Меня зовут Иван Бондаренко. Я занимаюсь алгоритмами машинного обучения для анализа текстов и устной речи примерно с 2005 года. Сейчас работаю в Московском Физтехе ведущим научным разработчиком лаборатории бизнес-решений на основе Центра компетенций НТИ по Искусственному интеллекту МФТИ и в компании Data Monsters, которая занимается вопросами практической разработки диалоговых систем для решения тех или иных задач в индустрии. Также немного преподаю у нас в университете. Мой рассказ будет посвящен тому, что такое чат-бот, как алгоритмы машинного обучения и другие подходы применяются для автоматизации общения человека и компьютера и где это может быть реализовано.
Полную версию моего выступления на «Ночи научных историй» можно посмотреть в видеозаписи, а краткие тезисы я приведу в тексте ниже.

В первую очередь, алгоритмы взаимодействия с человеком находят успешное применение в call-центрах. Работа оператора call-центра очень тяжелая и дорогостоящая. Более того, во многих ситуациях полностью решить проблему общения человека и компьютера практически невозможно. Одно дело, когда мы работаем с банком, у которого, как правило, несколько тысяч клиентов. Можно набрать штат сотрудников call-центра, который бы обслуживал этих клиентов и беседовал с ними. Но когда мы решаем более масштабные задачи (например, производим смартфоны или какую-то другую бытовую электронику), у нас клиентов не несколько тысяч, а несколько десятков миллионов по всему миру. И мы хотим понимать, какие проблемы с нашей продукцией есть у людей. Пользователи, как правило, делятся друг с другом информацией на форумах либо пишут в службу поддержки производителя смартфонов. Живые операторы не смогут справиться с работой по огромной клиентской базе, и здесь на помощь приходят алгоритмы, которые могут работать в многоканальном режиме, обслуживая огромное количество людей.
Для решения подобных задач, для построения алгоритмов диалоговых систем, которые могли бы взаимодействовать с человеком и извлекать смысл, важную информацию из произвольных сообщений, существует целое направление в области компьютерной лингвистики – анализ текстов на естественном языке. Робот должен уметь читать, понимать, слушать, говорить и так далее. Это направление – Natural Language Processing (анализ текста на естественном языке) – распадается на несколько частей.
Когда бот общается с человеком и человек что-то пишет боту, нужно понять, что написано, что хотел пользователь, о чем он упоминал в своей речи. Понимание намерений пользователя, так называемого интента – чего человек хочет: перевыпустить банковскую карту или заказать пиццу. И выделение именованных сущностей, то есть вещей, о которых конкретно говорит пользователь: если это пицца, то «Маргарита» или «Гавайская», если карта, то какая система – MasterCard, Мир и так далее.

И, наконец, понимание тональности сообщения – в каком эмоциональном состоянии находится человек. Алгоритм должен уметь детектировать, в какой тональности написано сообщение, либо это новостной текст, либо это сообщение от человека, который общается с нашим ботом, для того чтобы адекватным образом реагировать на тональность.

Порождение текста (Natural Language Generation) – адекватная реакция на человеческий запрос таким же человеческим языком (естественным), а не сложной табличкой и не формальными фразами.
Распознавание и синтез речи (Speech-to-Text and Text-to-Speech). Если чат-бот не просто переписывается с человеком, а говорит и слушает, нужно научить его понимать устную речь, звуковые колебания преобразовывать в текст, чтобы потом модулем понимания текста этот текст анализировать, и из текста-ответа генерировать, в свою очередь, звуковые колебания, которые потом услышит человек, абонент.
В чат-ботах можно выделить несколько ключевых архитектур.
Чат-бот, отвечающий на наиболее часто задаваемые вопросы (FAQ-чатбот) – самый простой вариант. Мы всегда можем сформулировать набор типовых вопросов, которые задают люди. Для сайта по доставке готовой еды, как правило, это вопросы: «сколько будет стоить доставка», «доставляете ли вы в Первомайский район», и пр. Можно их сгруппировать по нескольким классам, интентам, пользовательским намерениям. И для каждого интента подобрать типовые ответы.
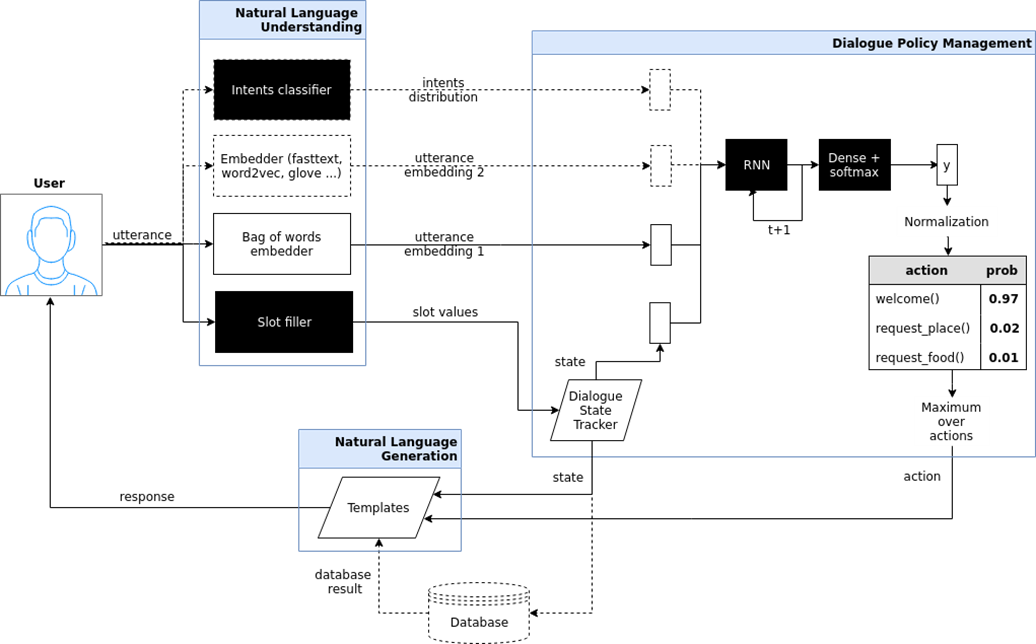
Целенаправленный чат-бот (goal oriented bot). Я здесь попытался показать архитектуру подобного чат-бота, который реализован в проекте iPavlov. iPavlov – это проект по созданию разговорного искусствен��ого интеллекта. В частности, целенаправленный чат-бот помогает пользователю достичь какой-то цели (например, забронировать столик в ресторане или заказать пиццу, или что-то узнать о проблемах в банке). Речь идет не просто об ответе на вопрос (вопрос-ответ – без всякого контекста). У целенаправленного чат-бота есть модуль понимания текста, управления диалогом и модуль генерации ответов.
Чат-боты вопросно-ответной системы question answering system и просто «болталки» (chit chat bot). Если два предыдущих типа чат-ботов либо отвечают на наиболее часто задаваемые вопросы, либо ведут пользователя по графу диалогов, в конце концов, помогая забронировать ресторан, выясняя, что хочет пользователь, китайскую или итальянскую кухню и т.д., то вопросно-ответная система – это другой тип чат-бота. Задача такого чат-бота – не двигаться по графу диалога и не просто классифицировать намерения пользователя, а обеспечивать информационный поиск – находить наиболее релевантный документ, соответствующий вопросу человека, и место в документе, где содержится ответ. Например, сотрудники крупного ритейлера вместо того, чтобы заучивать наизусть инструкции, регламентирующие работу, либо искать ответ, куда ставить гречку, задают вопрос такому чат-боту на основе вопросно-ответной системы.
Распознавание интентов, выделение именованных сущностей, поиск в документах и поиск мест в документе, которые соответствуют семантике вопроса – все это без машинного обучения, без некого статистического анализа реализовать невозможно. Поэтому в основе современных чат-ботов лежит машинное обучение –методы задач, аппроксимации некой скрытой закономерности, которая есть в больших массивах данных и выявление этих закономерностей. Такой подход имеет смысл применять, когда закономерности, задачи есть, но простую формулу, формализм для описания этой закономерности придумать невозможно.
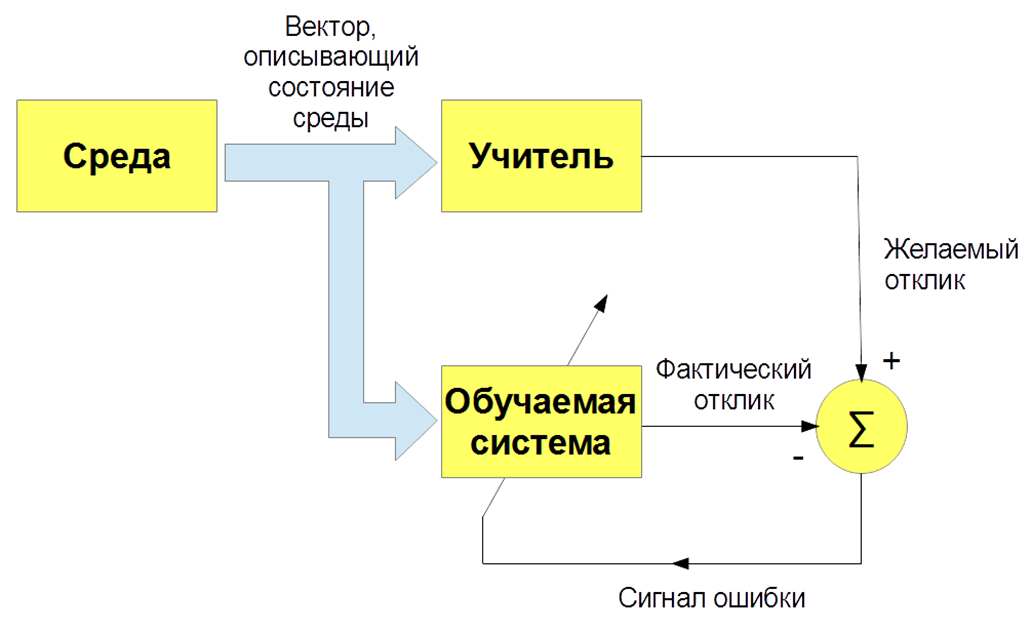
Существует несколько видов машинного обучения: с учителем (supervised learning), без учителя (unsupervised learning), с подкреплением (reinforcement learning). Нас интересует, прежде всего, задача обучения с учителем – когда есть входные изображения и указания (метки) учителя и классификация этих изображений. Либо входные речевые сигналы и их классификация. И мы учим нашего бота, наш алгоритм воспроизводить работу учителя.
О’кей, вроде бы все круто. А как научить компьютер понимать тексты? Текст – это сложный объект, и как буквы превратить в числа и придумать векторное описание текста? Есть самый простой вариант – «мешок слов». Мы задаем словарь всей системы, например, все слова, которые есть в русском языке, и формулируем вот такие очень разреженные вектора с частотами слов. Этот вариант хорош для простых вопросов, но для более сложных задач он не годится.
В 2013 году произошла в некотором роде революция в моделировании слов и текстов. Томас Миколов предложил специальный подход эффективного векторного представления слов, основанный на дистрибутивной гипотезе. Если разные слова встречаются в одном и том же контексте, значит, они имеют что-то общее. Например: «Ученые провели анализ алгоритмов» и «Ученые провели исследование алгоритмов». Так, «Анализ» и «исследование» являются синонимами и обозначают примерно одно и то же. Поэтому можно научить специальную нейронную сеть прогнозировать слово по контексту, либо контекст по слову.
Наконец, как мы обучаем? Для того чтобы обучить бота понимать интенты, истинные намерения, нужно вручную разметить кучу текстов с помощью специальных программ. Чтобы научить бота понимать именованные сущности – имя человека, название фирмы, локация – тоже нужно размещать тексты. Соответственно, с одной стороны, алгоритм обучения с учителем наиболее эффективный, он позволяет создавать эффективную распознающую систему, но, с другой стороны, возникает проблема: нужны большие размеченные дата-сеты, а это делать дорого и долго. В процессе разметки дата-сетов могут быть ошибки, вызванные человеческим фактором.
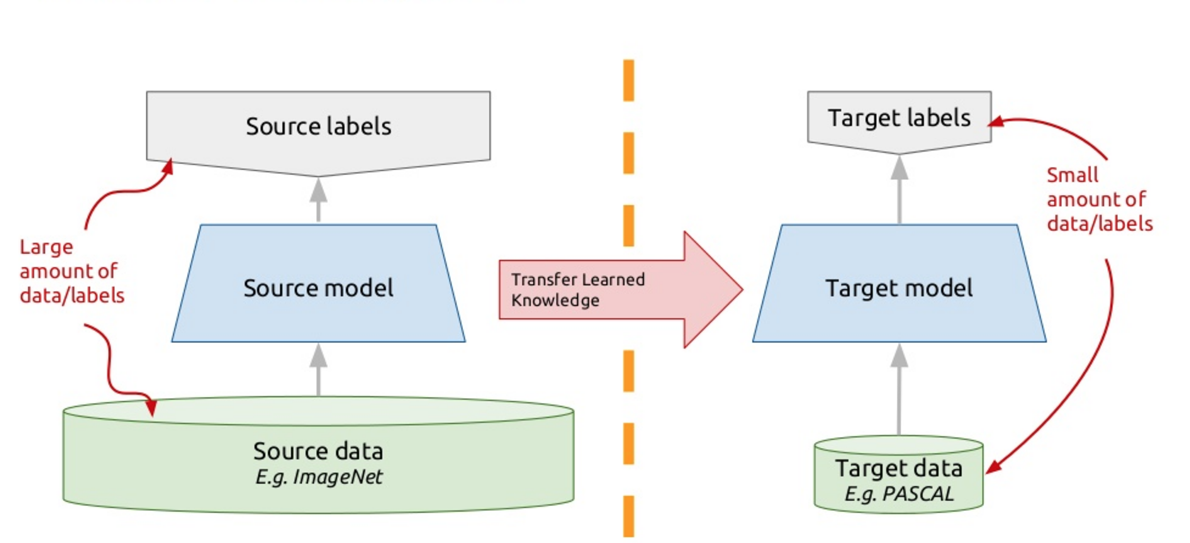
Для решения этой проблемы в современных чат-ботах применяют так называемый перенос обучения – transfer learning. Те, кто знают много иностранных языков, наверняка замечали такой нюанс, что очередной иностранный язык учить легче, чем первый. Собственно, когда вы изучаете какую-то новую задачу, то пытаетесь использовать для этого свой прошлый опыт. Так вот, transfer learning (перенос обучения) как раз основан на этом принципе: мы обучаем алгоритм решать одну задачу, для которой у нас есть большой дата-сет. А потом этот обученный алгоритм (то есть берем алгоритм не с нуля, а обученный решению другой задачи), дообучаем решать нашу задачу. Таким образом, мы получаем эффективное решение с использованием небольших различных данных.
Одна из таких моделей – это ELMo (Embeddings from Language Models), как ELMo из Улицы Сезам. Мы используем рекуррентные нейронные сети, они имеют память и могут обрабатывать последовательности. Например: «Программист Вася любит пиво. Каждый вечер после работы он заходит в «Джонатан» и пропускает бокал-другой». Так вот, он – это кто? Он – это вечер, он – это пиво, или он – это программист Вася? Нейронная сеть, которая обрабатывает слова, как элементы последовательности, учитывая контекст, рекуррентная нейронная сеть, может понять взаимосвязи, решить эту задачу и выделить какую-то семантику.
Мы обучаем такую глубокую нейронную сеть моделировать тексты. Формально это задача обучения с учителем, но учителем у нас выступает сам неразмеченный текст. Следующее слово в тексте является учителем по отношению ко всем предыдущим. Таким образом, можем использовать гигабайты, десятки гигабайт текстов, обучать эффективные модели, которые выделяет семантика в этих текстах. И потом, когда мы используем модель Embeddings from Language Models (ELMo) в режиме вывода, мы подаем слово с учетом контекста. Не просто stick, a let's stick. Смотрим, что нейронная сеть генерирует в этот момент времени, какие сигналы. Эти сигналы мы катанируем и получаем векторное представление слова в конкретном тексте, с учетом его конкретной сематической значимости.
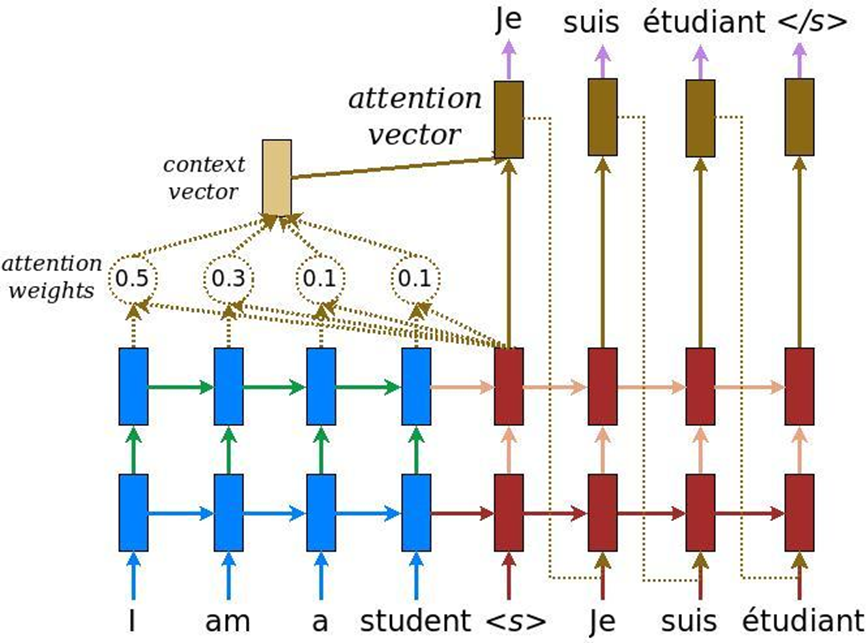
В анализе текстов есть еще одна особенность: когда решается задача машинного перевода, один и тот же смысл одним количеством слов на английском может быть передан и другим количеством слов на русском. Соответственно, идет не линейное сопоставление, и нам необходим механизм, который бы акцентировал внимание на тех или иных кусочках текста, чтобы адекватно их перевести на другой язык. Изначально внимание было придумано для машинного перевода – задача преобразования одного текста в другой с обычными рекуррентными нейронными системами. В это мы добавляем специальный слой внимания, который в каждый момент времени оценивает, какое слово нам сейчас важно.
Но потом ребята из Google подумали, а почему не использовать механизм внимания вообще без рекуррентных нейронных сетей – только внимание. И придумали архитектуру, которая называется трансформер (BERT (Bidirectional Encoder Representations from Transformers)).

На базе такой архитектуры, когда есть только многоголовое внимание, были придуманы специальные алгоритмы, которые тоже могут анализировать взаимосвязи слов в текстах, взаимосвязи текстов друг с другом – как это делает ELMo, только более хитро. Во-первых, это более крутая и сложная сеть. Во-вторых, мы решаем одновременно две задачи, а не одну, как в случае с ELMo – языковое моделирование, прогнозирование. Мы пытаемся восстановить скрытые слова в тексте и восстановить связи между текстами. То есть, допустим: «Программист Вася любит пиво. Каждый вечер он ходит в бар». Два текста связаны между собой. «Программист Вася любит пиво. Журавли осенью улетают на юг» – это два несвязанных текста. Опять-таки, эту информацию можно извлечь из неразмеченных текстов, обучить BERT и получить очень крутые результаты.
Об этом в ноябре прошлого года была опубликована статья «Attention Is All You Need», которую очень я очень рекомендую прочитать. На данный момент это является самым крутым результатом в области анализа текстов для решения разных задач: для классификации текста (распознавание тональности, намерений пользователя); для вопросно-ответных систем; для распознавания именованных сущностей и так далее. Современные диалоговые системы используют BERT, предобученные контекстные эмбеддинги (ELMo или BERT) для того, чтобы понять, что хочет пользователь. Но модуль управления диалогом по-прежнему часто проектируется на основе правил, потому что конкретный диалог может быть очень зависим от предмета или даже от задачи.
Полную версию моего выступления на «Ночи научных историй» можно посмотреть в видеозаписи, а краткие тезисы я приведу в тексте ниже.
Возможности алгоритмов
В первую очередь, алгоритмы взаимодействия с человеком находят успешное применение в call-центрах. Работа оператора call-центра очень тяжелая и дорогостоящая. Более того, во многих ситуациях полностью решить проблему общения человека и компьютера практически невозможно. Одно дело, когда мы работаем с банком, у которого, как правило, несколько тысяч клиентов. Можно набрать штат сотрудников call-центра, который бы обслуживал этих клиентов и беседовал с ними. Но когда мы решаем более масштабные задачи (например, производим смартфоны или какую-то другую бытовую электронику), у нас клиентов не несколько тысяч, а несколько десятков миллионов по всему миру. И мы хотим понимать, какие проблемы с нашей продукцией есть у людей. Пользователи, как правило, делятся друг с другом информацией на форумах либо пишут в службу поддержки производителя смартфонов. Живые операторы не смогут справиться с работой по огромной клиентской базе, и здесь на помощь приходят алгоритмы, которые могут работать в многоканальном режиме, обслуживая огромное количество людей.
Для решения подобных задач, для построения алгоритмов диалоговых систем, которые могли бы взаимодействовать с человеком и извлекать смысл, важную информацию из произвольных сообщений, существует целое направление в области компьютерной лингвистики – анализ текстов на естественном языке. Робот должен уметь читать, понимать, слушать, говорить и так далее. Это направление – Natural Language Processing (анализ текста на естественном языке) – распадается на несколько частей.
Понимание текста (Natural Language Understanding, NLU).
Когда бот общается с человеком и человек что-то пишет боту, нужно понять, что написано, что хотел пользователь, о чем он упоминал в своей речи. Понимание намерений пользователя, так называемого интента – чего человек хочет: перевыпустить банковскую карту или заказать пиццу. И выделение именованных сущностей, то есть вещей, о которых конкретно говорит пользователь: если это пицца, то «Маргарита» или «Гавайская», если карта, то какая система – MasterCard, Мир и так далее.
И, наконец, понимание тональности сообщения – в каком эмоциональном состоянии находится человек. Алгоритм должен уметь детектировать, в какой тональности написано сообщение, либо это новостной текст, либо это сообщение от человека, который общается с нашим ботом, для того чтобы адекватным образом реагировать на тональность.
Порождение текста (Natural Language Generation) – адекватная реакция на человеческий запрос таким же человеческим языком (естественным), а не сложной табличкой и не формальными фразами.
Распознавание и синтез речи (Speech-to-Text and Text-to-Speech). Если чат-бот не просто переписывается с человеком, а говорит и слушает, нужно научить его понимать устную речь, звуковые колебания преобразовывать в текст, чтобы потом модулем понимания текста этот текст анализировать, и из текста-ответа генерировать, в свою очередь, звуковые колебания, которые потом услышит человек, абонент.
Виды чат-ботов
В чат-ботах можно выделить несколько ключевых архитектур.
Чат-бот, отвечающий на наиболее часто задаваемые вопросы (FAQ-чатбот) – самый простой вариант. Мы всегда можем сформулировать набор типовых вопросов, которые задают люди. Для сайта по доставке готовой еды, как правило, это вопросы: «сколько будет стоить доставка», «доставляете ли вы в Первомайский район», и пр. Можно их сгруппировать по нескольким классам, интентам, пользовательским намерениям. И для каждого интента подобрать типовые ответы.
Целенаправленный чат-бот (goal oriented bot). Я здесь попытался показать архитектуру подобного чат-бота, который реализован в проекте iPavlov. iPavlov – это проект по созданию разговорного искусствен��ого интеллекта. В частности, целенаправленный чат-бот помогает пользователю достичь какой-то цели (например, забронировать столик в ресторане или заказать пиццу, или что-то узнать о проблемах в банке). Речь идет не просто об ответе на вопрос (вопрос-ответ – без всякого контекста). У целенаправленного чат-бота есть модуль понимания текста, управления диалогом и модуль генерации ответов.
Чат-боты вопросно-ответной системы question answering system и просто «болталки» (chit chat bot). Если два предыдущих типа чат-ботов либо отвечают на наиболее часто задаваемые вопросы, либо ведут пользователя по графу диалогов, в конце концов, помогая забронировать ресторан, выясняя, что хочет пользователь, китайскую или итальянскую кухню и т.д., то вопросно-ответная система – это другой тип чат-бота. Задача такого чат-бота – не двигаться по графу диалога и не просто классифицировать намерения пользователя, а обеспечивать информационный поиск – находить наиболее релевантный документ, соответствующий вопросу человека, и место в документе, где содержится ответ. Например, сотрудники крупного ритейлера вместо того, чтобы заучивать наизусть инструкции, регламентирующие работу, либо искать ответ, куда ставить гречку, задают вопрос такому чат-боту на основе вопросно-ответной системы.
Виды машинного обучения
Распознавание интентов, выделение именованных сущностей, поиск в документах и поиск мест в документе, которые соответствуют семантике вопроса – все это без машинного обучения, без некого статистического анализа реализовать невозможно. Поэтому в основе современных чат-ботов лежит машинное обучение –методы задач, аппроксимации некой скрытой закономерности, которая есть в больших массивах данных и выявление этих закономерностей. Такой подход имеет смысл применять, когда закономерности, задачи есть, но простую формулу, формализм для описания этой закономерности придумать невозможно.
Существует несколько видов машинного обучения: с учителем (supervised learning), без учителя (unsupervised learning), с подкреплением (reinforcement learning). Нас интересует, прежде всего, задача обучения с учителем – когда есть входные изображения и указания (метки) учителя и классификация этих изображений. Либо входные речевые сигналы и их классификация. И мы учим нашего бота, наш алгоритм воспроизводить работу учителя.
О’кей, вроде бы все круто. А как научить компьютер понимать тексты? Текст – это сложный объект, и как буквы превратить в числа и придумать векторное описание текста? Есть самый простой вариант – «мешок слов». Мы задаем словарь всей системы, например, все слова, которые есть в русском языке, и формулируем вот такие очень разреженные вектора с частотами слов. Этот вариант хорош для простых вопросов, но для более сложных задач он не годится.
В 2013 году произошла в некотором роде революция в моделировании слов и текстов. Томас Миколов предложил специальный подход эффективного векторного представления слов, основанный на дистрибутивной гипотезе. Если разные слова встречаются в одном и том же контексте, значит, они имеют что-то общее. Например: «Ученые провели анализ алгоритмов» и «Ученые провели исследование алгоритмов». Так, «Анализ» и «исследование» являются синонимами и обозначают примерно одно и то же. Поэтому можно научить специальную нейронную сеть прогнозировать слово по контексту, либо контекст по слову.
Наконец, как мы обучаем? Для того чтобы обучить бота понимать интенты, истинные намерения, нужно вручную разметить кучу текстов с помощью специальных программ. Чтобы научить бота понимать именованные сущности – имя человека, название фирмы, локация – тоже нужно размещать тексты. Соответственно, с одной стороны, алгоритм обучения с учителем наиболее эффективный, он позволяет создавать эффективную распознающую систему, но, с другой стороны, возникает проблема: нужны большие размеченные дата-сеты, а это делать дорого и долго. В процессе разметки дата-сетов могут быть ошибки, вызванные человеческим фактором.
Для решения этой проблемы в современных чат-ботах применяют так называемый перенос обучения – transfer learning. Те, кто знают много иностранных языков, наверняка замечали такой нюанс, что очередной иностранный язык учить легче, чем первый. Собственно, когда вы изучаете какую-то новую задачу, то пытаетесь использовать для этого свой прошлый опыт. Так вот, transfer learning (перенос обучения) как раз основан на этом принципе: мы обучаем алгоритм решать одну задачу, для которой у нас есть большой дата-сет. А потом этот обученный алгоритм (то есть берем алгоритм не с нуля, а обученный решению другой задачи), дообучаем решать нашу задачу. Таким образом, мы получаем эффективное решение с использованием небольших различных данных.
Одна из таких моделей – это ELMo (Embeddings from Language Models), как ELMo из Улицы Сезам. Мы используем рекуррентные нейронные сети, они имеют память и могут обрабатывать последовательности. Например: «Программист Вася любит пиво. Каждый вечер после работы он заходит в «Джонатан» и пропускает бокал-другой». Так вот, он – это кто? Он – это вечер, он – это пиво, или он – это программист Вася? Нейронная сеть, которая обрабатывает слова, как элементы последовательности, учитывая контекст, рекуррентная нейронная сеть, может понять взаимосвязи, решить эту задачу и выделить какую-то семантику.
Мы обучаем такую глубокую нейронную сеть моделировать тексты. Формально это задача обучения с учителем, но учителем у нас выступает сам неразмеченный текст. Следующее слово в тексте является учителем по отношению ко всем предыдущим. Таким образом, можем использовать гигабайты, десятки гигабайт текстов, обучать эффективные модели, которые выделяет семантика в этих текстах. И потом, когда мы используем модель Embeddings from Language Models (ELMo) в режиме вывода, мы подаем слово с учетом контекста. Не просто stick, a let's stick. Смотрим, что нейронная сеть генерирует в этот момент времени, какие сигналы. Эти сигналы мы катанируем и получаем векторное представление слова в конкретном тексте, с учетом его конкретной сематической значимости.
В анализе текстов есть еще одна особенность: когда решается задача машинного перевода, один и тот же смысл одним количеством слов на английском может быть передан и другим количеством слов на русском. Соответственно, идет не линейное сопоставление, и нам необходим механизм, который бы акцентировал внимание на тех или иных кусочках текста, чтобы адекватно их перевести на другой язык. Изначально внимание было придумано для машинного перевода – задача преобразования одного текста в другой с обычными рекуррентными нейронными системами. В это мы добавляем специальный слой внимания, который в каждый момент времени оценивает, какое слово нам сейчас важно.
Но потом ребята из Google подумали, а почему не использовать механизм внимания вообще без рекуррентных нейронных сетей – только внимание. И придумали архитектуру, которая называется трансформер (BERT (Bidirectional Encoder Representations from Transformers)).
На базе такой архитектуры, когда есть только многоголовое внимание, были придуманы специальные алгоритмы, которые тоже могут анализировать взаимосвязи слов в текстах, взаимосвязи текстов друг с другом – как это делает ELMo, только более хитро. Во-первых, это более крутая и сложная сеть. Во-вторых, мы решаем одновременно две задачи, а не одну, как в случае с ELMo – языковое моделирование, прогнозирование. Мы пытаемся восстановить скрытые слова в тексте и восстановить связи между текстами. То есть, допустим: «Программист Вася любит пиво. Каждый вечер он ходит в бар». Два текста связаны между собой. «Программист Вася любит пиво. Журавли осенью улетают на юг» – это два несвязанных текста. Опять-таки, эту информацию можно извлечь из неразмеченных текстов, обучить BERT и получить очень крутые результаты.
Об этом в ноябре прошлого года была опубликована статья «Attention Is All You Need», которую очень я очень рекомендую прочитать. На данный момент это является самым крутым результатом в области анализа текстов для решения разных задач: для классификации текста (распознавание тональности, намерений пользователя); для вопросно-ответных систем; для распознавания именованных сущностей и так далее. Современные диалоговые системы используют BERT, предобученные контекстные эмбеддинги (ELMo или BERT) для того, чтобы понять, что хочет пользователь. Но модуль управления диалогом по-прежнему часто проектируется на основе правил, потому что конкретный диалог может быть очень зависим от предмета или даже от задачи.

