodeId:
sealed trait NodeId case object Backend extends NodeId case object Frontend extends NodeId
или
case class NodeId(hostName: String)
или даже
object Singleton type NodeId = Singleton.type
Узлы исполняют различные роли, на них запущены сервисы и между ними могут быть установлены TCP/HTTP связи.
Для описания TCP связи нам требуется по меньшей мере номер порта. Мы также хотели бы отразить тот протокол, который поддерживается на этом порту, чтобы гарантировать, что и клиент и сервер пользуются одним и тем же протоколом. Будем описывать соединение с помощью такого класса:
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol])
где Port — просто целое число Int с указанием диапазона допустимых значений:
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]]
См. библиотеку refined и мой доклад. Вкратце, библиотека позволяет добавлять к типам ограничения, проверяемые на этапе компиляции. В данном случае допустимыми значениями номера порта являются целые 16-битные числа. Для компилируемой конфигурации использование библиотеки refined не является обязательным, но позволяет улучшить возможности компилятора по проверке конфигурации.
Для HTTP (REST) протоколов кроме номера порта нам также может потребоваться путь к сервису:
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]] case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix)
Для идентификации протокола на этапе компиляции мы используем параметр типа, который не используется внутри класса. Такое решение связано с тем, что в runtime'е мы экземпляр протокола не используем, но хотели бы, чтобы компилятор проверял совместимость протоколов. Благодаря указанию протокола мы не сможем передать неподходящий сервис в качестве зависимости.
Одним из распространённых протоколов является REST API с Json-сериализацией:
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage]
где RequestMessage — тип запроса, ResponseMessage — тип ответа.
Разумеется, можно использовать и другие описания протоколов, которые обеспечивают требующуюся нам точность описания.
Для целей настоящего поста мы будем использовать упрощённую версию протокола:
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage]
Здесь запрос представляет собой строку, добавляемую к url, а ответ — возвращаемая строка в теле HTTP ответа.
Конфигурация сервиса описывается именем сервиса, портами и зависимостями. Эти элементы можно представить в Scala несколькими способами (например, HList-ами, алгебраическими типами данных). Для целей настоящего поста мы будем использовать Cake Pattern и представлять модули с помощью trait'ов. (Cake Pattern не является обязательным элементом описываемого подхода. Это просто одна из возможных реализаций.)
Зависимости между сервисами можно представить в виде методов, возвращающих порты EndPoint'ы других узлов:
type EchoProtocol[A] = SimpleHttpGetRest[A, A] trait EchoConfig[A] extends ServiceConfig { def portNumber: PortNumber = 8081 def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo") def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort) }
Для создания эхо-сервиса достаточно только номера порта и указания, что этот порт поддерживает эхо-протокол. Мы могли бы и не указывать конкретный порт, т.к. trait'ы позволяют объявлять методы без реализации (абстрактные методы). В этом случае при создании конкретной конфигурации компилятор потребовал бы от нас предоставить реализацию абстрактного метода и предоставить номер порта. Так как мы реализовали метод, то при создании конкретной конфигурации мы можем не указывать другой порт. Будет использовано значение по умолчанию.
В конфигурации клиента мы объявляем зависимость от эхо-сервиса:
trait EchoClientConfig[A] { def testMessage: String = "test" def pollInterval: FiniteDuration def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]] }
Зависимость имеет тот же тип, что и экспортируемый сервис echoService. В частности, в эхо-клиенте мы требуем тот же протокол. Поэтому при соединении двух сервисов мы можем быть уверены, что всё будет работать корректно.
Для запуска и остановки сервиса требуется функция. (Возможность остановки сервиса критически важна для тестирования.) Опять-таки есть несколько вариантов реализации такой функции (например, мы могли бы использовать классы типов на основе типа конфигурации). Для целей настоящего поста мы воспользуемся Cake Pattern'ом. Мы будем представлять сервис с помощью класса cats.Resource, т.к. в этом классе уже предусмотрены средства безопасного гарантированного освобождение ресурсов в случае проблем. Чтобы получить ресурс нам надо предоставить конфигурацию и готовый runtime-контекст. Функция запуска сервиса может иметь следующий вид:
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]] trait ServiceImpl[F[_]] { type Config def resource( implicit resolver: AddressResolver[F], timer: Timer[F], contextShift: ContextShift[F], ec: ExecutionContext, applicative: Applicative[F] ): ResourceReader[F, Config, Unit] }
где
Config— тип конфигурации для этого сервисаAddressResolver— объект времени исполнения, который позволяет узнать адреса других узлов (см. далее)
и остальные типы из библиотеки cats:
F[_]— тип эффекта (в простейшем случаеF[A]может быть просто функцией() => A. В настоящем посте мы будем использоватьcats.IO.)Reader[A,B]— более-менее синоним функцииA => Bcats.Resource— ресурс, который может быть получен и освобождёнTimer— таймер (позволяет засыпать на некоторое время и измерять интервалы времени)ContextShift— аналогExecutionContextApplicative— класс типа эффекта, позволяющий объединять отдельные эффекты (почти монада). В более сложных приложениях, по-видимому, лучше использоватьMonad/ConcurrentEffect.
Пользуясь этой сигнатурой функции мы можем реализовать несколько сервисов. Например, сервис, который ничего не делает:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] { type Config <: Any def resource(...): ResourceReader[F, Config, Unit] = Reader(_ => Resource.pure[F, Unit](())) }
(См. исходный код, в котором реализованы другие сервисы — эхо-сервис, эхо клиент
и контроллеры времени жизни.)
Узел представляет собой объект, который может стартовать несколько сервисов (запуск цепочки ресурсов обеспечивается за счёт Cake Pattern'а):
object SingleNodeImpl extends ZeroServiceImpl[IO] with EchoServiceService with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Обратите внимание, что мы указываем точный тип конфигурации, которая требуется для этого узла. Если мы забудем указать какой-то из типов конфигурации, требуемых отдельным сервисом, то будет ошибка компиляции. Также мы не сможем стартовать узел, если не предоставим какой-то объект, имеющий подходящий тип со всеми необходимыми данными.
Чтобы соединиться с удалённым узлом, нам требуется реальный IP-адрес. Вполне возможно, что адрес станет известен позже, чем остальные части конфигурации. Поэтому нам нужна функция, отображающая идентификатор узла в адрес:
case class NodeAddress[NodeId](host: Uri.Host) trait AddressResolver[F[_]] { def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]] }
Можно предложить несколько способов реализации такой функции:
- Если адреса нам становятся известны до развёртывания, то мы можем сгенерировать Scala-код с
адресами и затем запустить сборку. При этом будет произведена компиляция и выполнены тесты.
В таком случае функция будет известна статически и может быть представлена в коде в виде отображенияMap[NodeId, NodeAddress]. - В некоторых случаях действительный адрес становится известен только после запуска узла.
В этом случае мы можем реализовать "сервис обнаружения" (discovery), который запускается до остальных узлов и все узлы будут регистрироваться в этом сервисе и запрашивать адреса других узлов. - Если мы можем модифицировать
/etc/hosts, то можно использовать предопределённые имена хостов (наподобиеmy-project-main-nodeиecho-backend) и просто связывать эти имена
с IP-адресами в ходе развёртывания.
В рамках настоящего поста мы не будем рассматривать эти случаи более подробно. Для нашего
игрушечного примера все узлы будут иметь один IP-адрес — 127.0.0.1.
Далее рассмотрим два варианта распределённой системы:
- Размещение всех сервисов на одном узле.
- И размещение эхо-сервиса и эхо-клиента на разных узлах.
Конфигурация для одного узла:
object SingleNodeConfig extends EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig { case object Singleton // identifier of the single node // configuration of server type NodeId = Singleton.type def nodeId = Singleton /** Type safe service port specification. */ override def portNumber: PortNumber = 8088 // configuration of client /** We'll use the service provided by the same host. */ def echoServiceDependency = echoService override def testMessage: UrlPathElement = "hello" def pollInterval: FiniteDuration = 1.second // lifecycle controller configuration def lifetime: FiniteDuration = 10500.milliseconds // additional 0.5 seconds so that there are 10 requests, not 9. }
Объект реализует конфигурацию и клиента и сервера. Также используется конфигурация времени жизни, чтобы по прошествии интервала lifetime завершить работу программы. (Ctrl-C также работает и корректно освобождает все ресурсы.)
Тот же самый набор trait'ов конфигурации и реализаций можно использовать для создания системы, состоящей из двух отдельных узлов:
object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig { type NodeId = NodeIdImpl def nodeId = NodeServer override def portNumber: PortNumber = 8080 } object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig { // NB! dependency specification def echoServiceDependency = NodeServerConfig.echoService def pollInterval: FiniteDuration = 1.second def lifetime: FiniteDuration = 10500.milliseconds // additional 0.5 seconds so that there are 10 request, not 9. def testMessage: String = "dolly" }
Важно! Обратите внимание, как выполняется связывание сервисов. Мы указываем сервис, реализуемый одним узлом в качестве реализации метода-зависимости другого узла. Тип зависимости проверяется компилятором, т.к. содержит тип протокола. При запуске зависимость будет содержать корректный идентификатор целевого узла. Благодаря такой схеме мы указываем номер порта ровно один раз и всегда гарантированно ссылаемся на правильный порт.
Для этой конфигурации мы используем те же реализаци сервисов без изменений. Единственное отличие заключается в том, что теперь у нас два объекта, реализующих разные наборы сервисов:
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl { type Config = EchoConfig[String] with SigTermLifecycleConfig } object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Первый узел реализует сервер и нуждается только в серверной конфигурации. Второй узел реализует клиент и использует другую часть конфигурации. Также оба узла нуждаются в управлении временем жизни. Серверный узел работает неограниченно долго, пока не будет остановлен SIGTERM'ом, а клиентский узел завершается спустя некоторое время. См. приложение запуска.
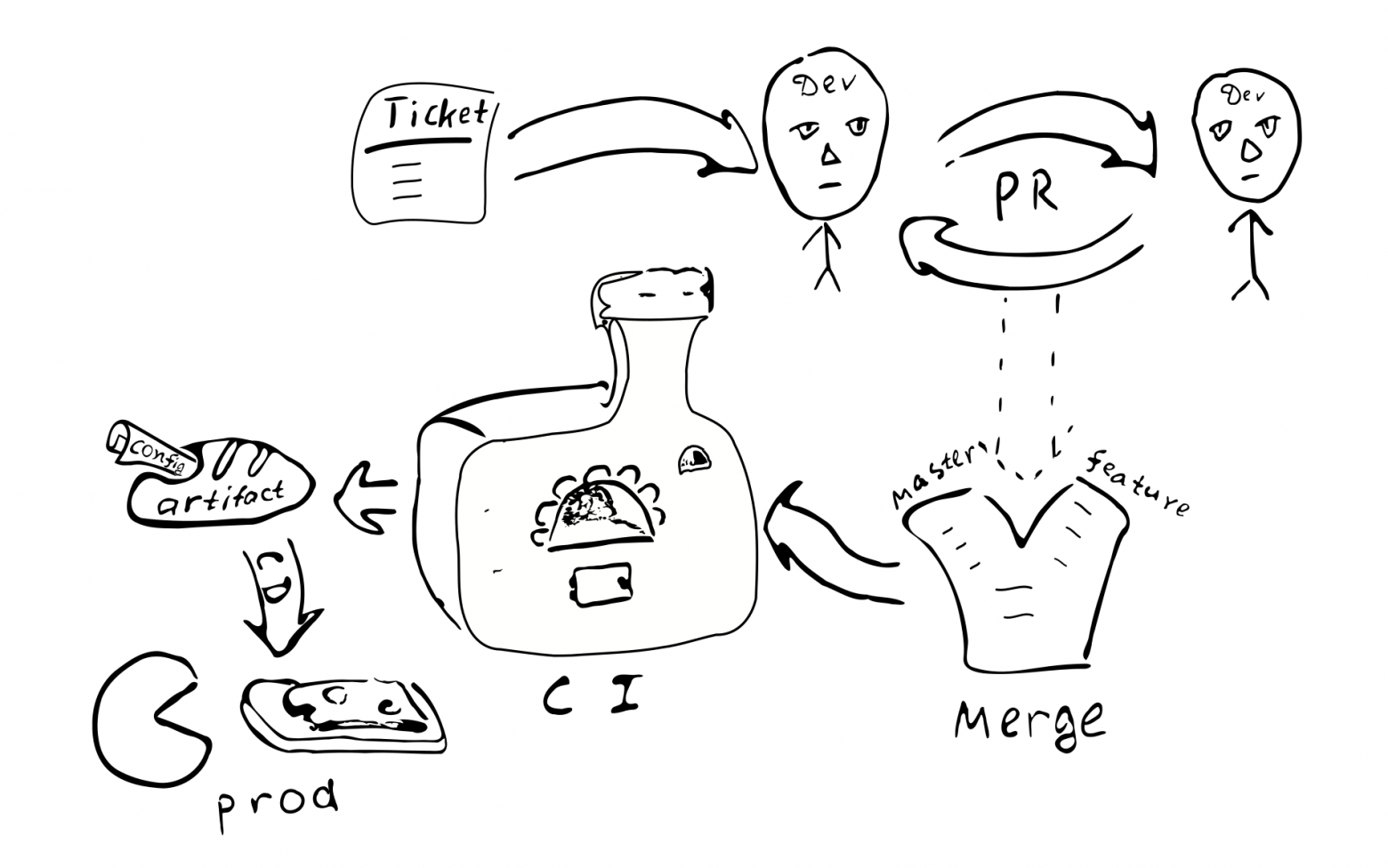
Общий процесс разработки
Посмотрим, как этот подход к конфигурированию влияет на общий процесс разработки.
Конфигурация будет скомпилирована вместе с остальным кодом и будет сгенеророван артефакт (.jar). По-видимому, имеет смысл поместить конфигурацию в отдельный артефакт. Это связано с тем, что у нас может быть множество конфигураций на основе одного и того же кода. Опять-таки, можно генерировать артефакты, соответствующие различным веткам конфигурации. Вместе с конфигурацией сохраняются зависимости от конкретных версий библиотек и эти версии сохраняются навсегда, когда бы мы ни решили развернуть эту версию конфигурации.
Любое изменение конфигурации превращается в изменение кода. А следовательно, каждое такое
изменение будет охвачено обычным процессом обеспечения качества:
Тикет в багтрекере -> PR -> ревью -> слияние с соответствующими ветками ->
интеграция -> развёртывание
Основные последствия внедрения компилируемой конфигурации:
Конфигурация будет согласована на всех узлах распределённой системы. В силу того, что все узлы получают одну и ту же конфигурацию из единого источника.
Проблематично изменить конфигурацию только в одном из узлов. Поэтому "рассинхронизация конфигурации" (configuration drift) маловероятна.
Становится труднее вносить небольшие изменения в конфигурацию.
Большая часть изменений конфигурации будут происходить в рамках общего процесса разработки и будет подвергнута ревью.
Нужен ли отдельный репозиторий для хранения production-конфигурации? В такой конфигурации могут содержаться пароли и другая секретная информация, доступ к которой мы хотели бы ограничить. Исходя из этого, по-видимому, имеет смысл хранить конечную конфигурацию в отдельном репозитории. Можно разделить конфигурацию на две части — одну, содержащую общедоступные параметры конфигурации, и другую, содержащую параметры ограниченного доступа. Это позволит большинству разработчиков иметь доступ общим параметрам. Такого разделения несложно достичь, используя промежуточные trait'ы, содержащие значения по умолчанию.
Возможные вариации
Попробуем сравнить компилируемую конфигурацию с некоторыми распространёнными альтернативами:
- Текстовый файл на целевой машине.
- Централизованное хранилище ключ-значение (
etcd/zookeeper). - Компоненты процесса, которые могут быть реконфигурированы/перезапущены без перезапуска процесса.
- Хранение конфигурации вне артефакта и контроля версий.
Текстовые файлы предоставляют значительную гибкость с точки зрения небольших изменений. Системный администратор может зайти на удалённый узел, внести изменения в соответствующие файлы и перезапустить сервис. Для больших систем, однако, такая гибкость может быть нежелательной. От внесённых изменений не остаётся следов в других системах. Никто не осуществляет review изменений. Трудно установить, кто именно вносил изменения и по какой причине. Изменения не тестируются. Если система распределённая, то администратор может забыть внести соответствующее изменение на других узлах.
(Также следует заметить, что применение компилируемой конфигурации не закрывает возможность использования текстовых файлов в будущем. Достаточно будет добавить парсер и валидатор, дающие на выходе тот же тип Config, и можно пользоваться текстовыми файлами. Отсюда непосредственно следует, что сложность системы с компилируемой конфигурацией несколько меньше, чем сложность системы, использующей текстовые файлы, т.к. для текстовых файлов требуется дополнительный код.)
Централизованное хранилище ключ-значение является хорошим механизмом для распределения мета-параметров распределённого приложения. Нам следует определиться, что такое конфигурационные параметры, а что — просто данные. Пусть у нас есть функция C => A => B, причём параметры C редко меняются, а данные A — часто. В этом случае мы можем сказать, что C — конфигурационные параметры, а A — данные. Похоже, что конфигурационные параметры отличаются от данных тем, что они меняются в общем случае реже, чем данные. Также данные обычно поступают из одного источника (от пользователя), а конфигурационные параметры — из другого (от администратора системы).
Если редко-меняющиеся параметры требуется обновлять без перезапуска программы, то зачастую это может приводить к усложнению программы, ведь нам потребуется каким-то образом доставлять параметры, хранить, парсить и проверять, обрабатывать некорректные значения. Поэтому, с точки зрения снижения сложности программы, имеет смысл уменьшать количество параметров, которые могут меняться в ходе работы программы (либо совсем не поддерживать такие параметры).
С точки зрения настоящего поста, мы будем различать статические и динамические параметры. Если логика работы сервиса требует изменения параметров в ходе действия программы, то мы будем называть такие параметры динамическими. В противном случае параметры являются статическими и могут быть сконфигурированы с использованием компилируемой конфигурации. Для динамической реконфигурации нам может потребоваться механизм перезапуска частей программы с новыми параметрами аналогично тому, как происходит перезапуск процессов операционной системы. (По нашему мнению, желательно избегать реконфигурации в реальном времени, т.к. при этом сложность системы возрастает. Если возможно, лучше пользоваться стандартными возможностями ОС по перезапуску процессов.)
Одним из важных аспектов использования статической конфигурации, который заставляет людей рассматривать динамическое реконфигурирование, является время, требующееся системе для перезагрузки после обновления конфигурации (downtime). В самом деле, если нам надо внести изменения в статическую конфигурацию, нам придётся перезапустить систему, чтобы новые значения вступили в силу. Проблема downtime'а имеет разную остроту для разных систем. В некоторых случаях можно запланировать перезагрузку на такое время, когда нагрузка минимальна. В случае, если требуется обеспечить непрерывный сервис, можно реализовать "дренаж соединений" (AWS ELB connection draining). При этом, когда нам надо перезагрузить систему, мы запускаем параллельный экземпляр этой системы, переключаем балансировщик на неё, и ждём, пока старые соединения завершатся. После того, как все старые соединения завершились, мы выключаем старый экземпляр системы.
Рассмотрим теперь вопрос хранения конфигурации внутри артефакта или вне его. Если мы храним конфигурацию внутри артефакта, то, как минимум, мы имели возможность во время сборки артефакта убедиться в корректности конфигурации. В случае, если конфигурация находится вне контролируемого артефакта, трудно отследить кто и зачем вносил изменения в этот файл. Насколько это важно? На наш взгляд, для многих production-систем важно иметь стабильную и высококачественную конфигурацию.
Версия артефакта позволяет определить когда он был создан, какие значения содержит, какие функции включены/отключены, кто несёт ответственность за любое измнеение в конфигурации. Разумеется, хранение конфигурации внутри артефакта требует некоторых усилий, поэтому надо принимать осознанное решение.
За и против
Хотелось бы остановиться на плюсах и минусах предлагаемой технологии.
Преимущества
Ниже приведён список основных возможностей компилируемой конфигурации распределённой системы:
- Статическая проверка конфигурации. Позволяет быть уверенными в том, что
конфигурация корректна. - Богатый язык конфигурации. Обычно другие способы конфигурирования ограничены максимум подстановкой строковых переменных. При использовании Scala становится доступен широкий спектр возможностей языка, чтобы улучшить конфигурацию. Например, мы можем использовать
trait'ы для значений по умолчанию, с помощью объектов группировать параметры, можем ссылаться на val'ы, объявленные единственный раз (DRY) в охватывающей области видимости. Можно непосредственно внутри конфигурации инстанцировать любые классы (Seq,Map, пользовательские классы). - DSL. В Scala есть ряд языковых возможностей, облегчающих создание DSL. Можно воспользоваться этими возможностями и реализовать язык конфигурации, который был бы более удобным для целевой группы пользователей, так, что конфигурация была бы по меньшей мере читабельной специалистами предметной области. Специалисты могут, например, участвовать в процессе ревью конфигурации.
- Целостность и синхронность между узлами. Одним из преимуществ того, что конфигурация целой распределённое системы хранится в единственной точке является то, что все значения объявляются ровно один раз, а затем переиспользуются везде, где они требуются. Использование фантомных типов для объявления портов позволяет гарантировать, что во всех корректных конфигурациях системы узлы используют совместимые протоколы. Наличие явных обязательных зависимостей между узлами гарантирует, что все сервисы будут связаны между собой.
- Высокое качество внесения изменений. Внесение изменений в конфигурацию, пользуясь общим процессом разработки, делает доступными высокие стандарты качества и для конфигурации.
- Одновременное обновление конфигурации. Автоматическое развёртывание системы после внесения изменений в конфигурацию позволяет гарантировать, что все узлы будут обновлены.
- Упрощение приложения. Приложение не нуждается в парсигне, проверке конфигурации и обработке некорректных значений. Тем самым сложность приложения снижается. (Некоторое усложнение конфигурации, которое наблюдается в нашем примере, не является атрибутом компилируемой конфигурации, а только лишь осознанным решением, вызванным желанием обеспечить большую типо-безопасность.) Достаточно легко вернуться к обычной конфигурации — просто реализовать отсутствующие части. Поэтому можно, например, начать с компилируемой конфигурации, отложив реализацию лишних частей на то время, когда это действительно потребуется.
- Версионированная конфигурация. Так как конфигурационные изменения следуют обычной судьбе любых других изменений, то на выходе мы получаем артефакт с уникальной версией. Это позволяет нам, например, вернуться к предыдущей версии конфигурации в случае необходимости. Мы даже можем воспользоваться конфигурацией годичной давности и при этом система будет работать в точности также. Стабильная конфигурация улучшает предсказуемость и надёжность распределённой системы. Так как конфигурация зафиксирована на этапе компиляции, то её довольно трудно подделать в production'е.
- Модульность. Предлагаемый фреймворк является модульным, и модули могут быть скомбинированы в различных вариантах для получения разных систем. В частности, можно в одном варианте сконфигурировать систему для запуска на одном узле, а в другом — на нескольких узлах. Можно создать несколько конфигураций для production-экземпляров системы.
- Тестирование. Заменив отдельные сервисы на mock-объекты, можно получить несколько версий системы, удобных для тестирования.
- Интеграционное тестирование. Наличие единой конфигурации всей распределённой системы обеспечивает возможность запуска всех компонентов в контролируемом окружении в рамках интеграционного тестирования. Легко эмулировать, например, ситуацию, когда некоторые узлы становятся надоступны.
Недостатки и ограничения
Компилируемая конфигурация отличается от других подходов к конфигурированию и для некоторых приложений может не подходить. Ниже приведены некоторые недостатки:
- Статическая конфигурация. Иногда требуется быстро поправить конфигурацию в production'е, минуя все защитные механизмы. В рамках этого подхода это может быть сложнее. По крайней мере компиляция и автоматическое развёртывание всё равно потребуются. Это одновременно и полезная особенность подхода и недостаток в некоторых случаях.
- Генерация конфигурации. В случае, если конфигурационный файл генерируется автоматическим инстументом, могут потребоваться дополнительные усилия по интеграции скрипта сборки.
- Инструментарий. В настоящее время утилиты и методики, предназначенные для работы с конфигурацией, основаны на текстовых файлах. Не все такие утилиты/методики будут доступны в случае компилируемой конфигурации.
- Требуется изменение взглядов. Разработчики и DevOps привыкли к текстовым файлам. Сама идея компиляции конфигурации может быть несколько неожиданной и непривычной и вызывать отторжение.
- Требуется высококачественный процесс разработки. Чтобы с комфортом пользоваться компилируемой конфигурацией необходима полная автоматизация процесса сборки и развёртывания приложения (CI/CD). В противном случае будет достаточно неудобно.
Остановимся также на ряде ограничений рассмотренного примера, не связанных с идеей компилируемой конфигурации:
- Если мы предоставляем лишнюю конфигурационную информацию, которая не используется узлом, то компилятор не поможет нам обнаружить отсутствие реализации. Эту проблему можно решить, если отказаться от Cake Pattern'а и использовать более жесткие типы, например,
HListили алгебраические типы данных (case class'ы) для представления конфигурации. - В файле конфигурации имеются строки, не относящиеся собственно к конфигурации: (
package,import, объявления объектов;override def'ы для параметров, имеющих значения по умолчанию). Частично можно этого избежать, если реализовать свой DSL. Кроме того, другие виды конфигурации (например, XML), также накладывают определённые ограничения на структуру файла. - В рамках этого поста мы не рассматриваем динамическую реконфигурацию кластера похожих узлов.
Заключение
В этом посте мы рассмотрели идею представления конфигурации в исходном коде с использованием развитых возможностей системы типов Scala. Такой подход может найти применение в различных приложениях в качестве замены традиционным способам конфигурирования на основе xml- или текстовых файлов. Несмотря на то, что наш пример реализован на Scala, те же идеи можно перенести на другие компилируемые языки (такие как Kotlin, C#, Swift, ...). Этот подход можно опробовать в одном из следующих проектов, и, в случае, если он не подойдёт, перейти к текстовым файла, добавив отсутствующие детали.
Естественно, компилируемая конфигурация требует высококачественного процесса разработки. Взамен обеспечивается высокое качество и надёжность конфигураций.
Рассмотренный подход может быть расширен:
- Можно использовать макросы для выполнения проверок во время компиляции.
- Можно реализовать DSL для представления конфигурации в доступном конечным пользователям виде.
- Можно реализовать динамическое управление ресурсами с автоматической подстройкой конфигурации. Например, при изменении количества узлов в кластере требуется, чтобы (1) каждый узел получил немного отличающуюся конфигурацию; (2) менеджер кластера получал сведения о новых узлах.
Благодарности
Хотелось бы поблагодарить Андрея Саксонова, Павла Попова и Антона Нехаева за конструктивную критику черновика статьи.

