Недавно вышла одна очень интересная статья "Speaker Recognition from raw waveform with SincNet", в которой была описана end-to-end архитектура нейронной сети для распознавания говорящего по голосу. Ключевая особенность этой архитектуры — специальные одномерные сверточные слои, которые имеют всего два параметра с четкой интерпретацией. Интерпретируемость параметров нейронной сети — дело довольно затруднительное, поэтому эта статья привлекла мой интерес.

Если заинтересовало описание идеи этой статьи, а также почему эта идея близка по смыслу к построению мел-спектрограмм, то милости прошу под кат.
Отмечу, что все изображения, используемые в этом посте либо взяты из исходной статьи, либо их можно получить с помощью Jupyter Notebook'а, хранящегося в этом репозитории.
Авторами описываемой статьи был выложен исходный код на гитхаб, с ним можно ознакомиться здесь.
Мел-спектрограммы
Чтобы понять суть этой статьи, давайте сначала вспомним, что такое мел-спектрограмма, как ее получить и в чем ее смысл. Если эта тема вам знакома, то эта часть будет не очень интересной. Ее вычисляют по обычной спектрограмме, построенной с помощью оконного преобразования Фурье:
![$F(k, m) = \sum\limits_{n=0}^{L - 1} x[n+m] w[n] e^{-i{{2 \pi}\over{L}} k n}$](https://habrastorage.org/getpro/habr/formulas/662/484/ec2/662484ec2384f6d052df03a58853ed44.svg)
Суть этой операции в последовательном применении преобразования Фурье к коротким кусочкам речевого сигнала, домноженным на некоторую оконную функцию. Результат применения оконного преобразования — это матрица, где каждый столбец является спектром короткого участка исходного сигнала. Посмотрите на пример ниже:

Эксперименты ученых показали, что человеческое ухо более чувствительно к изменениям звука на низких частотах, чем на высоких. То есть, если частота звука изменится со 100 Гц на 120 Гц, человек с очень высокой вероятностью заметит это изменение. А вот если частота изменится с 10000 Гц на 10020 Гц, это изменение мы вряд ли сможем уловить.
В связи с этим была введена новая единица измерения высоты звука — мел. Она основана на психо-физиологическом восприятии звука человеком, и логарифмически зависит от частоты:

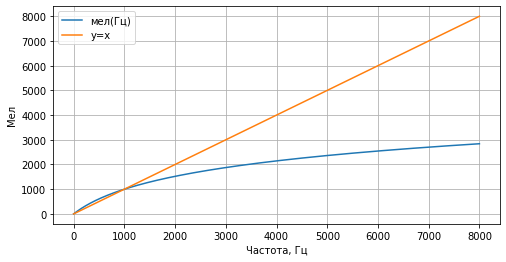
Собственно, мел-спектрограмма — это обычная спектрограмма, где частота выражена не в Гц, а в мелах. Переход к мелам осуществляется с помощью применения мел-фильтров к исходной спектрограмме. Мел-фильтры представляют из себя треугольные функции, равномерно распределенные на мел-шкале. В качестве примера здесь изображены 10 мел-фильтров (на практике их берут больше, здесь их мало для наглядности):
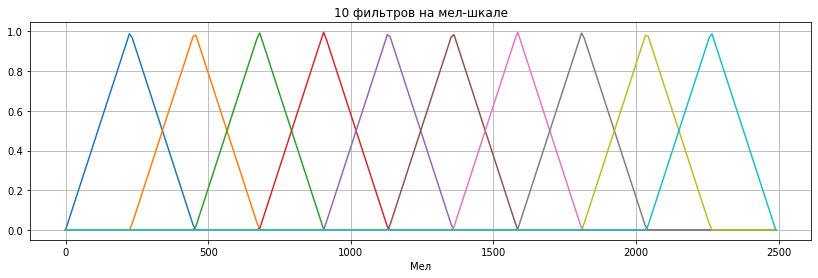
При переводе в частотную шкалу, те же самые фильтры будут выглядеть так:

Каждый столбец исходной спектрограммы скалярно умножается на каждый мел-фильтр (размещенный на частотной шкале), после чего получается вектор чисел, по размеру равный количеству фильтров. На картинке ниже изображен один из столбцов спектрограммы (значения амплитуды переведены в логарифмический масштаб для наглядности, то, что на картинке кодировалось цветом, здесь отражено по оси ординат) и два мел-фильтра, с помощью которых строится мел-спектрограмма:

В результате таких преобразований значения из низких частот спектрограммы остаются практически неизменными на мел-спектре, а в высоких частотах происходит усреднение значений из более широкого диапазона. В качестве примера предлагаю посмотреть на мел-спектрограмму, построенную по предыдущей спектрограмме с использованием 64 мел-фильтров:
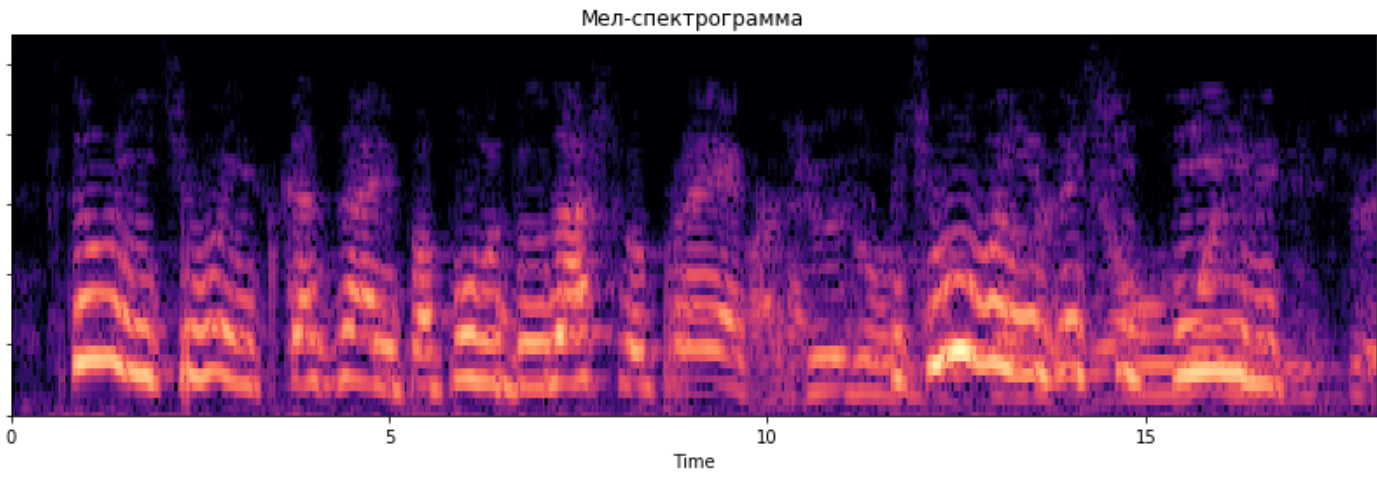
Резюмируя все вышесказанное: на мел-спектрограмме сохраняется больше информации, которая хорошо воспринимается и различается человеком, чем на обычной спектрограмме. Иными словами, такое представление звука больше сфокусировано на низких частотах, и меньше — на высоких.
При чем же здесь SincNet?
Вспомним, что мел-шкала была создана на основе человеческого психо-физического восприятия звука. Но что если мы хотим выбрать другие полосы частот, которые нас интересуют больше чем остальные в какой-либо конкретной задаче? Как выбрать самый лучший набор фильтров для решения какой-либо задачи?
Именно эту задачу и решает предложенная авторами архитектура.
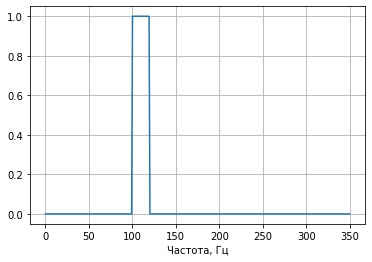
Авторы рассматривают в качестве фильтра следующую функцию:

 в этой формуле — это прямоугольная функция. Такой фильтр задает диапазон частот от
в этой формуле — это прямоугольная функция. Такой фильтр задает диапазон частот от  до
до  . Вот ее график:
. Вот ее график:
С помощью обратного преобразования Фурье для этой функции можно получить ее аналог во временной области:



Функция  — это импульсная характеристика идеального полосового фильтра, который нельзя реализовать практически, поэтому авторы усекают эту функцию окном Хэмминга. В цифровой обработке сигналов такой подход называется синтезом фильтров методом окон.
— это импульсная характеристика идеального полосового фильтра, который нельзя реализовать практически, поэтому авторы усекают эту функцию окном Хэмминга. В цифровой обработке сигналов такой подход называется синтезом фильтров методом окон.
Усеченный окном вариант функции  авторы предлагают использовать в качестве шаблона для всех сверток, применяемых к сырым аудио данным. Эта функция дифференцируема по параметрам и , а значит ее можно использовать при оптимизации параметров сети методом обратного распространения ошибки.
авторы предлагают использовать в качестве шаблона для всех сверток, применяемых к сырым аудио данным. Эта функция дифференцируема по параметрам и , а значит ее можно использовать при оптимизации параметров сети методом обратного распространения ошибки.
По теореме о свертке, свертка исходного сигнала с функцией эквивалентна умножению спектра исходного сигнала на функцию  . Грубо говоря, выполняя свертку исходного сигнала с функцией , мы "обращаем внимание" нейронной сети на данный диапазон частот в рассматриваемом сигнале.
. Грубо говоря, выполняя свертку исходного сигнала с функцией , мы "обращаем внимание" нейронной сети на данный диапазон частот в рассматриваемом сигнале.
Конечно, здесь не применяется преобразование Фурье и явно нейросети не сообщаются конкретные значения спектра в диапазоне ![$[f_1;f_2]$](https://habrastorage.org/getpro/habr/formulas/c7e/b26/d3b/c7eb26d3b3608877816e9504fa56148c.svg) . По всей видимости, задача извлечения спектральных характеристик возлагается на следующие блоки, расположенные в нейронной сети.
. По всей видимости, задача извлечения спектральных характеристик возлагается на следующие блоки, расположенные в нейронной сети.
Из достоинств такого подхода, авторы отмечают следующее:
- Быстрая сходимость
- Гораздо меньшее количество параметров. В классическом сверточном блоке количество параметров равно длине свертки. При описанном же подходе, количество параметров не зависит от длины свертки и равно 2
- Интерпретируемость параметров
Выводы
Фильтров, с помощью которых преобразуются спектрограммы, существуют много. Например, кроме описанных мел-фильтров, есть еще барк-фильтры (почитать можно здесь и здесь). По крайней мере барк — это тоже психофизическая величина, подобранная "под человека".
В своем исследовании авторы предложили метод, по которому можно заставить нейронную сеть самостоятельно выбрать наиболее подходящие диапазоны частот в процессе обучения в зависимости от набора данных. Как по мне, это очень похоже на процесс построения мел-спектрограммы, при котором больший приоритет отдается низким частотам. Вот только мел-спектрограммы придумали на основе человеческого восприятия звука, а в предложенном методе нейросеть сама решает, что важно, а что нет.

