Комментарии 134
int fibonacci(int position)
{
if (position < 2)
{
return 1;
}
int previousButOne = 1;
int previous = 1;
int answer = 2;
for (int n = 2; n < position; ++n)
{
previousButOne = previous;
previous = answer;
answer = previous + previousButOne;
}
return answer;
}Если платят за строку кода — норм конечно, но все же нам лично всегда удобнее компактный код, когда можно больше обозреть на одном экране
int fibonacci(int position) {
if (position < 2) return 1;
int previousButOne = 1, previous = 1, answer = 2;
for (int n = 2; n < position; ++n) {
previousButOne = previous;
previous = answer;
answer = previous + previousButOne;
}
return answer;
}Компактный код по сути так же очевиден, а т.к. перед глазами находится больше кода сразу, то не приходится мотать туда сюда для понимания большого участка.
p.s.: Ох сейчас огребем снова:) Постоянный холивар на эту тему с коллегами.
Код должен легко читаться простым беглым взглядом. Ваш требует внимательно его просматривать, чтобы не пропустить что-то.
ХЗ. У меня от вашего варианта глаза выпадают, потому что логика и данные слипаются в одну кучу. Логика отдельно, данные отдельно.
If-ы в одну строку да ещё и без скобок породили столько багов тупейших на моей памяти, что я уже даже не представляю зачем так вообще можно писать.
Я уж не говорю, что при такой расстановке скобок следить за тем где блок кода начинается и кончается совершенно не удобно, но это уже точно из разряда разных фломастеров + особенности традиций языка.
В общем, на мой взгляд, ваш вариант — это прямо квинтэссенция того, как писать не надо.
Тут ещё нюанс в блоке «Пишите короткие функции. В них легче разбираться.». Мне тоже больше нравится, когда { на отдельной строке, но например функция тогда не влезает на экран. Если же писать { в одну строку то размер визуально меньше, проще охватить взглядом. И ещё нюанс — если код линейный, но получается например на 10 экранов, мой опыт показал что делить на функции это только снижать читаемость. Есть точка входа, есть точка выхода, вызовы всего кода 1 раз (что не 1 — уже вынесено), но код вышел в 10 экранов. При этом он легко читается, легко отлаживается, а попытки разбить на подфункции только сломали читаемость и всё.
При этом он легко читается, легко отлаживается, а попытки разбить на подфункции только сломали читаемость и всёЗначит, не умеете бить на подфункции.
2. человек пишет код на 10 экранов и считает, что тот легко читаем.
Ответ один — напиши тест.
Например однострочные ifы — прямой путь к ошибкам из-за добавления новых строк с забыванием что там нет скобок.
Плюс отсутсвие пустых строк между данными, логикой и обработкой результата (в данном случае просто return), усложняет беглый просмотр этого кода.
Читаемый код имеет структуру, прибитую гвоздями в паскале:
- Сначала информация о данных, над которыми работаем (типы и объекты)
- Потом трансформация этих данных
- Затем конвертация данных в тип возврата (если необходимо) и собственно возврат данных из функции.
В паскале подкачала реализация этого подхода, потому что была сделана слишком фанатично, что аж приходилось переменные под счётчики цикла выделять заранее, например.
Однако сама идея была гениальной и простой. Если в паскале эти блоки разделялись очень явно, то современных языках нужно просто добавить одну пустую строку и всё)
Всем, кто пишет вот такие слипшиеся сплошные куски кода, так и хочется прописать немного курсов Паскаля в резюме))
P.S.
Забавно, но пока что 100% встретившихся мне любителей такого стиля написания кода обычно почти не пишут код в IDE, а используют текстовые редакторы (vim, Atom, vscode, sublime, etc). Разрушьте кто-нибудь мою статистику :}
Ну, это зависит. Например если нужно гарантированно какие-то ресурсы освобождать при выходе из любой точки функции, то вместо множественного return может даже множественный go to потребоваться, и это не антипаттерн ни разу, в том числе в приличных домах (см. Linux core style guide). Правда это больше про Си, но все же.
Скорее должно быть C++-подобные (но не Cи!) — C#, Java, JS etc
Почему не Си?
Потому что в Си не везде можно нормально использовать in-place конструирование для составных типов, как в случае с более продвинутыми языками. Каскады инициализаций, с переходами же к каскадам деинициализаций, ручное управление памятью играют не на руку — лучше иметь кучку указателей в одном месте, нежели разбросанных где-то в середине функции.
То есть
void* someFunc() {
struct A* a = NULL;
struct B* b = NULL;
if (init_a(a) < 0) {
return NULL;
}
if (init_b(b)) {
return NULL;
}
/// пару десятков строк функционала спустя
void* ret = (void*)a->some(b);
deinit_a(a);
deinit_b(b);
return ret;
}на мой взгляд несколько удобнее чем
void* someFunc() {
struct A* a = NULL;
if (init_a(a) < 0) {
return NULL;
}
struct B* b = NULL;
if (init_b(b)) {
return NULL;
}
/// пару десятков строк функционала спустя
void* ret = (void*)a->some(b);
deinit_a(a);
deinit_b(b);
return ret;
}т.к. сразу видно потенциальное количество точек отказа. В С++ и прочих же таких проблем заметно меньше — тебе умные указатели, и конструкторы которые в памяти конструируют не отходя от стека, и области видимости логически чуть более инкапсулированны, и статические проверки, встроенные в язык.
Например, если мне не изменяет память ипользование var в js объявляло переменную в глобальном скоупе, с приходом let и constони наконец стали локальными и чем ближе к использованию переменная, тем отказоустойчивей и выгоднее оно в плане использования памяти.
Общий посыл примерно такой, но естественно есть нюансы и некоторые исключения из этих правил.
void* someFunc() {
// function body ...
exitFunc:
if (b != NULL) {
deinit_b(b);
}
if (a != NULL) {
deinit_a(a);
}
return ret;
}
При таком подходе вынос в начало определения всех переменных, которые нужно в конце деинициализировать, как раз имеет смысл. Но, все равно, это скорее как исключение. По умолчанию я бы определял переменные как можно ближе к месту использования даже в С. Но я давно не пишу на С, вполне могу что-то упускать.
void* someFunc() {
struct A* a = NULL;
if (init_a(a) < 0) {
return NULL;
}
void* ret = NULL;
struct B* b = NULL;
if (init_b(b)) {
goto delA;
}
/// пару десятков строк функционала спустя
ret = (void*)a->some(b);
deinit_b(b);
delA: deinit_a(a);
return ret;
}
Не вижу ничего плохого в простых проверках вроде if (!can_go_next) return, по-моему очень даже читабельно, все что больше чем вызов одной функции / выход из функции — в скобки. Ну и на новую строку лучше не переносить, это да.
Да, ошибка тупая. Но посмотрите на статьи о PVS — там 99% ошибок тупые.
решить что выполняемый код ифа идет строчкой ниже.
Если есть такая возможность, ставится пустая строка.
У того же MS в опернсоурсных библиотеках миллион мест типа
public void SomeFunc(arg0, arg1)
{
if(arg0 == null) new ArgumentNullException(nameof(arg0));
if(arg1 == null) new ArgumentNullException(nameof(arg1));
DoSmthng(arg0, arg1);
}
Всё вполне компактно и читабельно.
Миллион раз ловил себя на такой проблеме:
- Читаешь код где всегда if и ниже блок кода с веткой кода
- Попадается однострочный if
- Глаз автоматически смотрит на условие, а потом скользит вниз смотреть что там исполняется в этой ветке
- А там нихрена нет (в лучшем случае) или начинаешь читать код не относящийся вообще к этому if-у как ветку выпоняющуюся под условием этого if-а (что плохо совсем)
- Случается в мозгу cache miss, приходится взглядом возвращаться назад, вчитываться и в общем врубать другие операции, замедляющие беглый просмотр кода.
if(1) return;
printf("...не вызывает вопроса относится ли принт к условию или нет, а заодно такой вариант
if(1) {
return;
}не вызывает проблем увидеть начало условия и его конец (нет необходимости занимать строчку под фигурную скобку).
Не вижу ничего плохого в простых проверках вроде if (!can_go_next) return, по-моему очень даже читабельно
Как в таком варианте поставить брек-поинт на return?
Если следовать этому правилу то и объявление цикла надо разбивать на три строчки
Я бы сделал вот так:
int fibonacci(int position) {
if (position < 2) return 1;
int previousButOne = 1, previous = 1, answer = 2;
for (int n = 2; n < position; ++n) {
previousButOne = previous;
previous = answer;
answer = previous + previousButOne;
}
return answer;
}В «компактном» коде отступы пробельными строками между логическими блоками (объявление переменных, логика. возврат) сразу сходу заметны.
В «воздушном» коде отступы пробельными строками заметны плохо или приходится их делать по две штуки.
У меня java background, мне можно. Там принято фигурную скобку на той же строке открывать.
В C++, имхо, лучше не бежать поперек паровоза и использовать принятый там (и командой) стиль кода. Классика же — холиварность вопроса прямо пропорциональна его незначительности.
Взять меня — я был С++ разработчиком, ставил фигурные скобки с новой строки и обожал табы. При переходе на java пришлось подстроиться под команду и я от этого только выиграл. Например, на ревью было больше вопросов по делу и меньше по всякой фигне типа фигурных скобочек :-)
Но всё таки
int previousButOne = 1;
int previous = 1;
int answer = 2;
Чего тут думать. char.
LPCTSTR pszFolder, pszFilename, pszExtension;Здесь не возникает проблемы с поинтерами, т.к. они уже вынесены в typedef.
Но если возникает сомнения вида:
const auto & var = G_Var, var2 = G_Var2; // avoid this definitionТо не полезу в книжку вспоминать, напишу каждую на отдельной строке.
const auto & var = G_Var;
const auto & var2 = G_Var2; // Thats goodif (position < 2) return 1;ТАК ВЕРСТАЮТ ТОЛЬКО МУДАКИ ©
゚ω゚ノ= /`m´)ノ ~┻━┻ //*´∇`*/ ['_']; o=(゚ー゚) =_=3; c=(゚Θ゚) =(゚ー゚)-(゚ー゚); (゚Д゚) =(゚Θ゚)= (o^_^o)/ (o^_^o);(゚Д゚)={゚Θ゚: '_' ,゚ω゚ノ : ((゚ω゚ノ==3) +'_') [゚Θ゚] ,゚ー゚ノ :(゚ω゚ノ+ '_')[o^_^o -(゚Θ゚)] ,゚Д゚ノ:((゚ー゚==3) +'_')[゚ー゚] }; (゚Д゚) [゚Θ゚] =((゚ω゚ノ==3) +'_') [c^_^o];(゚Д゚) ['c'] = ((゚Д゚)+'_') [ (゚ー゚)+(゚ー゚)-(゚Θ゚) ];(゚Д゚) ['o'] = ((゚Д゚)+'_') [゚Θ゚];(゚o゚)=(゚Д゚) ['c']+(゚Д゚) ['o']+(゚ω゚ノ +'_')[゚Θ゚]+ ((゚ω゚ノ==3) +'_') [゚ー゚] + ((゚Д゚) +'_') [(゚ー゚)+(゚ー゚)]+ ((゚ー゚==3) +'_') [゚Θ゚]+((゚ー゚==3) +'_') [(゚ー゚) - (゚Θ゚)]+(゚Д゚) ['c']+((゚Д゚)+'_') [(゚ー゚)+(゚ー゚)]+ (゚Д゚) ['o']+((゚ー゚==3) +'_') [゚Θ゚];(゚Д゚) ['_'] =(o^_^o) [゚o゚] [゚o゚];(゚ε゚)=((゚ー゚==3) +'_') [゚Θ゚]+ (゚Д゚) .゚Д゚ノ+((゚Д゚)+'_') [(゚ー゚) + (゚ー゚)]+((゚ー゚==3) +'_') [o^_^o -゚Θ゚]+((゚ー゚==3) +'_') [゚Θ゚]+ (゚ω゚ノ +'_') [゚Θ゚]; (゚ー゚)+=(゚Θ゚); (゚Д゚)[゚ε゚]='\\'; (゚Д゚).゚Θ゚ノ=(゚Д゚+ ゚ー゚)[o^_^o -(゚Θ゚)];(o゚ー゚o)=(゚ω゚ノ +'_')[c^_^o];(゚Д゚) [゚o゚]='\"';(゚Д゚) ['_'] ( (゚Д゚) ['_'] (゚ε゚+(゚Д゚)[゚o゚]+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ ((o^_^o) +(o^_^o))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ ((o^_^o) +(o^_^o))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (o^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ ((゚ー゚) + (o^_^o))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ ((o^_^o) +(o^_^o))+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ ((o^_^o) +(o^_^o))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ ((゚ー゚) + (o^_^o))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (o^_^o)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (o^_^o))+ (o^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (o^_^o))+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+((o^_^o) +(o^_^o))+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (o^_^o))+ (o^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ ((o^_^o) +(o^_^o))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ ((゚ー゚) + (o^_^o))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (o^_^o))+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+((o^_^o) +(o^_^o))+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (o^_^o))+ (o^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ ((゚ー゚) + (o^_^o))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (o^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (o^_^o))+ ((o^_^o) +(o^_^o))+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+((o^_^o) +(o^_^o))+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (o^_^o))+ (o^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ ((゚ー゚) + (o^_^o))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (o^_^o)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (o^_^o)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (o^_^o))+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (c^_^o)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (o^_^o))+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (c^_^o)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (o^_^o))+ (o^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ ((o^_^o) +(o^_^o))+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (o^_^o))+ (o^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (o^_^o))+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚o゚]) (゚Θ゚)) ('_');Хорошее логирование сильно упрощает понимание кода.
11. Не стесняйтесь вставлять пустые строки, разделяя смысловые блоки в рамках одной функции
12. Над каждым публичным классом и каждой публичной функцией должен быть комментарий. Да, код самодокументируемый и всё такое, но для этого его надо прочитать и осознать
13. В сложных местах (особенно если у будущего читателя может появиться желание "упростить" код) должен быть комментарий, объясняющий, почему было сделано именно так
14. самодокументируемого кода не бывает, бывает документированный код и недокументированный код
Требование писать комментарий к каждому методу слишком категоричное.
Название метода должно объяснять, что делает метод.
А комментарий — как метод это делает. При этом комментарий нужен только, если реализация метода нетривиальна.
8 пункт с комментарием всего файла выглядит слабо. Я считаю, что 99% программистов будут ожидать, что в файле Foo.java будет реализация класса Foo. Поэтому заголовочные комментарии в большинстве случаев не обязательны.
Вы неправильно понимаете назначение заголовочных комментариев. Как и в остальных комментариях, там должно быть не то, что уже написано в коде, а то, чего в коде, как минимум, явно, нет. Назначение класса (что вовсе не обязано совпадать с тем, что он делает), архитектурные ограничения, поддержка многопоточности, принятые в нем особенности работы с транзакциями и т.п.
В Java-мире учиться писать комментарии можно на примере JRE и spring-core
/* On some laptops (Sony, i'm looking at you) there appears to
* be no direct way of accessing the panel's EDID. The only
* option available to us appears to be to ask ACPI for help..
*
* It's important this check's before trying straps, one of the
* said manufacturer's laptops are configured in such a way
* the nouveau decides an entry in the VBIOS FP mode table is
* valid - it's not (rh#613284)
*/
if (nv_encoder->dcb->lvdsconf.use_acpi_for_edid) {
if ((nv_connector->edid = nouveau_acpi_edid(dev, connector))) {
status = connector_status_connected;
goto out;
}
}У программиста будет аврал при починке бага на проме, и он быстро поменяет код, даже не взглянув на комментарий — всё, ваша документация врёт.
Не обязательно аврал: просто может быть невнимательный человек; конец десятичасового рабочего дня; просто пофигист и т.д.
Проблема такой «документации» в том, что она человекозависима, а значит — ненадёжна, а значит — ей нельзя доверять и мало кто её будет читать, а значит — и писать её не стоит.
Есть, конечно, исключения, когда комментарии писать нужно: если изменения в данном месте могут аукнуться совсем в другом (читатель кода может не знать этого) и если разработчик выбрал какой-то нестандартный/нелогичный подход: надо объяснить будущим поколениям — почему (Ваш пример, как я понимаю, как раз про это).
Всё, других резонов написания комментариев/документации нет.
ага, инициализацию локальных переменных в одну функцию, цикл в другую, оператор return — в третью.
По статье по ссылке — посмотрите сами на его пример отрефакторенного кода. Разве не хочется добавить простора? между методами, внутри метода lines()?
edit: вот ваше сообщение состоит из 3 предложений, и вы все равно разбили их на два абзаца. Чем код хуже?
Я почти всегда прекращаю чтение статьи, если там полно ошибок. Логика проста: если человек за 10 лет не выучил русский язык, то какова вероятность, что он выучит какой-то другой (С, Java, и т.п.) за 2-3 или даже 5 лет практики…
Просто недавно обсуждал одну тему: Разговор был о libc, в частности о musl libc. Так вот, я сказал, что это пример того, как НЕ надо писать код на языке Си.
Ребята походу обиделись:)))
Хотя, я всего-лишь предложил писать код для «обычных» людей, а не «заклинания» для компилятора.
Ваша логика ломается на нескольких моментах
1) Для многих русский не родной язык (Я например из Украины, и в школе не изучал русский)
2) Многих людей он может просто не интересовать, технари спокойно могут отдать приоритет точным наукам.
3) Многие начинают изучать английский и другие языки, из-за чего знания русского может ухудшаться, а если этот человек иммигрировал — то и вообще пропасть.
Если человек не привёл в порядок свой текст — это показатель непрофессионализма. Т.е. отсутствия ответственного отношения к тому, что человек делает.
Оффтопик: а ещё, на мой взгляд, это неуважительное отношение автора к читателям.
clang-format и голова о форматировании перестаёт болеть в 90% случаев.
clang-tidy и уже не напишешь голую константу.
Вот с комментариями вопрос сложнее. Какую пользу в файле Foo.java несет комментарий вида «Foo class implementation»?
Классическим примером того как надо писать код лично для меня стал в далеком 1987 году код операционной системы Minix, где были соблюдены все эти рекомендации. Таким он остается и сегодня.

STOYKA
STOEK
Вот это прям хорошо
А по поводу картинок. Впервые вижу, есть реальный опыт использования и более интересные кейсы?
Конечно, опыт реальный. За основу брал плагин: https://marketplace.visualstudio.com/items?itemName=MsBishop.ImageComments
Пришлось его немного допилить, чтобы можно было copy-paste картинок делать, но даже в том виде, в каком он есть уже комфортнее работать. Есть у меня прога обхода принтеров и снятия с них показаний. Типов 30. На каждый принтер надо было указать из какого места что снимать. Вот такие картинки уже удобнее освежать в памяти:
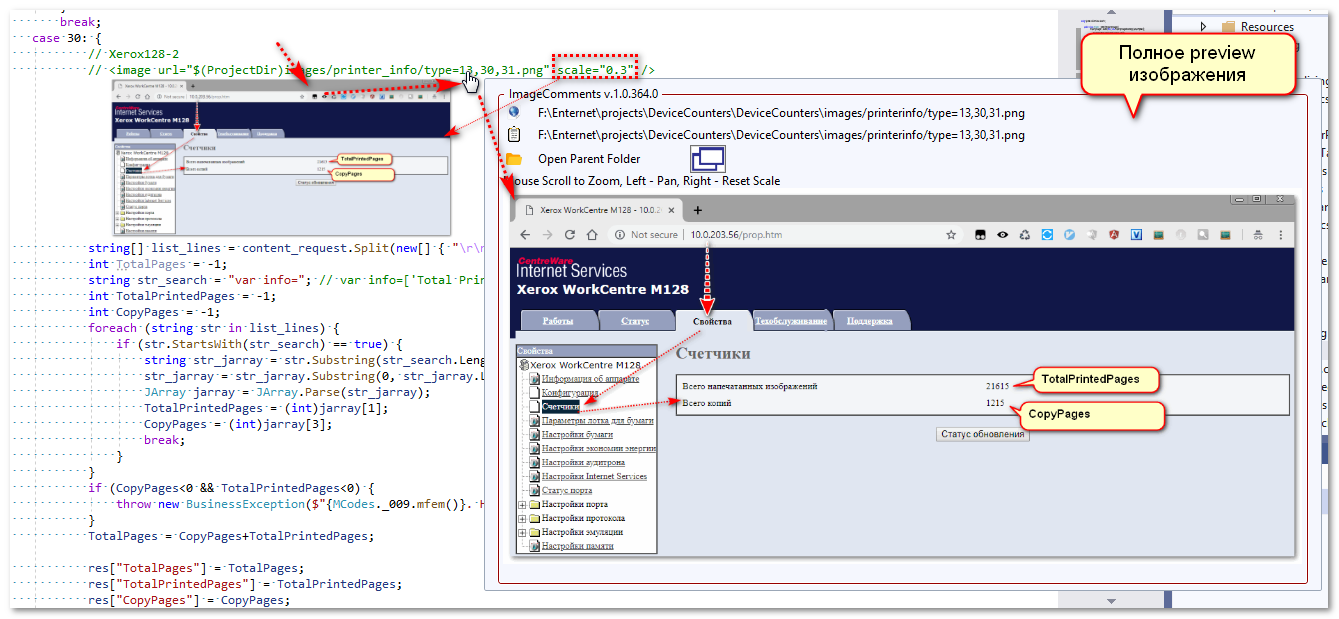
Если что, вот ещё интересный плагин для readme.md под Visual Studio: https://github.com/madskristensen/MarkdownEditor
И как-то на пару они хорошо дополняют друг друга. Один в коде картинки показывает, в другом readme удобно писать. Почти лепота. )
Если всегда — то это жесть.
У меня на поддержке около десятка программ, и всякие плагины. Очень помогает.

Не надо так, серьезно. Никогда.
В README.md или доках почему бы и нет, а в коде слишком много подводных камней. Кто гарантирует, что через пару лет этот код не будет поддерживать любитель vim/emacs, например? Плюс встаёт вопрос, класть ли их в репозиторий (скорее всего раздувая его в разы) или хранить отдельно (рискуя потерять). Да и за то время, которое уходит на снятие скриншота и прописывание урла, можно написать строчек десять текстового комментария.
что через пару лет этот код не будет поддерживать любитель vim/emacs, напримерлично я думаю, что он будет только безумно счастлив увидев хорошо оформленный рисунок, который возможно объяснит ему всё гораздо лучше, чем сухой абстрактный комментарий.
Я хочу быть правильно понятым и не настаиваю на своём стиле комментирования, но надеюсь, что вы согласитесь, что написать хороший комментарий бывает ничуть не проще написания хорошего кода, а так же сделать хорошую картинку и скриншот тоже бывает очень не просто. Но я считаю, что на сегодняшний день отсутствие комментов в виде картинок не позволяет выйти комментированию на качественно новый уровень.
Да и за то время, которое уходит на снятие скриншота и прописывание урлаВот! И это одна из главных проблем создания таких комментариев. Однако, это не значит, что этот недостаток нельзя преодолеть. Разве нет? Вот есть плагин "Image Comments", есть плагин "MarkDown Editor". Если их функции объединить (а эти плагины open source), то время на прописывание url-ов уже становится незначительным и его можно не брать в расчёт. (вставка картинки по Ctrl-V в любом месте кода)
Соберу их в кучку:
Предлагаю в этой ветке собрать еще ссылок на такие же крупные рекоммендации, которые вам известны
- Qt Coding Style
- LLVM Coding Standards
- Форк уже упомянутого Google Style Guide
Лично мне больше всего симпатизирует стиль Qt.
Спрашивается, почему же тогда общепринятым считается стиль с открывающейся фигурной скобкой на той же строке (причем настолько, что в некоторых фирмах такой стиль просто требуют)?
А вообще для каждого более не менее серьёзного проекта (от 1000 срок), я всегда пишу обзор. Словесное описание алгоритмов, структура файлов и т.п. Это не заменяет комментариев в коде, а дополняет их, давая как бы взгляд на проект с высоты птичьего полета.
Сам я начинал с С++ и открывающей скобки на новой строке, но потом долгое время пришлось писать на Java, где принято не переносить открывающую скобку на новую строку. Особой разницы на понимание кода при наличии привычки это не оказывает. А преимущества можно найти и там, и там. Например в первом подходе приятненько, когда соответствующие скобочки на одном уровне, зато во втором подходе блок кода зрительно прилеплен к соответствующему условию и отделен от последующих блоков.
Гораздо хуже, когда разные части одного и тоже проекта написаны в разном стиле.
Кстати, если применить все правила наоборот, то получится очень красиво обфусцированный код с минимальными вложениями времени.
Надо выбираться из помойки, а не делать помойку чуть более опрятной. Когда код должным образом декомпозирован, такого вопроса как писать один return или два вообще не возникает.
Вот таким вот образом condition c двумя return-ами отделяется от вычисления, вуаля — проблема исчерпана.
int fibonacci(int position)
{
return position < 2 ? 1 : fibonacciHigh(position);
}
int fibonacciHigh(int position)
{
int answer = 1;
int previousButOne = 1;
int previous = 1;
for (int n = 2; n < position; ++n)
{
previousButOne = previous;
previous = answer;
answer = previous + previousButOne;
}
return answer;
}
PS правда может возникнуть проблема именования функций, но это меньшее зло
PS правда может возникнуть проблема именования функций, но это меньшее зло
Это как раз иногда большее зло. Например, в вашем примере, если бы я заранее не знал алгоритма расчета чисел Фибоначчи (и, с-но, что там должно быть внутри fibonacciHigh), то ваш код вызвал бы у меня… ммм… скажем так, очень сильное недоумение :)
В рамках одной ф-и же такой проблемы нет, все сразу ясно.
Надо все-таки не забывать, что код должен быть понятным в первую очередь для того, кто не знает, что он делает :)
Кстати тот факт, что вы и сами сразу обратили внимание на нейминг после своего варианта — весьма красноречив ;)
Очень хорошая привычка — перед каждым коммитом выполнять diff.
Уж сколько раз твердили миру про то, что имелось в виду под SESE, а толку чуть: https://softwareengineering.stackexchange.com/q/118703/242401.
Снабжайте файлы заголовками
/*********************************************************
* File: Foo.java
* Purpose: Foo class implementation
* Notice: © 1066 Foo industries. All rights reserved.
********************************************************/
Тот, кому придется сопровождать этот файл, получит хорошее представление о том, с чем он имеет дело.
Ну да, вот прочёл такой заголовок — и сразу легче стало.
Писать название файла в файле — бесценно.
большинство софтверных компаний по юридическим соображениям требует, чтобы в каждом файле с исходным кодом было заявление об авторских правах.
Никогда о таком даже не слышал. И я очень сильно сомневаюсь, что эта информация поможет в представлении о том, с чем имеем дело.
Поэтому комментарий внутри функции, это первый признак, что что-то пошло не так.
При условии, что в команде только русские или только китайцы, и проекты для внутреннего рынка. Таких проектов много
Это перебор)
Короче говоря, моё ИМХО — программисты должны знать английский язык, и кодить, изначально предполагая, что с их кодом могут работать и иноязычные разработчики. Исторически получилось так, что как минимум в IT английский стал международным языком. Во всяком случае, такого количества документации, какое есть на английском языке, даже приблизительно нет на русском, китайском или испанском. И если программист не знает английский язык, его уже можно считать ограниченным программистом.
Пишите короткие функции. В них легче разбираться. Можно сориентироваться в сложном алгоритме, если он разбит на мелкие фрагменты с содержательными именами, но это не удастся сделать в бесформенной массе кода.Пока функции были именно функциями, так оно и было. Но сейчас-то они методы, и описаны в лучшем случае в классах, а в худшем — в прототипах, причём композицию конечно же предпочитают наследованию, а рабочая структура программы собирается только в рантайме. И хрена с два вы поймёте, что и в каком порядке из этих 100500 функций вызывается, потому что из кода оно не очевидно, всё завёрнуто в сервис локаторы и фабрики. Сейчас вот ещё ECS (Entity-Component-System) стремительно входит в моду и пихается куда ни попадя, удачи вам разбираться в таком коде…
Совсем плохо, если поверх всего этого там ещё и асинхронка с промисами, генераторами и подобным. Тут ход выполнения вообще головоломка, и чтобы мысленно «собрать» из пачки функций-однострочников полный алгоритм, без дебаггера вообще не обойтись.
item, если результирующий объект удалось создать; true, если во время работы не возникли ошибки; false, если полученные параметры имеют некорректное значение.— не надо так.
Капец, вы серьезно?
Теперь ждём, когда кто-то опубликует пересказ "Букваря".
Ну все эти вещи какие-то пересказывания. Мне например нравится вот этот пересказ:
NASA C style guide
Похоже, что многие современные индусы программисты в авиаиндустрии его даже не видели.
10 принципов самодокументируемого кода